前言
BERT是谷歌发布的基于双向 Transformer的大规模预训练语言模型,该预训练模型能高效抽取文本信息并应用于各种NLP任务,并刷新了 11 项 NLP 任务的当前最优性能记录。
BERT的全称是基于Transformer的双向编码器表征,其中“双向”表示模型在处理某一个词时,它能同时利用前面的词和后面的词两部分信息。
BERT的本质上是通过在海量的语料的基础上运行自监督学习方法为单词学习一个好的特征表示,所谓自监督学习是指在没有人工标注的数据上运行的监督学习。
在以后特定的NLP任务中,我们可以直接使用BERT的特征表示作为该任务的词嵌入特征。所以BERT提供的是一个供其它任务迁移学习的模型,该模型可以根据任务微调或者固定之后作为特征提取器。
BERT仍然使用的是Transformer模型,它pretraining的不是普通的语言模型,而是Mask语言模型。在介绍Mask语言模型之前我们先介绍BERT的输入表示。
BERT的总体结构
如图2-1,是Devlin等人在论文中给出的BERT结构示意图。BERT的输入是token序列对应的嵌入向量序列。在生命周期的不同阶段,输出是不同的:
在预训练阶段,BERT采用多任务策略,输出包括“下一个词语”和“是否为下一句”。
在微调和推断阶段,BERT(针对具体的任务)输出NER标签、答案位置等等。
这个示意图非常概括,BERT内部细节比较模糊。后面进行更详细的介绍。
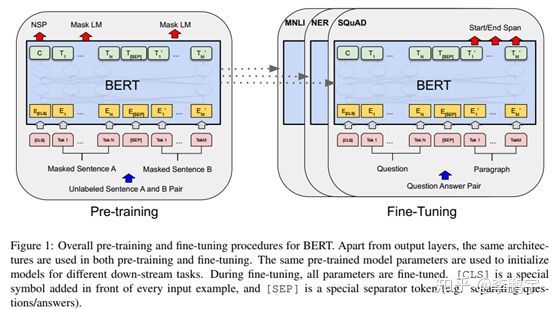
图 2-1 《BERT》中提供的BERT结构原图
输入表示
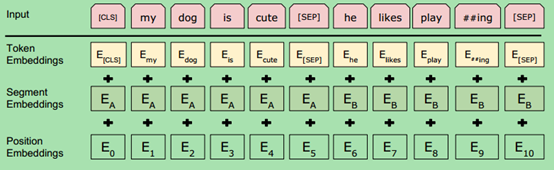
BERT的输入的编码向量(长度是512)是3个嵌入特征的单位和,如图4,这三个词嵌入特征是:
- WordPiece 嵌入[6]:WordPiece是指将单词划分成一组有限的公共子词单元,能在单词的有效性和字符的灵活性之间取得一个折中的平衡。例如图4的示例中‘playing’被拆分成了‘play’和‘ing’;
- 位置嵌入(Position Embedding):位置嵌入是指将单词的位置信息编码成特征向量,位置嵌入是向模型中引入单词位置关系的至关重要的一环。位置嵌入的具体内容参考我之前的分析;
- 分割嵌入(Segment Embedding):用于区分两个句子,例如B是否是A的下文(对话场景,问答场景等)。对于句子对,第一个句子的特征值是0,第二个句子的特征值是1。
最后,说明一下图4中的两个特殊符号[CLS]和[SEP],其中[CLS]表示该特征用于分类模型,对非分类模型,该符合可以省去。[SEP]表示分句符号,用于断开输入语料中的两个句子。
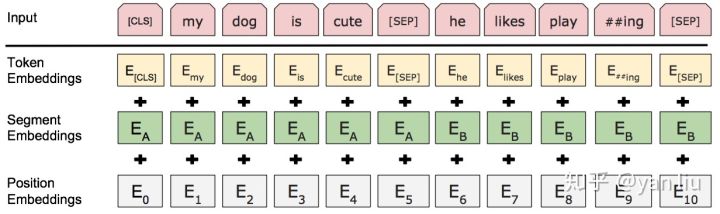
对于情感分类这样的任务,只有一个句子,因此Segment id总是0;而对于Entailment任务,输入是两个句子,因此Segment是0或者1。
BERT模型要求有一个固定的Sequence的长度,比如128。如果不够就在后面padding,否则就截取掉多余的Token,从而保证输入是一个固定长度的Token序列,后面的代码会详细的介绍。第一个Token总是特殊的[CLS],它本身没有任何语义,因此它会(必须)编码整个句子(其它词)的语义。
Mask LM
为了解决只能利用单向信息的问题,BERT使用的是Mask语言模型而不是普通的语言模型。Mask语言模型有点类似与完形填空——给定一个句子,把其中某个词遮挡起来,让人猜测可能的词。
这里会随机的Mask掉15%的词,然后让BERT来预测这些Mask的词,通过调整模型的参数使得模型预测正确的概率尽可能大,这等价于交叉熵的损失函数。这样的Transformer在编码一个词的时候会(必须)参考上下文的信息。
但是这有一个问题:在Pretraining Mask LM时会出现特殊的Token [MASK],但是在后面的fine-tuning时却不会出现,这会出现Mismatch的问题。
因此BERT中,如果某个Token在被选中的15%个Token里,则按照下面的方式随机的执行:
80%的概率替换成[MASK],比如my dog is hairy → my dog is [MASK]
10%的概率替换成随机的一个词,比如my dog is hairy → my dog is apple
10%的概率替换成它本身,比如my dog is hairy → my dog is hairy
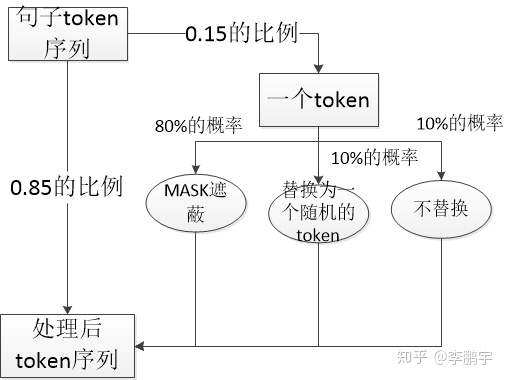
这样做的好处是,BERT并不知道[MASK]替换的是哪一个词,而且任何一个词都有可能是被替换掉的,比如它看到的apple可能是被替换的词。这样强迫模型在编码当前时刻的时候不能太依赖于当前的词,而要考虑它的上下文,甚至更加上下文进行”纠错”。比如上面的例子模型在编码apple是根据上下文my dog is应该把apple(部分)编码成hairy的语义而不是apple的语义。
预测句子关系
在有些任务中,比如问答,前后两个句子有一定的关联关系,我们希望BERT Pretraining的模型能够学习到这种关系。因此BERT还增加了一个新的任务——预测两个句子是否有关联关系。这是一种Multi-Task Learing。BERT要求的Pretraining的数据是一个一个的”文章”,比如它使用了BookCorpus和维基百科的数据,BookCorpus是很多本书,每本书的前后句子是有关联关系的;而维基百科的文章的前后句子也是有关系的。对于这个任务,BERT会以50%的概率抽取有关联的句子(注意这里的句子实际只是联系的Token序列,不是语言学意义上的句子),另外以50%的概率随机抽取两个无关的句子,然后让BERT模型来判断这两个句子是否相关。比如下面的两个相关的句子:
1 | [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP] |
下面是两个不相关的句子:
1 | [CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP] |
Fine-Tuning
BERT的Fine-Tuning如下图所示,共分为4类任务。
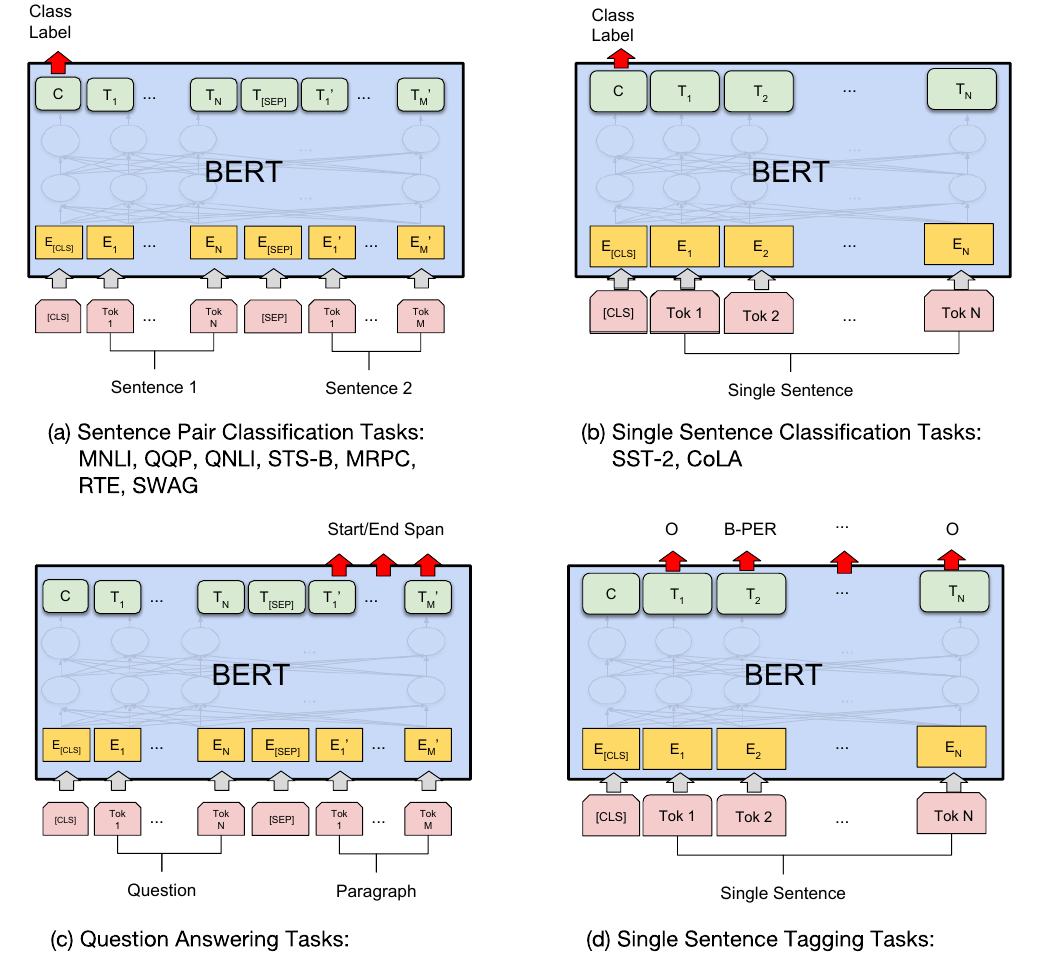 图:BERT的Fine-Tuning
图:BERT的Fine-Tuning
对于普通的分类任务,输入是一个序列,如图中右上所示,所有的Token都是属于同一个Segment(Id=0),我们用第一个特殊Token [CLS]的最后一层输出接上softmax进行分类,用分类的数据来进行Fine-Tuning。
对于相似度计算等输入为两个序列的任务,过程如图左上所示。两个序列的Token对应不同的Segment(Id=0/1)。我们也是用第一个特殊Token [CLS]的最后一层输出接上softmax进行分类,然后用分类数据进行Fine-Tuning。
第三类任务是序列标注,比如命名实体识别,输入是一个句子(Token序列),除了[CLS]和[SEP]的每个时刻都会有输出的Tag,比如B-PER表示人名的开始,本章的序列标注部分已经介绍过怎么把NER变成序列标注的问题了,这里不再赘述。然后用输出的Tag来进行Fine-Tuning,过程如图右下所示。
第四类是问答类问题,比如SQuAD v1.1数据集,输入是一个问题和一段很长的包含答案的文字(Paragraph),输出在这段文字里找到问题的答案。
比如输入的问题是:
1 | Where do water droplets collide with ice crystals to form precipitation? |
包含答案的文字是:
1 | ... Precipitation forms as smaller droplets coalesce via collision with other rain drops or ice crystals within a cloud. ... |
正确答案是”within a cloud”。
论文中作者提到了另外的两个模型,分别是OpenAI GPT和ELMo。
图3展示了这3个模型架构的对比:
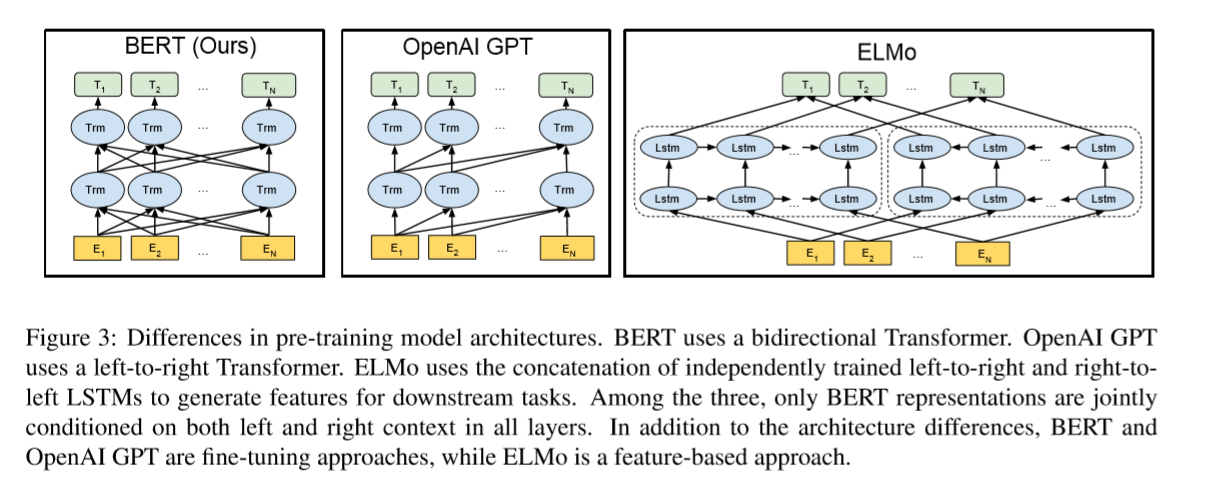
- BERT使用了双向的Transformer架构,预训练阶段使用了MLM和NSP。
- OpenAI GPT使用了left-to-right的Transformer。
- ELMo分别使用了left-to-right和right-to-left进行独立训练,然后将输出拼接起来,为下游任务提供序列特征。
上面的三个模型架构中,只有BERT模型的表征在每一层都联合考虑到了左边和右边的上下文信息。另外,除了架构不同,还要说明的一点是:BERT和OpenAI GPT是基于fine-tuning的方法,而ELMo是基于feature-based的方法。
其它
[CLS]就是classification的意思,可以理解为用于下游的分类任务。
主要用于以下两种任务:
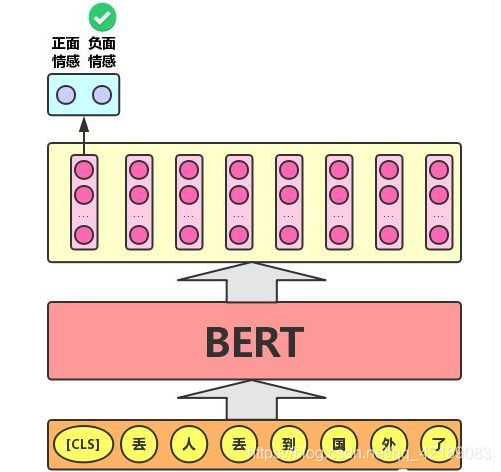
- 单文本分类任务:对于文本分类任务,BERT模型在文本前插入一个[CLS]符号,并将该符号对应的输出向量作为整篇文本的语义表示,用于文本分类,如下图所示。可以理解为:与文本中已有的其它字/词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个字/词的语义信息。
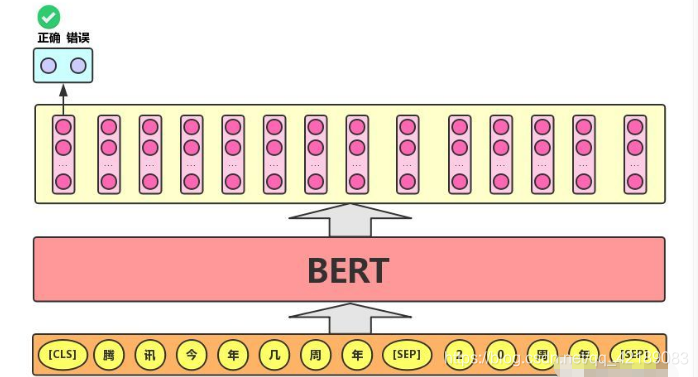
- 语句对分类任务:该任务的实际应用场景包括:问答(判断一个问题与一个答案是否匹配)、语句匹配(两句话是否表达同一个意思)等。对于该任务,BERT模型除了添加[CLS]符号并将对应的输出作为文本的语义表示,还对输入的两句话用一个[SEP]符号作分割,并分别对两句话附加两个不同的文本向量以作区分,如下图所示。
模型架构
输入表示
我们的输入表示能够在一个标记序列中明确地表示单个文本句子或一对文本句子(例如,[问题,答案])。一个词的输入=词的embeding+段embeding+位置embeding
对于词embeding论文使用WordPiece embeddings
每个序列的第一个字符始终是特殊分类embedding([CLS])。对应于该字符的最终隐藏状态(即,Transformer的输出)被视为整个序列表示常用于聚合用作分类任务。对于非分类任务,将忽略此向量。
预训练
- 任务一:Masked LM
- 标准条件语言模型只能从左到右或从右到左进行训练,因为双向条件语言模型将允许每个单词在多层self-attention中间接看到自己。为了避免当前要预测的词在self-attention中看到要预测的答案我们采样的方法是:随机屏蔽掉(mask)输入序列中一定比例的输入词,然后仅预测那些被屏蔽的词,称这个方法叫masked LM(MLM),最后我们将这个被mask的词的最后隐藏层输出,输入到softmax层中预测这个被mask的词
- 在论文的实验中我们每次mask掉一个序列的15%词
- 该任务的两个缺点:
- 第一个:这种操作使得预训练和微调之间不匹配,因为在微调期间可能没有[MASK]字符。为了缓解这种情况我们不总是用[MASK]词来替换被mask掉的词,而是80%的用[MASK]词来替换被mask掉的词,10%用一个随机词来替换被mask掉的词,再,10%保存源词不变。例子:
- 原句:my dog is hairy 我们要mask掉hairy
- 80%:my dog is [MASK]
- 10%:my dog is apple
- 10%:my dog is hairy
- 第二个:每个batch中只预测了15%的词,这表明模型可能需要更多的预训练步骤才能收敛。实验证明该任务的训练略微慢一点比起预测每一个词的语言模型。
- 第一个:这种操作使得预训练和微调之间不匹配,因为在微调期间可能没有[MASK]字符。为了缓解这种情况我们不总是用[MASK]词来替换被mask掉的词,而是80%的用[MASK]词来替换被mask掉的词,10%用一个随机词来替换被mask掉的词,再,10%保存源词不变。例子:
- 任务二:Next Sentence Prediction
- 为了训练理解句子关系的模型,我们预先训练下一句话预测任务,该任务可以从任何单语言语料库中生成。具体地,在构建每个预训练样本时,选择句子A和B,50%B是A的实际下一句子, 50%B是来自语料库的一个随机句子,例子如下:
- Input = [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP]
- Label = IsNext
- Input = [CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
- Label = NotNext
- 为了训练理解句子关系的模型,我们预先训练下一句话预测任务,该任务可以从任何单语言语料库中生成。具体地,在构建每个预训练样本时,选择句子A和B,50%B是A的实际下一句子, 50%B是来自语料库的一个随机句子,例子如下:
- 预训练过程设置:
- 输入序列长度为512,batch_size=256,训练1000000步近似在33亿词的预料库上40 epochs
- 使用Adam优化器,learning_rate=1e-4, β_1= 0.9, β_2= 0.999,权重的L2正则项系数为0.01,学习率是预热步数:10000,学习率线性衰退,在每一层使用概率为0.1的dropout,激活函数使用gelu
微调
对于序列水平的分类任务,我们获取第一个词[CLS]的最后隐藏层状态,再将C经过一个全连接层得到最后的预测分布,其中K是类别数。W也是这种特殊任务唯一添加的模型参数。
在微调的过程中BERT和W被同时微调。
在微调中,大多数模型超参数与预训练相同,一般修改的超参数是:batch_size, learning_rate, epochs。 Dropout的概率始终保持在0.1。理论上说最佳超参数值随特定于任务不同而不同,但我们发现以下范围的可能值可以在所有任务中很好地工作:
- Batch size: 16, 32
- Learning rate (Adam): 5e-5, 3e-5, 2e-5
- Number of epochs: 3, 4
我们还观察到,大数据集对超参数选择的敏感性远小于小数据集
微调总结图:
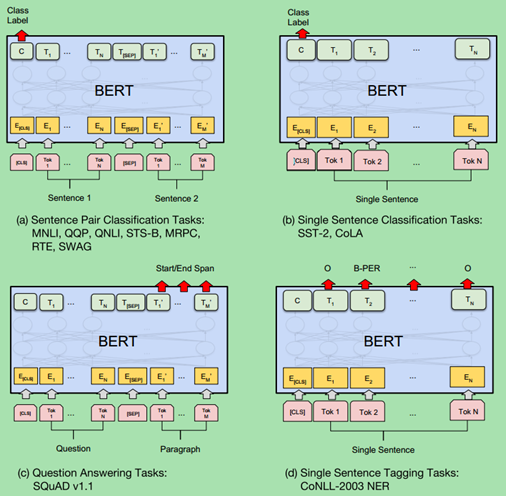
图一:预测两个句子的关系,图二:是对当个句子分类。
模型对比
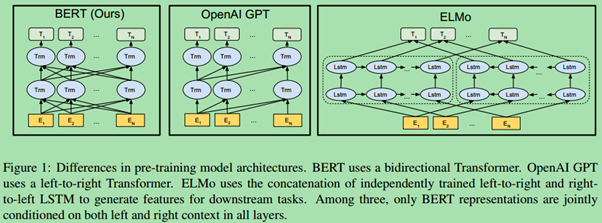
总结
词嵌入语言模型的方法
NLP词嵌入语言模型的方法:
Feature-based方法
Feature-based指利用预先训练好的语言模型的结果,作为当前特定任务模型(task-specific)的一个额外的特征引入到当前特定任务模型中,例如下图的语言模型
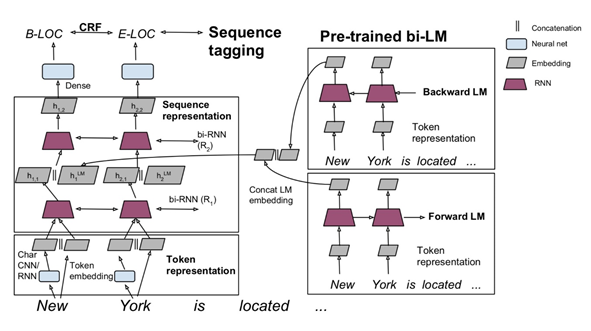
上图中,左边部分为序列标注模型,也就是task-specific model,每个任务可能不同,右边是两个预训练好的前向LM(Left-to-right)和后向LM(Right-To-Left), 将两个LM的结果进行了合并,并将LM embedding与词向量、第一层RNN输出、第二层RNN输出进行了concat操作
通常feature-based方法包括两步:
- 首先在大的语料A上无监督地训练语言模型,训练完毕得到语言模型。
- 然后构造task-specific model例如序列标注模型,采用有label的语料B来有监地训练task-sepcific model,将语言模型的参数固定,语料B的训练数据经过语言模型得到LM embedding,作为task-specific model的额外特征
ELMo是这方面的典型代表
Fine-tuning方法
Fine-tuning方式是指在已经训练好的语言模型的基础上,加入少量的task-specific parameters, 例如对于分类问题在语言模型基础上加一层softmax网络,然后在新的语料上重新训练来进行fine-tune。
OpenAI GPT 是这一方法的典型代表,其模型如下所示:
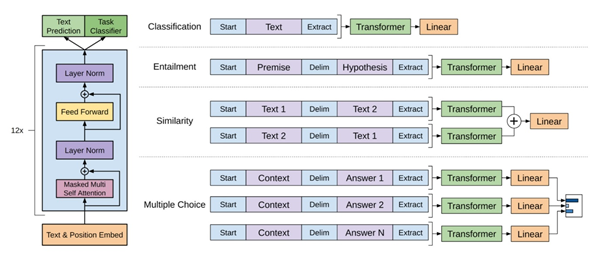
GPT首先语言模型采用了Transformer Decoder的方法来进行训练,采用文本预测作为语言模型训练任务,训练完毕之后,加一层Linear Project来完成分类/相似度计算等NLP任务。
Fine-Tuning的方法工作包括两步:
- 构造语言模型,采用大的语料A来训练语言模型
- 在语言模型基础上增加少量神经网络层来完成specific task model例如序列标注、分类等,然后采用有label的语料B来有监督地训练模型,这个过程中语言模型的参数并不固定.
而BERT采用了fine-tuning的方法,并且在许多task-specific model中取得了最好的效果
