reformer:the eficient transformer
论文概况
- 来源:ICLR 2020
- arXiv: 1901.02860
- 作者:Nikita Kitaev ,Anselm Levskaya
- 论文地址:https://openreview.net/forum?id=rkgNKkHtvB
- Code url:https://github.com/google/trax/tree/master/trax/models/reformer
- 论文组会报告于
2020.08.30
背景
Transformer架构被广泛用于自然语言处理中,并在许多任务上产生了最新的结果
问题
- 大型的 Transformer 可以在许多任务上实现 sota,但是面临着参数过多的问题,导致所占内存过大,造成资源紧张.
在最大的配置中,参数数量已经超过了 5亿/层,层数多达 64。
具有 N 层的模型要消耗 N 倍于单层模型的内存,因为每一层中的激活都需要存储以进行反向传播。
由于点乘注意力本身的局限性,导致不能处理长序列数据,否则会导致效率不高
也就是说transformer的上下文窗口有限制范围。最多也就几千个单词。
Transformer 的强大来源于注意力机制 ,通过这一机制,Transformer 将上下文窗口内所有可能的单词对纳入考虑,以理解它们之间的联系。因此,如果文本包含 10 万个单词,Transformer 将需要评估 100 亿单词对(10 万 x 10 万),这显然不切实际。
另一个问题是如何保存每个模型层的输出 。对于使用大型上下文窗口的应用来说,存储多个模型层输出的内存需求会迅速变得过大。这意味着,实际使用大量层的 Transformer 模型只能用于生成几小段落的文本或一小段的音乐。
解决方案
使用可逆残差(reversible residual layers)代替标准残差(standard residuals),这使得存储在训练过程中仅激活一次,而不是 n 次(此处 n 指层数),更有效地使用可用内存
将点乘注意力(dot-product attention)替换为一个使用局部敏感哈希(locality-sensitive hashing)的点乘注意力,将复杂度从 O(L2 ) 变为 O(L log L),此处 L 指序列的长度,来降低长序列的处理复杂度
Reformer与使用完全Transformer所获得的结果相匹配,但运行速度要快得多,尤其是在文本任务上,并且内存效率要高几个数量级。
注意力问题
原始注意力
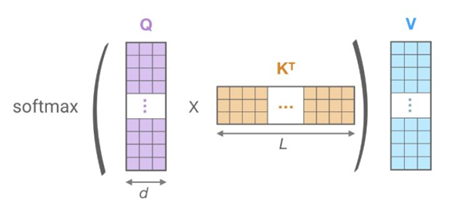
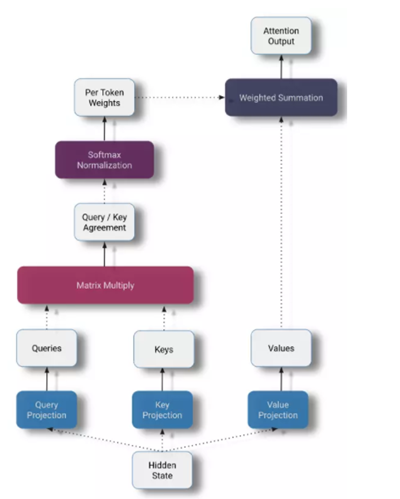
公式如下:\(Attention (Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V\)
self-attention操作的核心 ——\(QK^T\) 表示key和query之间的相似度得分
计算带有所有k的q的点积,并用√dk进行缩放,然后应用softmax函数来获得v的权重。用来消除hidden size这个参数对注意力分布的影响。对于每个query,我们在所有keys上计算一个softmax,以确保矩阵的每一行和为1—— 确保新的隐藏状态的大小不依赖于序列长度。
最后,我们用我们的注意力矩阵乘以我们的values矩阵,为每个token生成一个新的隐藏表示。
例子
Key:(batch, length,d_model)
Query:(batch, length,d_model)
-> \(QK^T\) :(batch, length,length)
-> 复杂度: O(\(L^2\) )
->原始的transformer结构难以处理过长的序列长度
其实,在softmax中,对于每个查询 q,我们只需要注意最接近 q 的键 k。并不一定需要那些注意力权重很小的token。
例如,如果序列长度是 64K,对于每个 q,我们可以只考虑 32 或 64 个最近的键的一个小子集。因为这些是和q最需要注意的
局部敏感哈希(LSH)
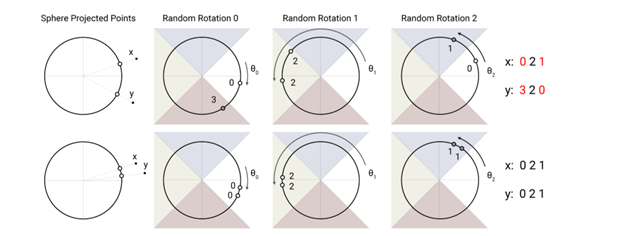
局部敏感哈希使用球形投影点的随机旋转,通过argmax在有符号轴投影上建立桶(bucket)。 在此高度简化的2D描绘中,对于三个不同的角度hash,两个点x和y不太可能共享相同的哈希桶(上方),除非它们的球面投影彼此靠近(下方)。
该图演示了一个用4个桶进行3轮哈希的设置。下面的图中的向量映射到了同一个bucket,因为它们的输入很接近,而上一张图中的向量映射到第一个和最后一个bucket。
LSH是一组将高维向量映射到一组离散值(桶/集群)的方法。是解决在高维空间中快速找到最近邻居(最相似)的问题。
基本思想:选择 hash 函数,对于两个点 p 和 q,如果 q 接近 p,那么很有可能我们有 hash(q) == hash(p)
LSH注意力
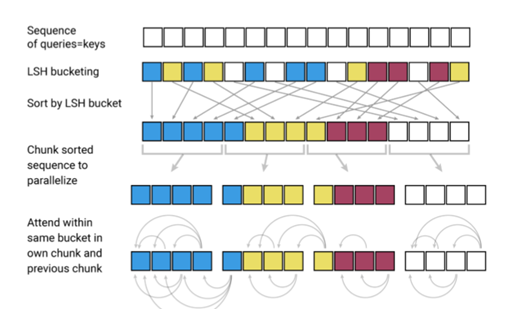
完全不同的方法来处理序列长度问题,丢弃了query投影(Q=K)(实验结果发现,学习不同的keys和queries的投影并不是严格必要的),并将注意力权重替换为key的函数(hash函数),以此降低复杂度
步骤如下:
1.使用LSH为每个token计算一个桶
2.根据相同的桶进行归类排序
3.分块并将标准的点乘注意力应用到桶中的token的块上,从而大大降低计算负载
内存问题
单层能够执行长序列的单模型。但是,当使用梯度下降训练多层模型时,由于需要保存每一层的激活(函数),以用于执行逆推。一个传统的 Transformer 模型具有十几个或更多的层,通过缓存这些层的值,内存将会很快用完。
可逆层:在反向传播时,按需重新计算每个层的输入,而不是将其保存在内存中。其中来自网络最后一层的激活用于还原来自任何中间层的激活。
原始的残差网络:\(Y=F(x)\)
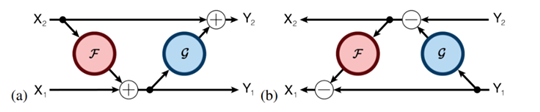
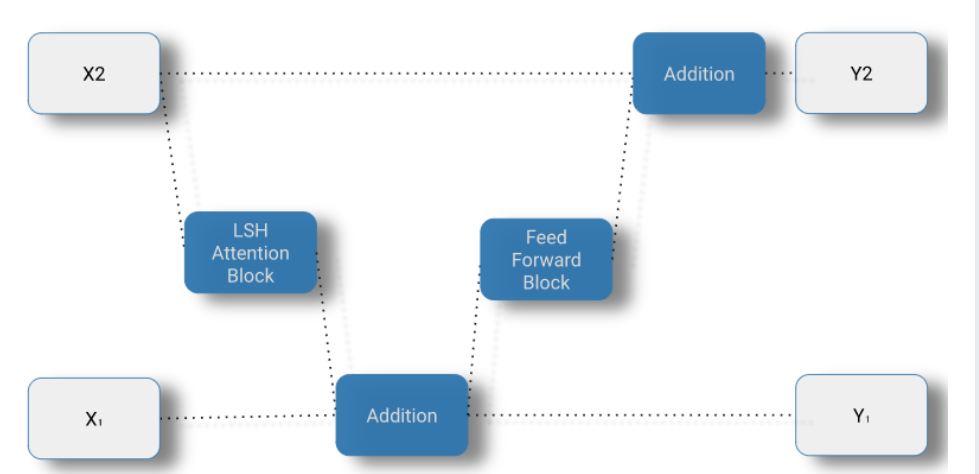
可逆层的残差网络: 注意我们如何从它的输出(Y ₁, Y ₂)计算物体的输入(X ₁, X ₂)。
\(\begin{array}{ll}y_{1}=x_{1}+F\left(x_{2}\right) & y_{2}=x_{2}+G\left(y_{1}\right) \\ x_{2}=y_{2}-G\left(y_{1}\right) & x_{1}=y_{1}-F\left(x_{2}\right) \\ Y_{1}=X_{1}+\text { Attention }\left(X_{2}\right) & Y_{2}=X_{2}+\text { FeedForward }\left(Y_{1}\right)\end{array}\)
示意图如下
实验
作者分别对图像生成任务 imagenet64(长度为 12K)和文本任务 enwik8(长度为 64K)进行了实验,评价了可逆 Transformer 和 LSH 哈希对内存、精度和速度的影响。
🎉可逆 Transformer 匹配基准:他们的实验结果表明,可逆的 Transformer 可以节省内存不牺牲精度:
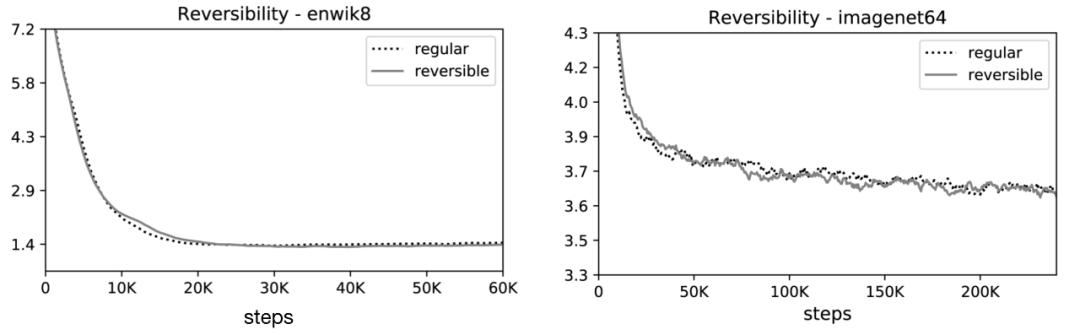
在 enwik8 和 imagenet64 训练中,可逆性对性能的影响
🎉LSH 注意力匹配基准:注意 LSH 注意力是一个近似的全注意力,其准确性随着散列值的增加而提高。当哈希值为 8 时,LSH 的注意力几乎等于完全注意力:
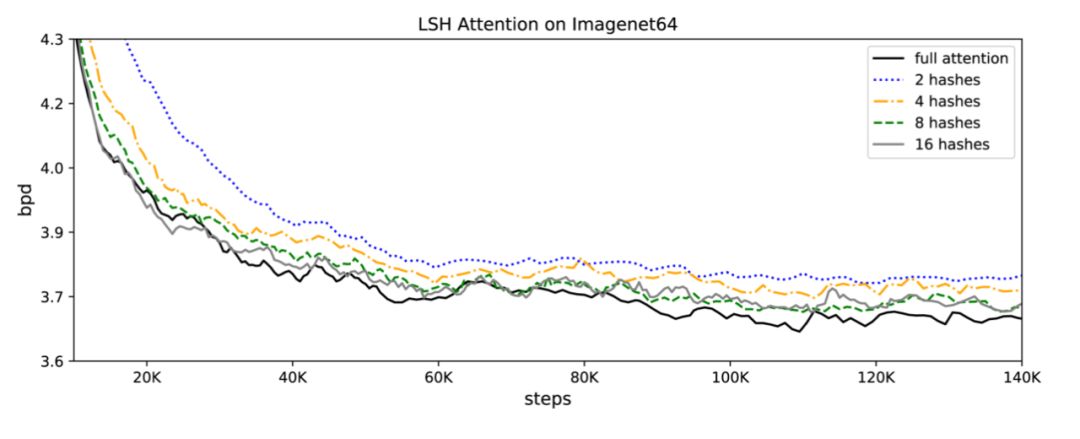
LSH 注意力作为散列循环对 imagenet64 的影响
🎉他们也证明了传统注意力的速度随着序列长度的增加而变慢,而 LSH 注意力速度保持稳定,它运行在序列长度~ 100k 在 8GB 的 GPU 上的正常速度:
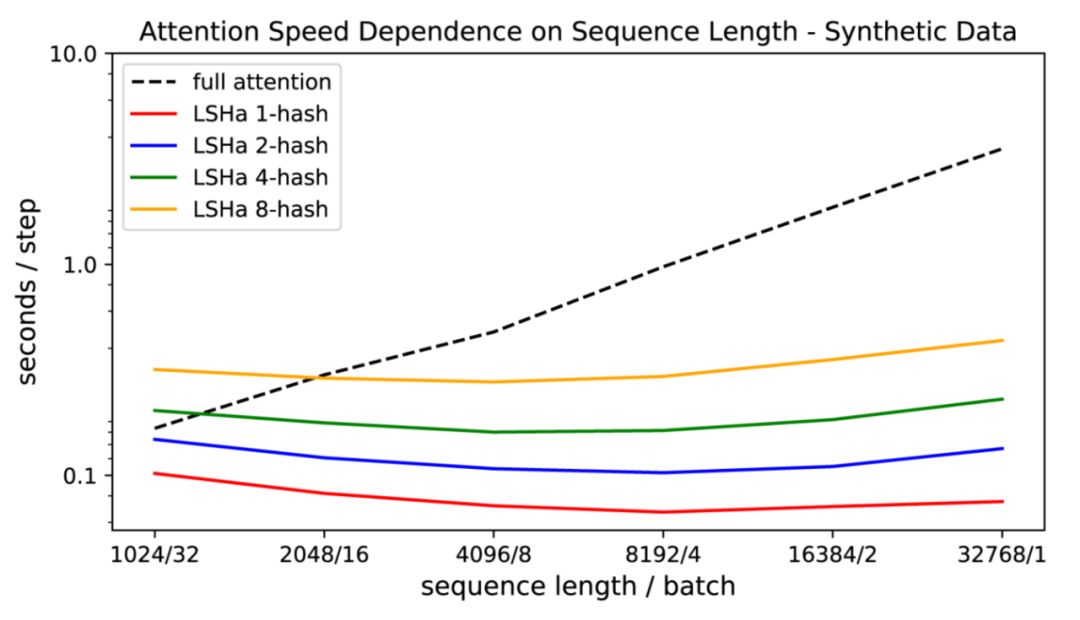
注意力评估的速度作为全注意力和 LSH 注意力的输入长度的函数
与 Transformer 模型相比,最终的 Reformer 模型具有更高的存储效率和更快的存储速度。
🚀参考
https://www.6aiq.com/article/1583729200869
Transformer-XL : Attentive Language Models Beyond a Fixed-Length Context
论文概况
- 来源:ACL 2019
- arXiv: 1901.02860
- 作者:ZihangDai , ZhilinYang , YimingYang
- 论文地址: https://arxiv.org/abs/1901.02860
- Code url:https://github.com/kimiyoung/transformer-xl
- 论文组会报告于
2020.08.15
背景
问题
Transformer存在局限性:
1.在语言建模时的设置受到固定长度(segment)的限制。对长距离依赖的建模能力仍然不足
2.因为transformer将文本等分为相同的片段,导致了上下文碎片
解决方案
使学习不再仅仅依赖于定长,且不破坏时间的相关性。
- 提出片段级递归机制(segment-level recurrence mechanism),引入一个记忆(memory)模块(类似于cache或cell) 之前计算过了不需要重复计算,直接为后面片段使用。
- 使得
长距离依赖的建模成为可能; - 使得片段之间产生交互,解决上下文碎片化问题
2.提出相对位置编码机制,代替绝对位置编码。 Transformer的绝对位置编码指的是一个片段中,为1 为2 。如果是多个片段同时考虑的话,那么这种1,2就会重复,所以使用了相对位置编码的方法。这样可以在多个片段(segment)中使用相对编码。具体内容见论文
注:两者是一起使用的,共同解决transformer存在的局限性
模型 transformer-XL
原始transformer
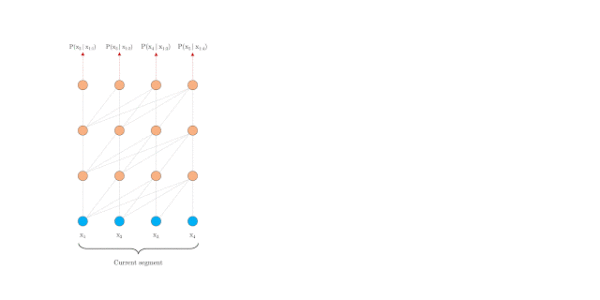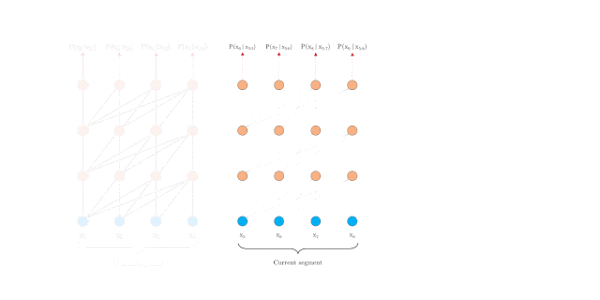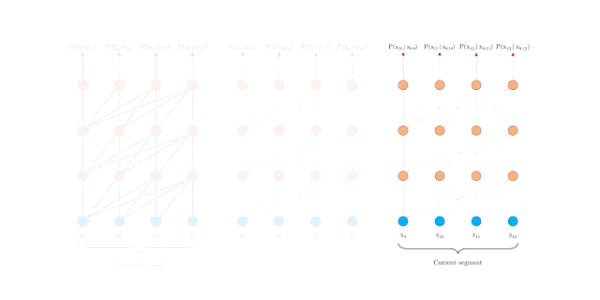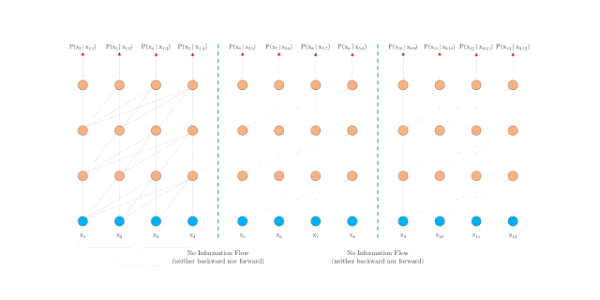
片段注意力机制
为了解决长距离依赖,文章引入一个memory状态。
在训练过程中,每个片段的表示为最后的隐层状态,表示片段的序号,表示片段的长度,表示隐层维度。
在计算片段的表示时,用memory缓存片段层的隐层状态,用来更新,这样就给下一个片段同了上文,长距离依赖也通过memory保存了下来。并且,最大可能的依赖长度线性增长,达到**N*L**
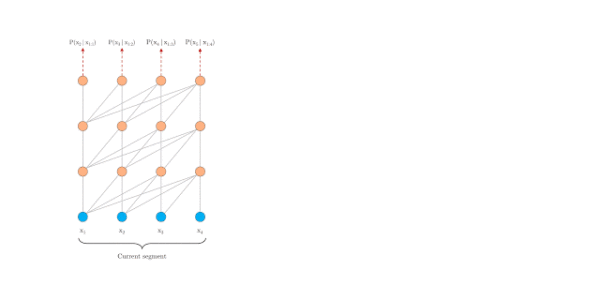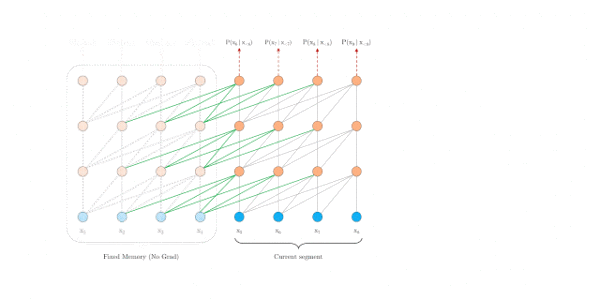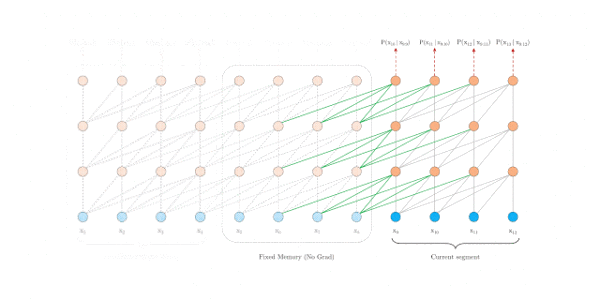
评估阶段
原始transformer
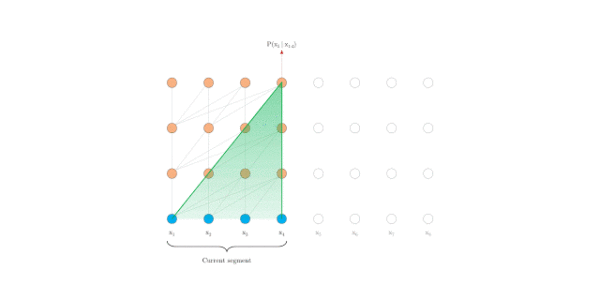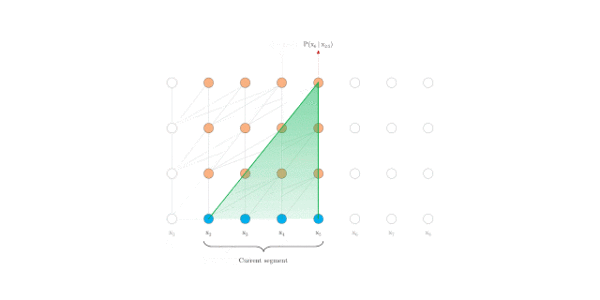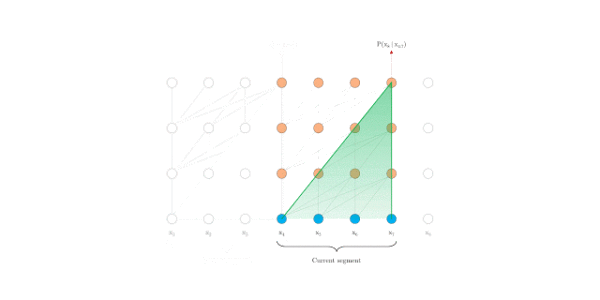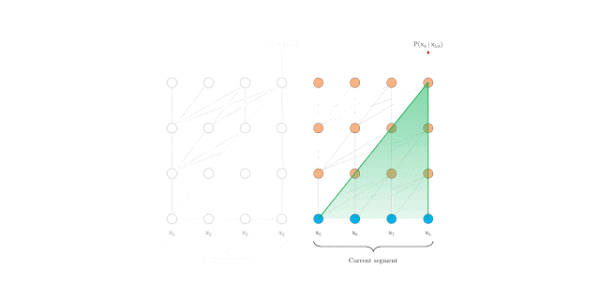
Transformer-XL
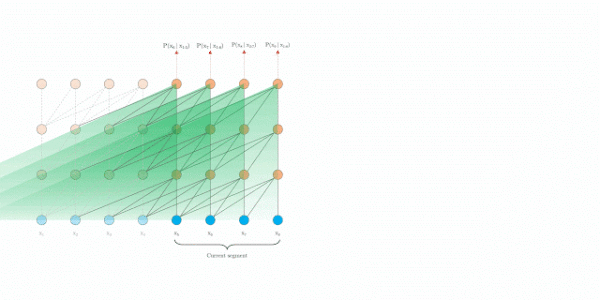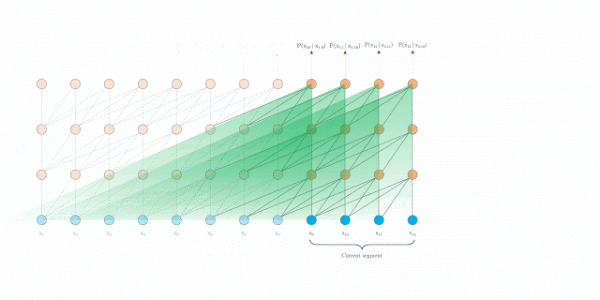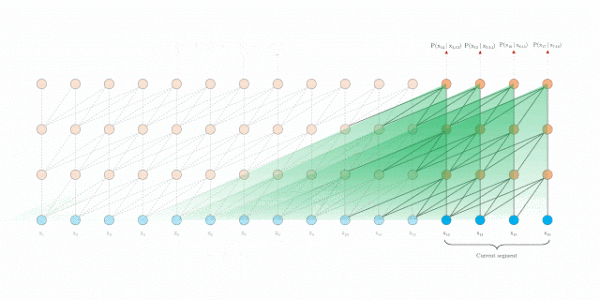
实验
实验部分是对基于Transformer-XL的语言模型进行评估,分为字符级和词级。评价指标分别是bpc(每字符位数)和PPL(困惑度),越小越好。enwiki8和text8用的是bpc。Transformer-XL在多个语言模型基准测试中实现了最先进的结果。 Transformer-XL第一个在char级语言模型基准enwiki8上突破1.0。
去除实验:
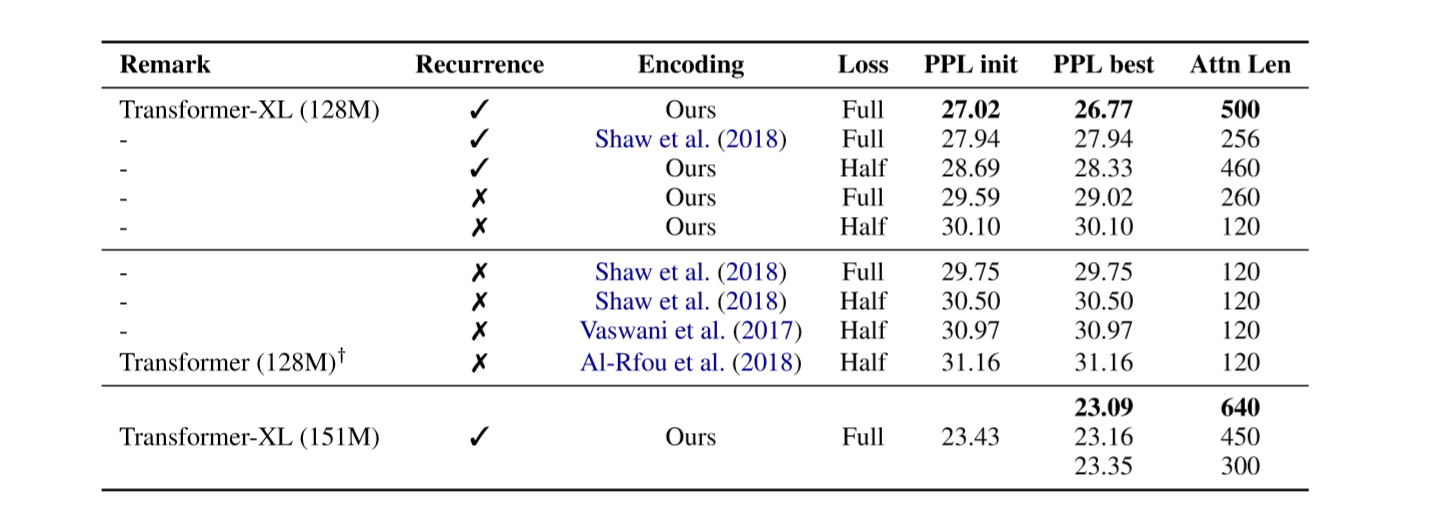
重点是本文设计的相对位置编码优于其他工作,memory的设计也有很大的提升。
最后,Transformer-XL在评估阶段的速度也明显快于 vanilla Transformer,特别是对于较长的上下文。例如,对于 800 个字符的上下文长度,Transformer-XL 比Vanilla Transformer 快 363 倍;而对于 3800 字符的上下文,Transformer-XL 快了 1874 倍。
创新点
- 提出了片段级递归机制和相对位置编码机制
- 依赖关系比原始Transformer长450%,并且在评估过程中,其速度比原始Transformer快1800倍以上
🚀参考
https://www.cnblogs.com/shona/p/12041055.html
https://zhuanlan.zhihu.com/p/83062195
