🚀Transformer家族1 -- Transformer详解和源码分析
1 Transformer总体结构
近几年NLP领域有了突飞猛进的发展,预训练模型功不可没。当前利用预训练模型(pretrain models)在下游任务中进行fine-tune,已经成为了大部分NLP任务的固定范式。Transformer摒弃了RNN的序列结构,完全采用attention和全连接,严格来说不属于预训练模型。但它却是当前几乎所有pretrain models的基本结构,为pretrain models打下了坚实的基础,并逐步发展出了transformer-XL,reformer等优化架构。本文结合论文和源码,对transformer基本结构,进行详细分析。
Transformer是谷歌在2017年6月提出,发表在NIPS2017上。论文地址 Attention Is All You Need。 分析的代码为Harvardnlp的代码,基于PyTorch, 地址 annotated-transformer
Transformer主体框架是一个encoder-decoder结构,去掉了RNN序列结构,完全基于attention和全连接。在WMT2014英语翻译德语任务上,bleu值达到了28.4,达到当时的SOTA。其总体结构如下所示
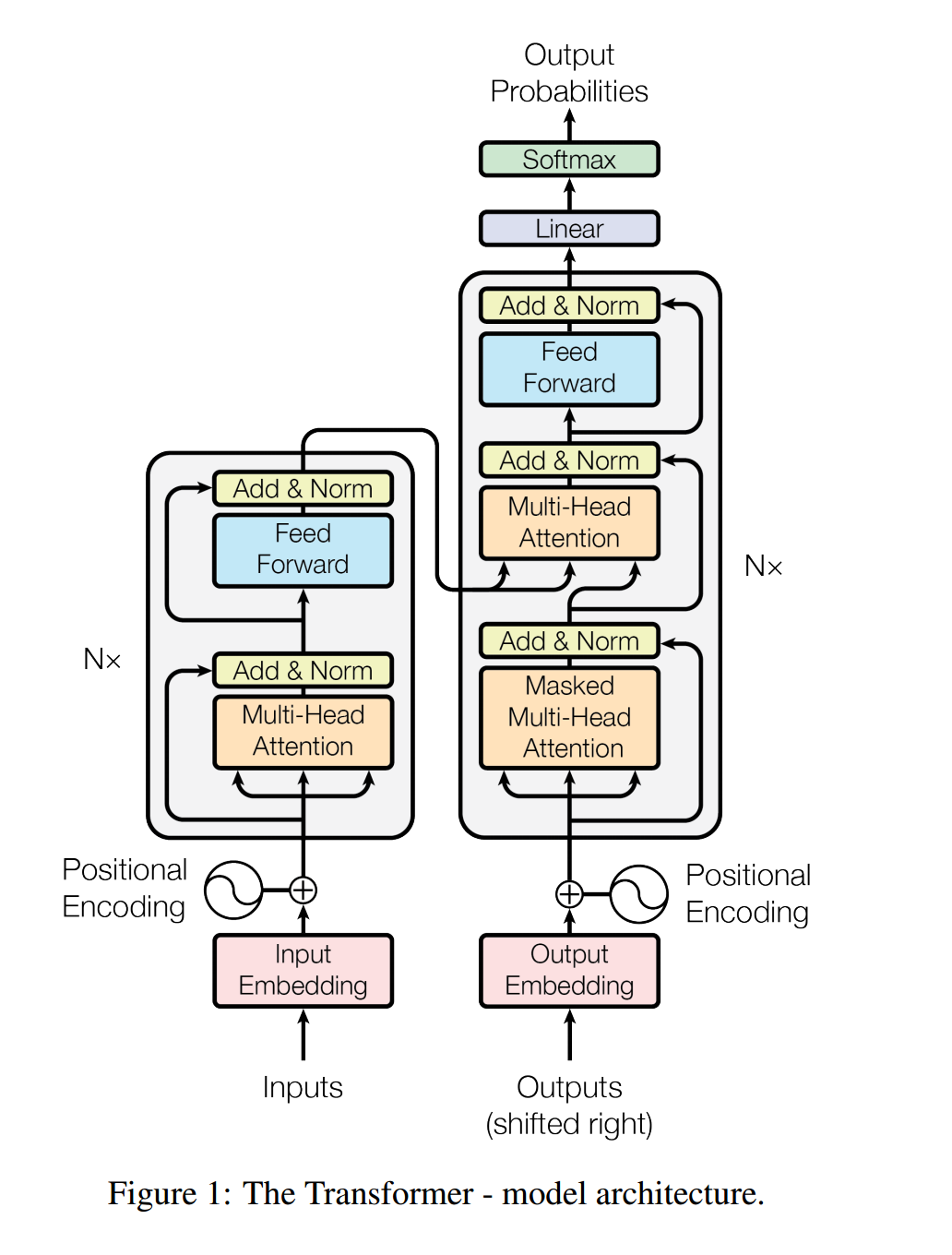
总体为一个典型的encoder-decoder结构。代码如下
1 | # 整个模型入口 |
make_model为Transformer模型定义的入口,它先定义了multi-head attention、feed-forward、position-encoding等一系列子模块,然后定义了一个encoder-decoder结构并返回。下面来看encoder-decoder定义。
1 | class EncoderDecoder(nn.Module): |
encoder-decoder定义了一个标准的编码解码框架,其中编码器、解码器均可以自定义,有很强的泛化能力。模块运行时会调用forward函数,它先对输入进行encode,然后再通过decode输出。我们就不详细展开了。
2 encoder
2.1 encoder定义
encoder分为两部分
- 输入层embedding。输入层对inputs文本做token embedding,并对每个字做position encoding,然后叠加在一起,作为最终的输入。
- 编码层encoding。编码层是多层结构相同的layer堆叠而成。每个layer又包括两部分,multi-head self-attention和feed-forward全连接,并在每部分加入了残差连接和归一化。
代码实现上也验证了这一点。我们看EncoderDecoder类中的encode函数,它先利用输入embedding层对原始输入进行embedding,然后再通过编码层进行encoding。
1 | class EncoderDecoder(nn.Module): |
2.2 输入层embedding
原始文本经过embedding层进行向量化,它包括token embedding和position embedding两层。
2.2.1 token embedding
token embedding对文本进行向量化,一般来说有两种方式
- 采用固定词向量,比如利用Word2vec预先训练好的。这种方式是LSTM时代常用的方式,比较简单省事,无需训练。但由于词向量是固定的,不能解决一词多义的问题,词语本身也不是contextual的,没有结合上下文语境信息,另外对于不在词向量中的词语,比如特定领域词语或者新词,容易出现OOV问题。
- 随机初始化,然后训练。这种方式比较麻烦,需要大规模训练语料,但能解决固定词向量的一系列问题。Transformer采用了这种方式。
另外,基于Transformer的BERT模型在中文处理时,直接基于字做embedding,优点有
- 无需分词,故不会引入分词误差。事实上,只要训练语料充分,模型自然就可以学到分词信息了。
- 中文字个数固定,不会导致OOV问题
- 中文字相对词,数量少很多,embedding层参数大大缩小,减小了模型体积,并加快了训练速度。
事实上,就算在LSTM时代,很多case中,我们也碰到过基于字的embedding的效果比基于词的要好一些。
1 | class Embeddings(nn.Module): |
由代码可见,Transformer采用的是随机初始化,然后训练的方式。词向量维度为[vocab_size, d_model]。例如BERT中为[21128, 768],参数量还是很大的。ALBert针对embedding层进行矩阵分解,大大减小了embedding层体积。
2.2.2 position encoding
首先一个问题,为啥要进行位置编码呢。原因在于self-attention,将任意两个字之间距离缩小为1,丢失了字的位置信息,故我们需要加上这一信息。我们也可以想到两种方法
- 固定编码。Transformer采用了这一方式,通过奇数列cos函数,偶数列sin函数方式,利用三角函数对位置进行固定编码。
- 动态训练。BERT采用了这种方式。先随机初始化一个embedding table,然后训练得到table 参数值。predict时通过embedding_lookup找到每个位置的embedding。这种方式和token embedding类似。
哪一种方法好呢?个人以为各有利弊
- 固定编码方式简洁,不需要训练。且不受embedding table维度影响,理论上可以支持任意长度文本。(但要尽量避免预测文本很长,但训练集文本较短的case)
- 动态训练方式,在语料比较大时,准确度比较好。但需要训练,且最致命的是,限制了输入文本长度。当文本长度大于position embedding table维度时,超出的position无法查表得到embedding(可以理解为OOV了)。这也是为什么BERT模型文本长度最大512的原因。
1 | class PositionalEncoding(nn.Module): |
由代码可见,position encoding直接采用了三角函数。对偶数列采用sin,奇数列采用cos。 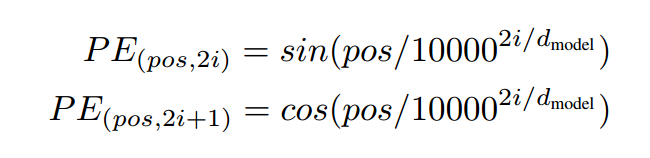
2.3 编码层
Encoder层是Transformer的核心,它由N层相同结构的layer(默认6层)堆叠而成。
1 | class Encoder(nn.Module): |
encoder的定义很简洁。先经过N层相同结构的layer,然后再进行归一化输出。重点我们来看layer的定义。
1 | class EncoderLayer(nn.Module): |
encoder layer分为两个子模块
- self attention, 并对输入attention前的和经过attention输出的,做残差连接。残差连接先经过layer-norm归一化,然后进行dropout,最后再做add。后面我们详细分析
- feed-forward全连接,也有残差连接的存在,方式和self attention相同。
2.3.1 MultiHeadedAttention
MultiHeaded Attention采用多头self-attention。它先将隐向量切分为h个头,然后每个头内部进行self-attention计算,最后再concat再一起。
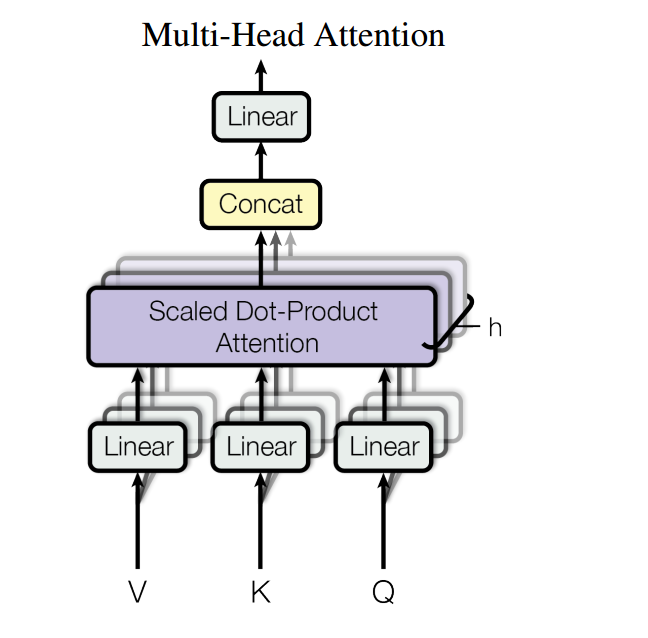 代码如下
代码如下
1 | class MultiHeadedAttention(nn.Module): |
下面重点来看单个头的self-attention。也就是论文中的“Scaled Dot-Product Attention”。attention本质上是一个向量的加权求和。它探讨的是每个位置对当前位置的贡献。步骤如下
- q向量和每个位置的k向量计算点积,然后除以向量长度的根号。计算点积可以认为是进行权重计算。除以向量长度原因是向量越长,q*k值理论上会越大,故需要在向量长度上做归一化。
- attention-mask。mask和输入矩阵shape相同,mask矩阵中值为0位置对应的输入矩阵的值更改为-1e9,一个非常非常小的数,经过softmax后趋近于0。decoder中使用了mask,后面我们详细分析。
- softmax归一化,使得q向量和每个位置的k向量的score分布到(0, 1)之间
- 加权系数乘以每个位置v向量,然后加起来。
公式如下: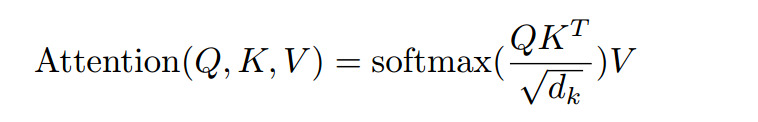 代码如下
代码如下
1 | def attention(query, key, value, mask=None, dropout=None): |
self-attention和soft-attention共用了这个函数,他们之间的唯一区别是q k v向量的来源不同。self-attention中q k v 均来自同一文本。而decoder的soft-attention,q来自于decoder,k和v来自于encoder。它体现的是encoder对decoder的加权贡献。
2.3.2 PositionwiseFeedForward
feed-forward本质是一个两层的全连接,全连接之间加入了relu非线性和dropout。比较简单,代码如下
1 | class PositionwiseFeedForward(nn.Module): |
总体过程是:全连接1 -> relu -> dropout -> 全连接2。两层全连接内部没有shortcut,这儿不要搞混了。
2.3.3 SublayerConnection
在每层的self-attention和feed-forward模块中,均应用了残差连接。残差连接先对输入进行layerNorm归一化,然后送入attention或feed-forward模块,然后经过dropout,最后再和原始输入相加。这样做的好处是,让每一层attention和feed-forward模块的输入值,均是经过归一化的,保持在一个量级上,从而可以加快收敛速度。
1 | class SublayerConnection(nn.Module): |
从forward函数可见,先对输入进行layer-norm, 然后经过attention等相关模块,再经过dropout,最后再和输入相加。残差连接的作用就不说了,参考ResNet。
3 decoder
decoder结构和encoder大体相同,也是堆叠了N层相同结构的layer(默认6层)。不同的是,decoder的每个子层包括三层。
- masked multi-head self-attention。这一部分和encoder基本相同,区别在于decoder为了保证模型不能看见要预测字的后面位置的字,加入了mask,从而避免未来信息的穿越问题。mask为一个上三角矩阵,上三角全为1,下三角和对角线全为0
- multi-head soft-attention。soft-attention和self-attention结构基本相同,甚至实现函数都是同一个。唯一的区别在于,self-attention的q k v矩阵来自同一个,所以叫self-attention。而soft-attention的q来自decoder,k和v来自encoder。表征的是encoder的整体输出对于decoder的贡献。
- feed-forward。这一块基本相同。
另外三个模块均使用了残差连接,步骤仍然为 layerNorm -> attention等模块 -> dropout -> 和输入进行add
decoder每个layer代码如下
1 | class DecoderLayer(nn.Module): |
4 输出层
decoder的输出作为最终输出层的输入,经过两步
- linear线性连接,也即是w * x + b
- softmax归一化,向量长度等于vocabulary的长度,得到vocabulary中每个字的概率。利用beam-search等方法,即可得到生成结果。
这一层比较简单,代码如下
1 | class Generator(nn.Module): |
5 总结
Transformer相比LSTM的优点
- 完全的并行计算,Transformer的attention和feed-forward,均可以并行计算。而LSTM则依赖上一时刻,必须串行
- 减少长程依赖,利用self-attention将每个字之间距离缩短为1,大大缓解了长距离依赖问题
- 提高网络深度。由于大大缓解了长程依赖梯度衰减问题,Transformer网络可以很深,基于Transformer的BERT甚至可以做到24层。而LSTM一般只有2层或者4层。网络越深,高阶特征捕获能力越好,模型performance也可以越高。
- 真正的双向网络。Transformer可以同时融合前后位置的信息,而双向LSTM只是简单的将两个方向的结果相加,严格来说仍然是单向的。
- 可解释性强。完全基于attention的Transformer,可以表达字与字之间的相关关系,可解释性更强。
Transformer也不是一定就比LSTM好,它的缺点如下
- 文本长度很长时,比如篇章级别,计算量爆炸。self-attention的计算量为O(n^2), n为文本长度。Transformer-xl利用层级方式,将计算速度提升了1800倍
- Transformer位置信息只靠position encoding,效果比较一般。当语句较短时,比如小于10个字,Transformer效果不一定比LSTM好
- Transformer参数量较大,在大规模数据集上,效果远好于LSTM。但在小规模数据集上,如果不是利用pretrain models,效果不一定有LSTM好。
🚀Transformer家族2 -- 编码长度优化(Transformer-XL、Longformer)
1 背景
NLP中经常出现长程依赖问题,比如一个词语可能和它距离上千位置的另一个词语有关系。长程关系的建立十分困难。常见序列结构模型都有一些难点,如下。
- 在RNN中,由于反向传播梯度衰减和梯度爆炸问题,使得模型只能捕获较短距离。
- LSTM利用门限机制,将连乘转变了为连加,提升了模型长程捕获能力,但梯度弥散问题没有从根本上得到解决,故其最大程度只能在400左右。
- Transformer利用self-attention机制进行建模,使得任何两个位置token距离都为1。如果没有内存和算力的限制,Transformer理论上可以编码无限长的文本。但由于attention计算量十分大,而且计算复杂度和序列长度为O(n^2)关系,导致序列长度增加,内存和计算量消耗飞快增加。实际中由于内存和算力有限,一般只能编码一定长度,例如512。
为了提升模型的长程编码能力,从而提升模型在长文本,特别是document-level语料上的效果,我们必须对Transformer编码长度进行优化。本文带来了Transformer-XL、Longformer,详细分析他们如何实现编码长度优化。
LongFormer通过降低attention计算所需内存和算力,来实现长文本编码。我们也可以把它归入到算力优化中。但鉴于其名字就重点体现了它的长距离能力,故还是放在了编码长度优化中,和Transformer-XL一起来分析
2 Transformer-XL
 论文信息:2019年01月,谷歌 & CMU,ACL 2019 论文地址 https://arxiv.org/abs/1901.02860 代码和模型地址 https://github.com/kimiyoung/transformer-xl
论文信息:2019年01月,谷歌 & CMU,ACL 2019 论文地址 https://arxiv.org/abs/1901.02860 代码和模型地址 https://github.com/kimiyoung/transformer-xl
2.1 为什么需要Transformer-XL
为了解决长文本编码问题,原版Transformer采用了固定编码长度的方案,例如512个token。将长文本按照固定长度,切分为多个segment。每个segment内部单独编码,segment之间不产生交互信息。这种方式的问题如下
- 模型无法建模超过固定编码长度的文本
- segment之间没有交互信息,导致了文本碎片化。长语句的编码效果有待提升。
- predict阶段,decoder每生成一个字,就往后挪一个,没有重复利用之前信息,导致计算量爆炸
train和evaluate过程如下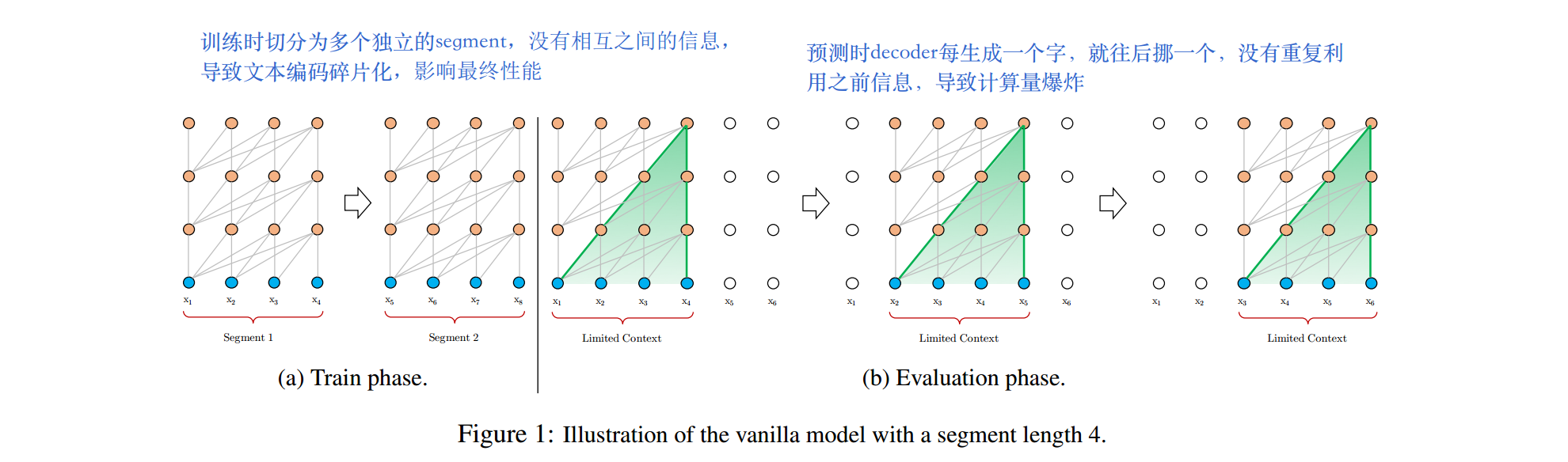
2.2 实现方法
2.2.1 Segment-Level Recurrence with State Reuse 片段级递归和信息复用
Transformer-XL在编码后一个segment时,将前一个segment的隐层缓存下来。后一个segment的self-attention计算,会使用到前一个segment的隐层。后一个segment的第n+1层,对前一个segment的第n层隐层进行融合。故最大编码长度理论上为O(N × L)。在预测阶段,由于对segment隐层使用了缓存,故每预测一个词,不需要重新对之前的文本进行计算。大大提升了预测速度,最大可达到原始Transformer的1800倍。如下图所示 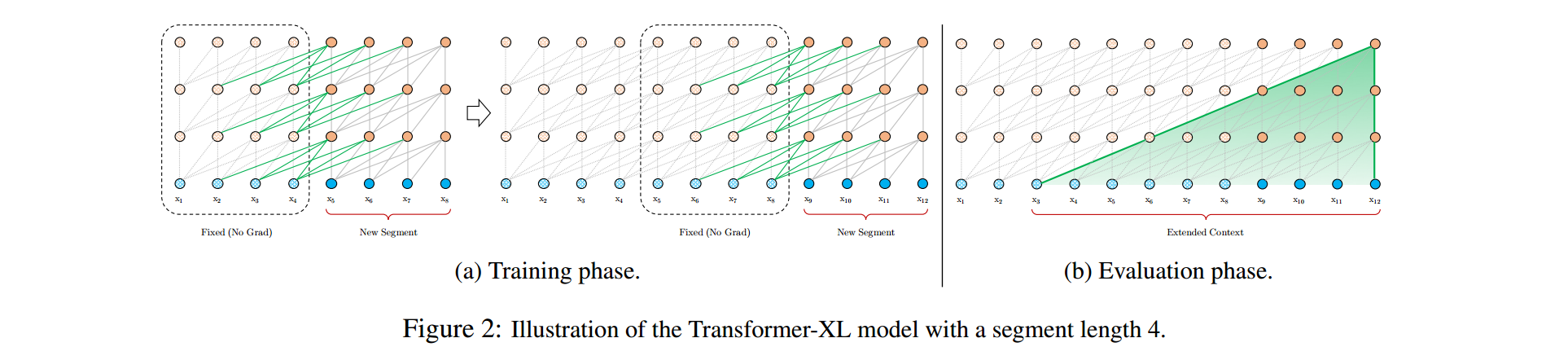
2.2.2 Relative Positional Encodings 相对位置编码
segment递归中有个比较大的问题,就是如何区分不同segment中的相同位置。如果采用原版Transformer中的绝对编码方案,两者是无法区分的。如下 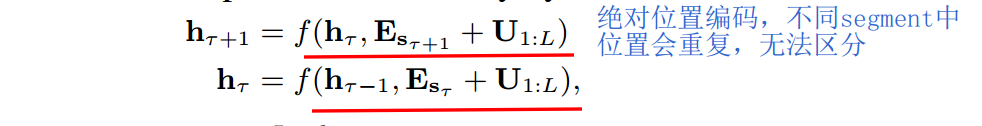 不同segment中的相同位置,其position encoding会相同。这显然是有问题的。Transformer-XL将绝对位置编码改为了q和k之间的相对位置编码,代表了两个token之间的相对位置。从语义上讲,是make sense的。我们来看看具体实现方式。
不同segment中的相同位置,其position encoding会相同。这显然是有问题的。Transformer-XL将绝对位置编码改为了q和k之间的相对位置编码,代表了两个token之间的相对位置。从语义上讲,是make sense的。我们来看看具体实现方式。
绝对位置编码的attention计算如下 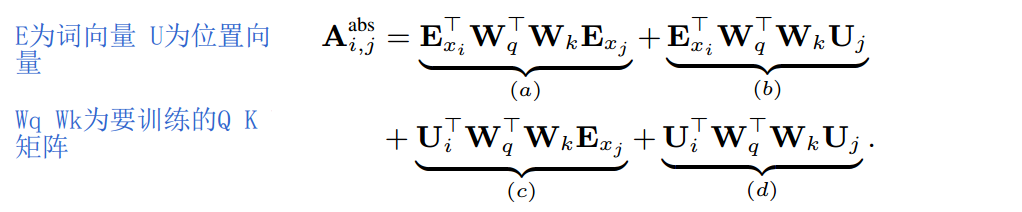 分为四部分
分为四部分
- query的token encoding和 key的token encoding,之间的关联信息
- query的token encoding和 key的position encoding,之间的关联信息。Uj为绝对位置j的编码向量
- query的position encoding和 key的token encoding,之间的关联信息。Ui为绝对位置i的编码向量
- query的position encoding和 key的position encoding,之间的关联信息
而采用相对位置编码后,attention计算如下 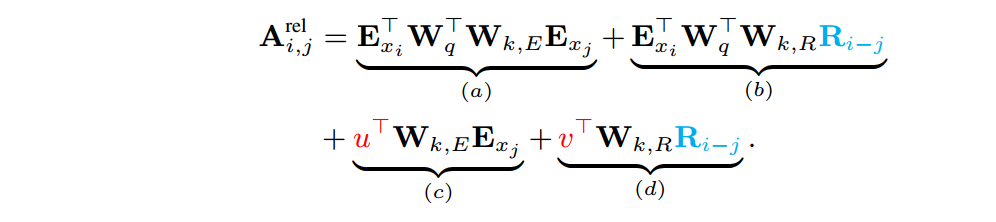 同样包含四部分,仍然为二者token encoding和position encoding之间的关联关系。区别在于
同样包含四部分,仍然为二者token encoding和position encoding之间的关联关系。区别在于
- Ri-j为i和j之间相对位置编码,其中R为相对位置编码矩阵
- u和v为query的位置编码,采用一个固定向量。因为采用相对位置编码后,无法对单个绝对位置进行编码了。文中称为global content bias,和global positional bias
也有其他文章,采用了不同的相对位置编码方案。比如"Peter Shaw, Jakob Uszkoreit, and Ashish Vaswani.2018. Self-attention with relative position representations. arXiv preprint arXiv:1803.02155." 中只有a和b两部分,丢掉了c和d。Transformer-XL对两种方案进行了对比实验,证明前一种好。
2.3 实验结果
长文本编码效果
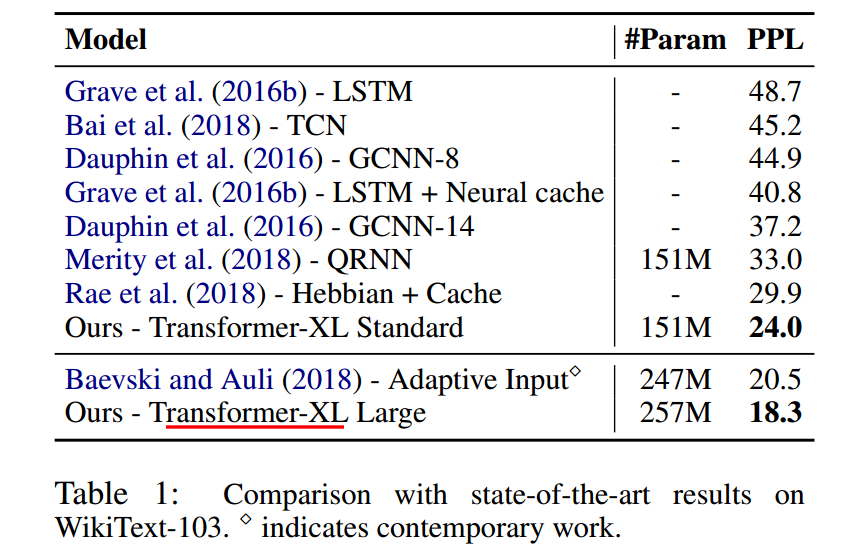 在WikiText-103上的实验结果。WikiText-103包含词级别的超长文本,平均每篇文章长度为3.6K token。利用它可以验证模型的长文本编码能力。实验结果表明Transformer-XL large的PPL最低,效果最好。同时作者在One Billion Word、enwik8、text8上均进行了实验,都表明Transformer-XL效果最好。
在WikiText-103上的实验结果。WikiText-103包含词级别的超长文本,平均每篇文章长度为3.6K token。利用它可以验证模型的长文本编码能力。实验结果表明Transformer-XL large的PPL最低,效果最好。同时作者在One Billion Word、enwik8、text8上均进行了实验,都表明Transformer-XL效果最好。
有效编码长度
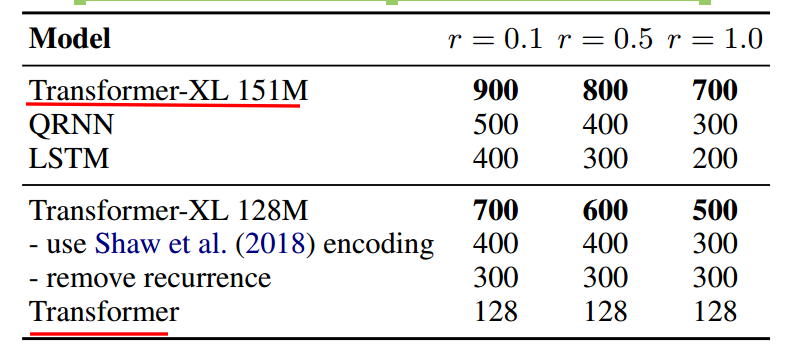 模型可编码的有效长度如上,r为top-r难度样本上的表现。Transformer-XL比RNN长80%,比Transformer长450%。证明Transformer-XL可编码长度最长,长程捕获能力最强。
模型可编码的有效长度如上,r为top-r难度样本上的表现。Transformer-XL比RNN长80%,比Transformer长450%。证明Transformer-XL可编码长度最长,长程捕获能力最强。
预测速度
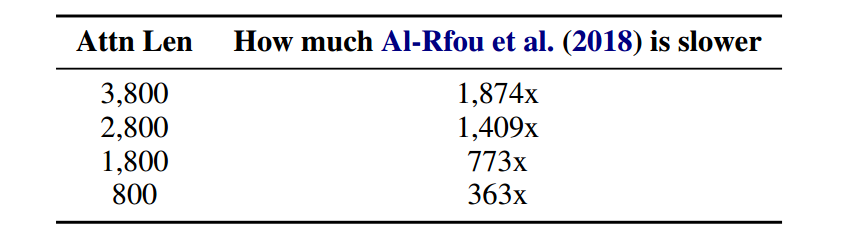 在不同segment长度下,模型预测速度的对比。和原始Transformer相比,预测速度最大可以提升1874倍。
在不同segment长度下,模型预测速度的对比。和原始Transformer相比,预测速度最大可以提升1874倍。
消融分析
文章对片段级递归和相对位置编码两个Method进行了消融分析,如下 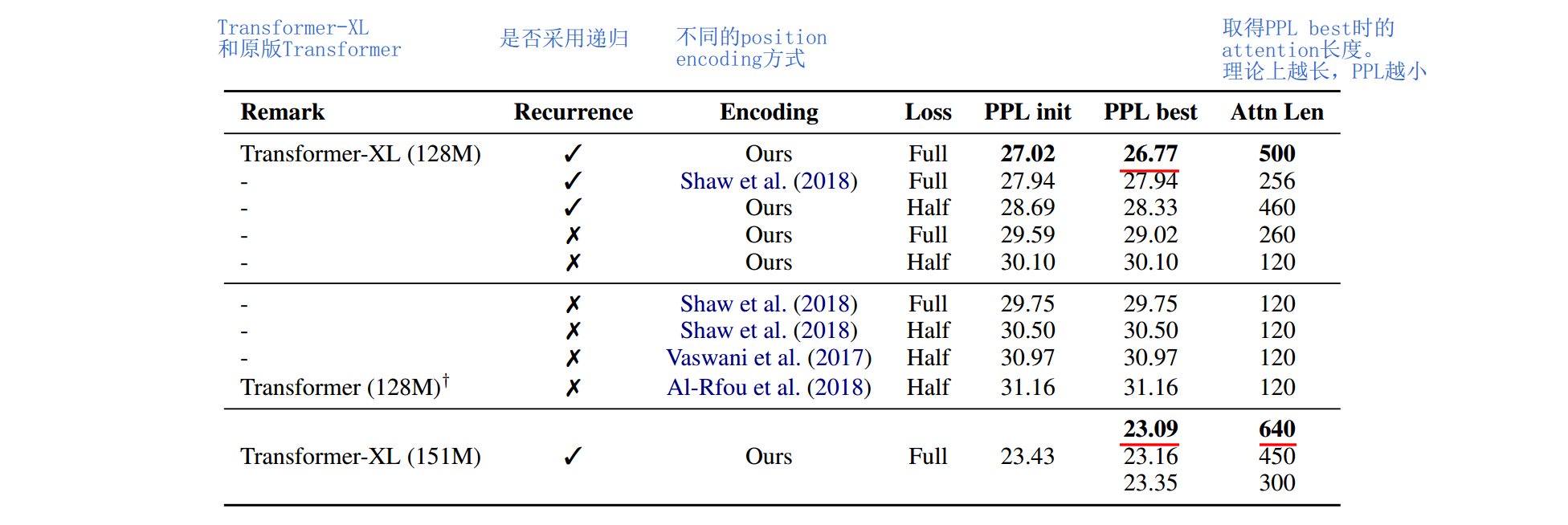 两个改进点均有作用,其中片段级递归作用更大。
两个改进点均有作用,其中片段级递归作用更大。
3 Longformer
 论文信息:2020年04月,allenai 论文地址 https://arxiv.org/abs/2004.05150 代码和模型地址 https://github.com/allenai/longformer
论文信息:2020年04月,allenai 论文地址 https://arxiv.org/abs/2004.05150 代码和模型地址 https://github.com/allenai/longformer
3.1 改进方法
3.1.1 attention稀疏化
Transformer不能捕获长距离信息,本质原因还是因为计算量过大导致的。那我们通过降低attention计算量,是不是就可以提升长距离编码能力呢。答案是肯定的,LongFormer提出了三种attention稀疏化的方法,来降低计算量。 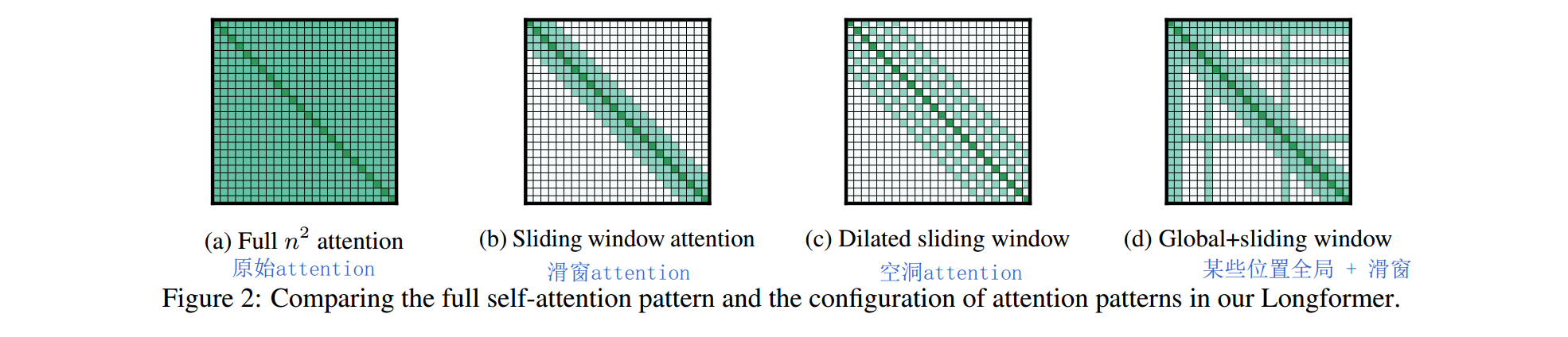 a是原始的全连接方式的attention。后面三种为文章使用的稀疏attention。
a是原始的全连接方式的attention。后面三种为文章使用的稀疏attention。
- Sliding Window attention。滑窗方式的attention。假设序列长度为n,滑窗大小w,则每个位置的attention只和滑窗范围内的token进行计算,复杂度从O(n^2)变为了O(n * w)。当w << n时,可以大大降低计算量。
- Dilated Sliding Window attention。受到空洞卷积的启发,提出了空洞滑窗attention。看下面这张图就明白了。
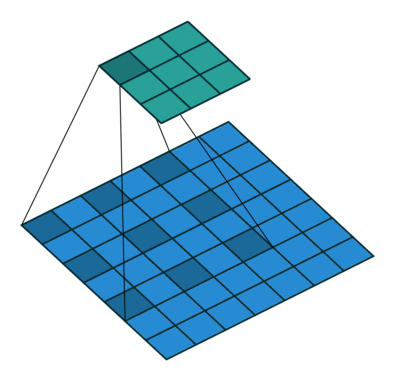
- Global Attention + sliding window。某些关键位置采用全局attention,这些位置的attention和所有token进行计算。而其他相对不关键的位置则采用滑窗attention。那什么叫关键位置呢?作者举例,分类问题中[CLS]为关键位置,需要计算全局attention。QA中question每个位置均为关键位置,同样计算全局attention。
3.1.2 Tensor Virtual Machine (TVM)
作者使用了TVM构建CUDA kernel,加快了longformer的速度,并降低了显存需求。这个又是另一个模型加速方面的话题,我们就先不展开了。
3.2 实验结果
大小模型效果
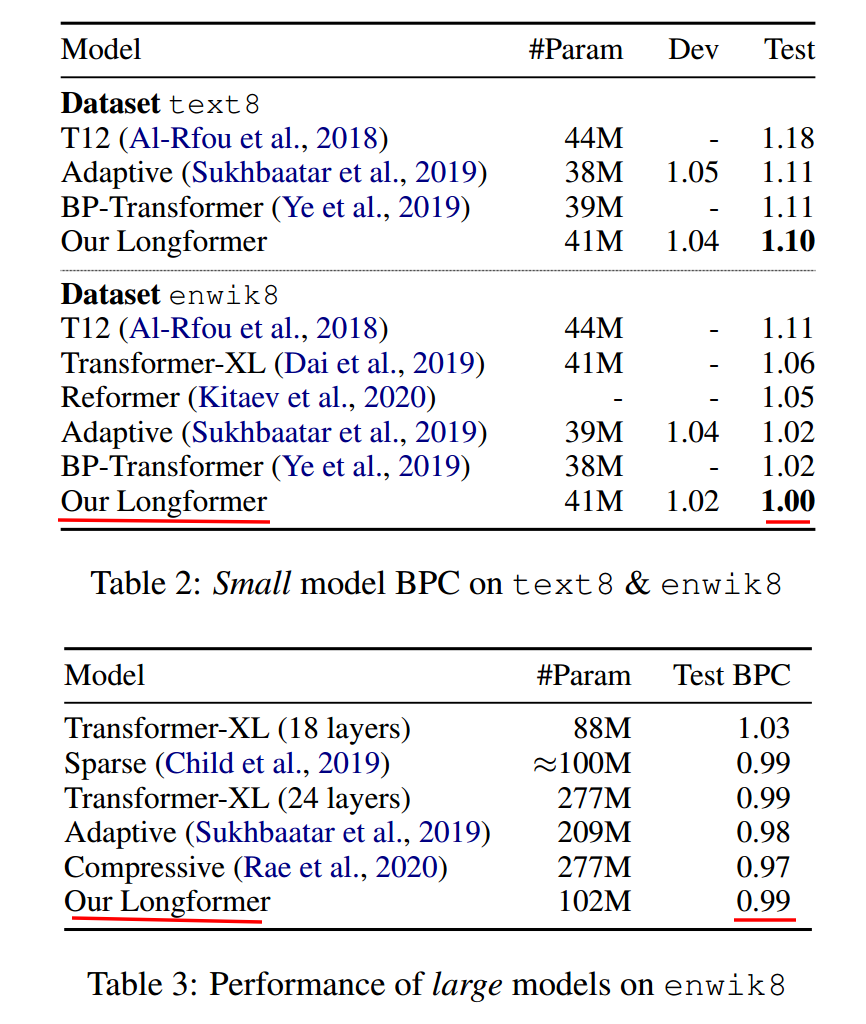 作者在大小模型上均实验了LongFormer的效果。小模型为12 layers,512 hidden。大模型为30 layers,512 hidden。在text8和enwik8数据集上。小模型达到了SOTA。大模型比18层的Transformer-XL好,虽然不如Adaptive-span-Transformer和Compressive,但胜在可以pretrain-finetune
作者在大小模型上均实验了LongFormer的效果。小模型为12 layers,512 hidden。大模型为30 layers,512 hidden。在text8和enwik8数据集上。小模型达到了SOTA。大模型比18层的Transformer-XL好,虽然不如Adaptive-span-Transformer和Compressive,但胜在可以pretrain-finetune
消融分析
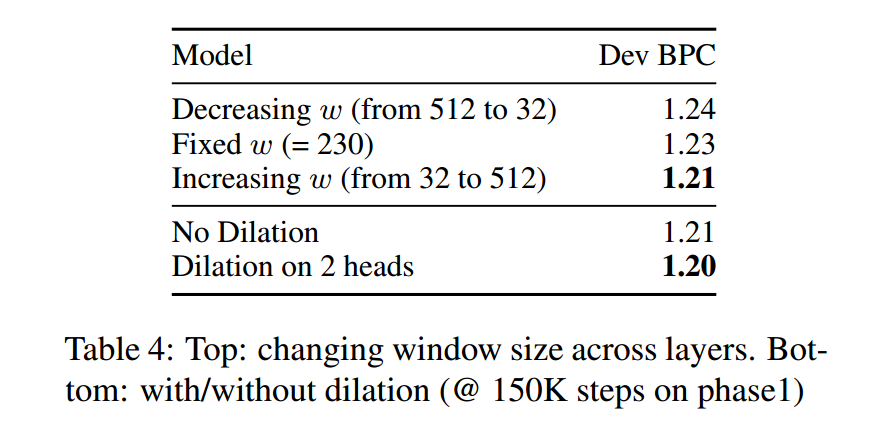 消融分析中,可以发现
消融分析中,可以发现
- Dilation空洞,有一定的收益
- top layer滑窗大小比bottom layer大时,效果好一些。这个也是make sense的。因为top layer捕获高维语义,关联信息距离相对较远,窗口应该尽量大一些。
语料长度
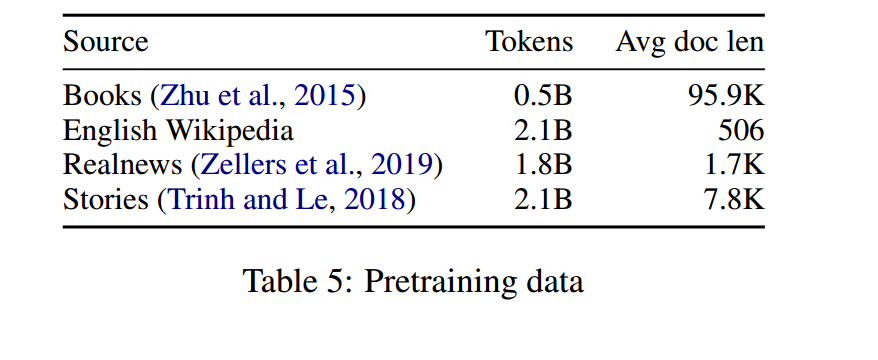 从上表中我们发现,语料都是特别长的长文本。LongFormer真的是document级别的Transformer。
从上表中我们发现,语料都是特别长的长文本。LongFormer真的是document级别的Transformer。
下游任务finetune效果

 第一个table为RoBERTa和LongFormer在问答、指代消解、分类任务中的对比。第二个table为这几个任务数据集平均文本长度。每项任务都是超出RoBERTa,当文本长度大于512时,performance提升特别明显。更加说明了长程捕获能力在NLP中的重要性。
第一个table为RoBERTa和LongFormer在问答、指代消解、分类任务中的对比。第二个table为这几个任务数据集平均文本长度。每项任务都是超出RoBERTa,当文本长度大于512时,performance提升特别明显。更加说明了长程捕获能力在NLP中的重要性。
🚀Transformer家族3 -- 计算效率优化(Adaptive-Span、Reformer、Lite-Transformer)
1 背景
上文我们从编码长度优化的角度,分析了如何对Transformer进行优化。Transformer-XL、LongFormer等模型,通过片段递归和attention稀疏化等方法,将长文本编码能力提升到了很高的高度。基本已经克服了Transformer长文本捕获能力偏弱的问题,使得下游任务模型performance得到了较大提升,特别是文本较长(大于512)的任务上。
但Transformer计算量和内存消耗过大的问题,还亟待解决。事实上,Transformer-XL、LongFormer已经大大降低了内存和算力消耗。毕竟Transformer之所以长距离编码能力偏弱,就是因为其计算量是序列长度的平方关系,对算力需求过大,导致当前GPU/TPU不能满足需求。编码长度优化和计算量优化,二者是相辅相成的。但着眼于论文的出发点,我们还是分为两个不同的章节进行分析。毕竟总不能所有模型都放在一个章节吧(_)。
本文我们带来Adaptive-Span Transformer、Reformer、Lite-Transformer等几篇文章
2 Adaptive-Span Transformer
 论文信息:2019年5月,FaceBook,ACL2019 论文地址 https://arxiv.org/pdf/1905.07799.pdf 代码和模型地址 https://github.com/facebookresearch/adaptive-span
论文信息:2019年5月,FaceBook,ACL2019 论文地址 https://arxiv.org/pdf/1905.07799.pdf 代码和模型地址 https://github.com/facebookresearch/adaptive-span
2.1 为什么需要Adaptive-Span
之前Transformer-XL将长文本编码能力提升到了较高高度,但是否每个layer的每个head,都需要这么长的attention呢?尽管使用了多种优化手段,长距离attention毕竟还是需要较大的内存和算力。研究发现,大部分head只需要50左右的attention长度,只有少部分head需要较长的attention。这个是make sense的,大部分token只和它附近的token有关联。如下图 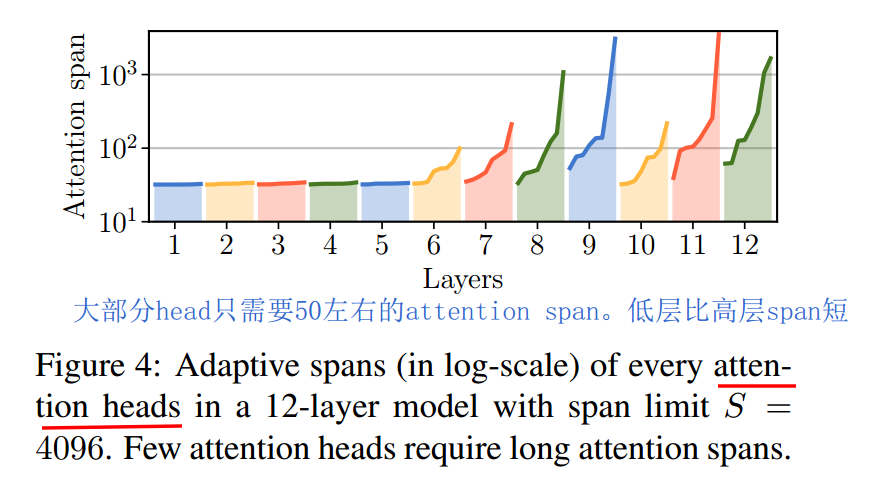 我们是否可以实现attention span长度的自适应呢?让不同的layer的不同的head,自己去学习自己的attention span长度呢?Adaptive-Span Transformer给出了肯定答案。
我们是否可以实现attention span长度的自适应呢?让不同的layer的不同的head,自己去学习自己的attention span长度呢?Adaptive-Span Transformer给出了肯定答案。
2.2 实现方案
文章设定每个attention head内的token计算,都使用同一个span长度。我们就可以利用attention mask来实现自适应span。对每个head都添加一个attention mask,mask为0的位置不进行attention计算。文章设计的mask函数如下 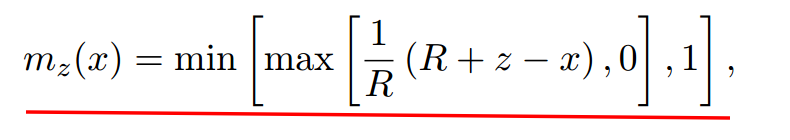 R为超参,控制曲线平滑度。其为单调递减函数,如下图。
R为超参,控制曲线平滑度。其为单调递减函数,如下图。 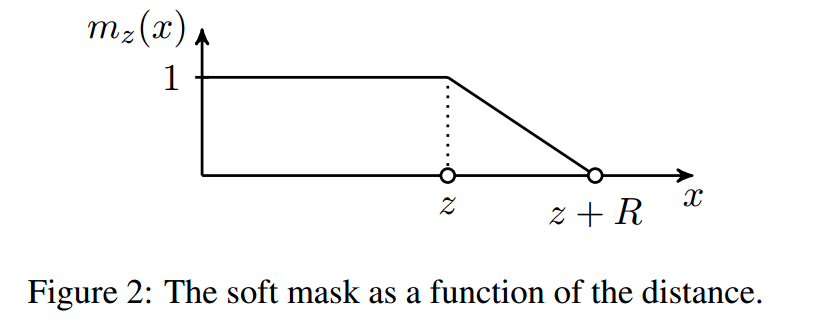
2.3 实验结果
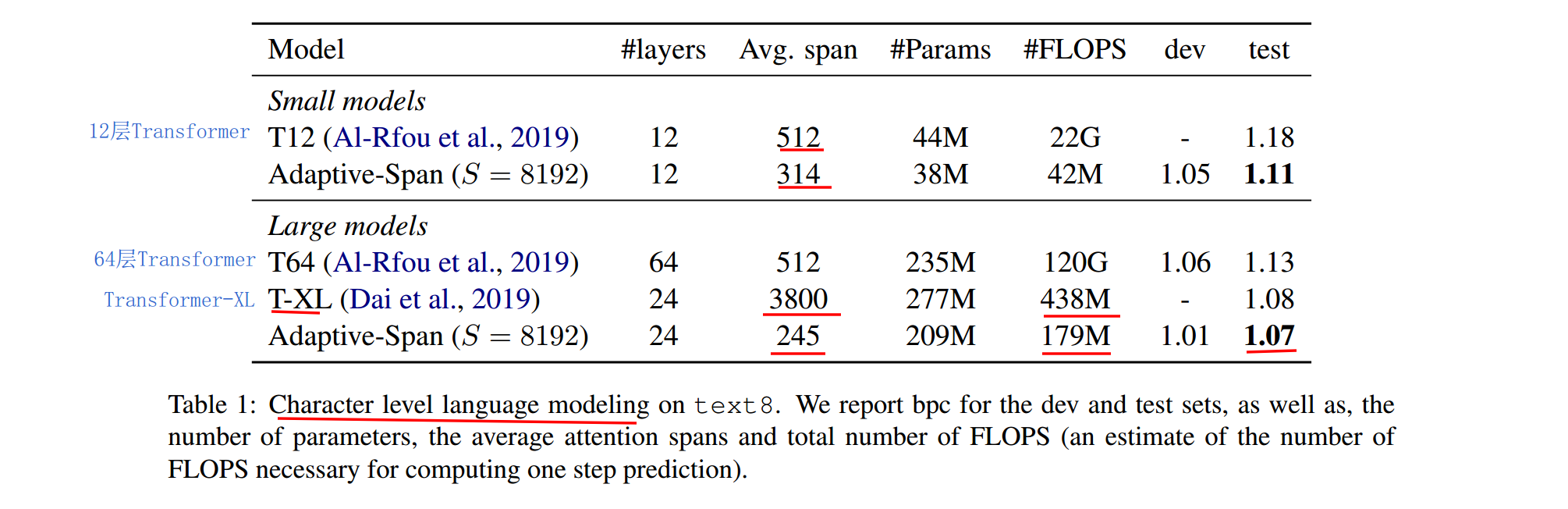 和Transformer家族其他很多模型一样,Adaptive-span也在字符级别的语言模型上进行了验证,数据集为text8。如上,Transformer注意力长度固定为512,结论如下
和Transformer家族其他很多模型一样,Adaptive-span也在字符级别的语言模型上进行了验证,数据集为text8。如上,Transformer注意力长度固定为512,结论如下
- Transformer-XL长程编码能力确实很强,平均span可达3800。
- 注意力长度确实不需要总那么长,Adaptive-Span大模型上,平均长度只有245
- Adaptive-Span在算力需求很小(只有XL的1/3)的情况下,效果可以达到SOTA。
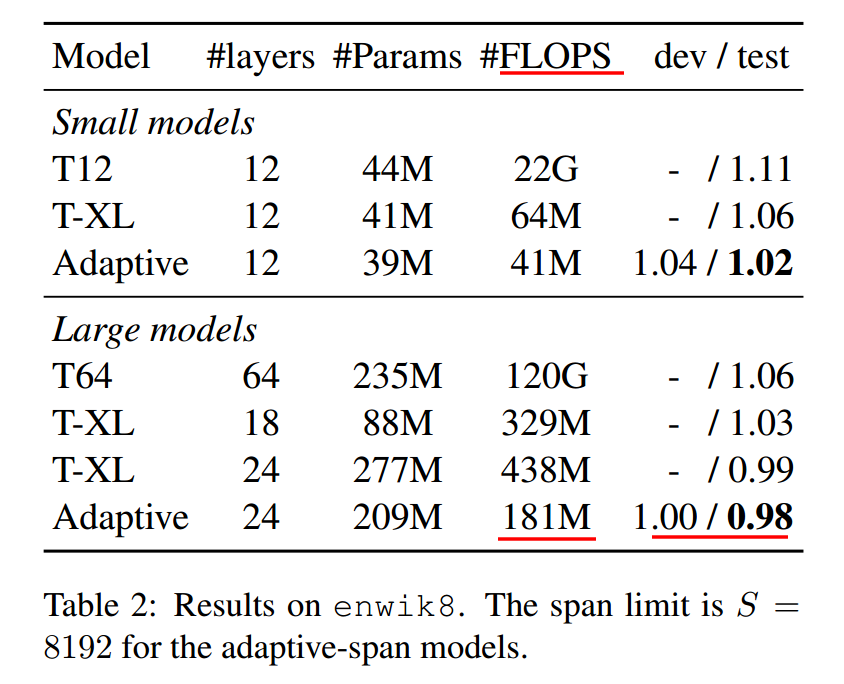 上面是在enwik8上的结果。Adaptive-Span又一次在算力很小的情况下,达到了最优效果。值得注意的是,64层的Transformer居然需要120G的计算量,又一次证明了原版Transformer是多么的吃计算资源。另外Transformer-XL在节省计算资源上,其实也算可圈可点。
上面是在enwik8上的结果。Adaptive-Span又一次在算力很小的情况下,达到了最优效果。值得注意的是,64层的Transformer居然需要120G的计算量,又一次证明了原版Transformer是多么的吃计算资源。另外Transformer-XL在节省计算资源上,其实也算可圈可点。
3 Reformer
 论文信息:2020年1月,谷歌,ICLR2020 论文地址 https://arxiv.org/abs/2001.04451 代码和模型地址 https://github.com/google/trax/tree/master/trax/models/reformer
论文信息:2020年1月,谷歌,ICLR2020 论文地址 https://arxiv.org/abs/2001.04451 代码和模型地址 https://github.com/google/trax/tree/master/trax/models/reformer
3.1 为什么需要Reformer
Transformer内存和计算量消耗大的问题,一直以来广为诟病,并导致其一直不能在长文本上进行应用。(BERT、RoBERTa均设置最大长度为512)。Reformer认为Transformer有三大问题
- attention层计算量和序列长度为平方关系,导致无法进行长距离编码
- 内存占用和模型层数呈N倍关系,导致加深Transformer层数,消耗的内存特别大
- feed-forward的dff比隐层dmodel一般大很多,导致FF层占用的内存特别大
针对这几个问题,Reformer创新性的提出了三点改进方案
- LOCALITY-SENSITIVE HASHING 局部敏感hash,使得计算量从 O(L^2)降低为O(L log L) ,L为序列长度
- Reversible Transformer 可逆Transformer,使得N层layers内存消耗变为只需要一层,从而使得模型加深不会受内存限制。
- Feed-forward Chunking 分块全连接,大大降低了feed-forward层的内存消耗。
Reformer是Transformer家族中最为关键的几个模型之一(去掉之一貌似都可以,顶多Transformer-XL不答应),其创新新也特别新颖,很多思想值得我们深入思考和借鉴。其效果也是特别明显,大大提高了内存和计算资源效率,编码长度可达64k。下面针对它的三点改进方案进行分析,有点难懂哦。
3.2 实现方案
3.2.1 LOCALITY-SENSITIVE HASHING 局部敏感hash
局部敏感hash有点难懂,Reformer针对Transformer结构进行了深度灵魂拷问
Query和Key必须用两套吗
Transformer主体结构为attention,原版attention计算方法如下 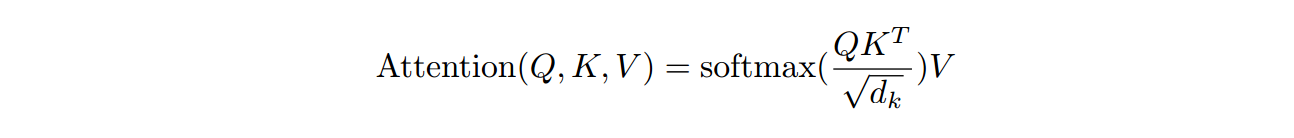 每个token,利用其query向量,和其他token的key向量进行点乘,从而代表两个token之间的相关性。归一化后,利用得到的相关性权重,对每个token的value向量进行加权求和。首先一个问题就是,query和key向量可以是同一套吗?我们可否利用key向量去和其他token的key计算相关性呢?
每个token,利用其query向量,和其他token的key向量进行点乘,从而代表两个token之间的相关性。归一化后,利用得到的相关性权重,对每个token的value向量进行加权求和。首先一个问题就是,query和key向量可以是同一套吗?我们可否利用key向量去和其他token的key计算相关性呢?
为此文章进行实验分析,证明是可行的。个人认为这一点也是make sense的。 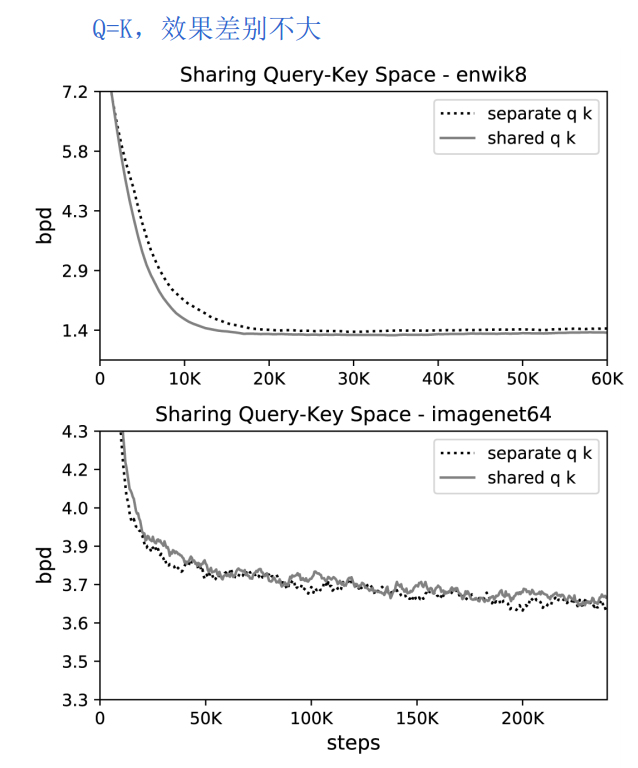 在文本和图像上,Q=K的attention,和普通attention,效果差别不大。
在文本和图像上,Q=K的attention,和普通attention,效果差别不大。
必须和每个token计算相关性吗
原版attention中,一个token必须和序列中其他所有token计算相关性,导致计算量随序列长度呈平方关系增长,大大制约了可编码最大长度。那必须和每个token计算相关性吗?其实之前Adaptive-Span Transformer也深度拷问过这个话题。它得出的结论是,对于大部分layer的multi-head,长度50范围内进行attention就已经足够了。不过Adaptive-Span采取的方法还是简单粗暴了一点,它约定每个head的attention span长度是固定的,并且attention span为当前token附近的其他token。
Adaptive-Span Transformer的这种方法显然还是没有抓住Attention计算冗余的痛点。Attention本质是加权求和,权重为两个token间的相关性。最终结果取决于较大的topk权重,其他权值较小的基本就是炮灰。并且softmax归一化更是加剧了这一点。小者更小,大者更大。为了减少计算冗余,我们可以只对相关性大的其他token的key向量计算Attention。
怎么找到相关性大的向量呢
我们现在要从序列中找到与本token相关性最大的token,也就是当前key向量与哪些key向量相关性大。极端例子,如果两个向量完全相同,他们的相关性是最高的。确定两个高维向量的相关性确实比较困难,好在我们可以利用向量Hash来计算。
Reformer采用了局部敏感hash。我们让两个key向量在随机向量上投影,将它们划分到投影区间内。 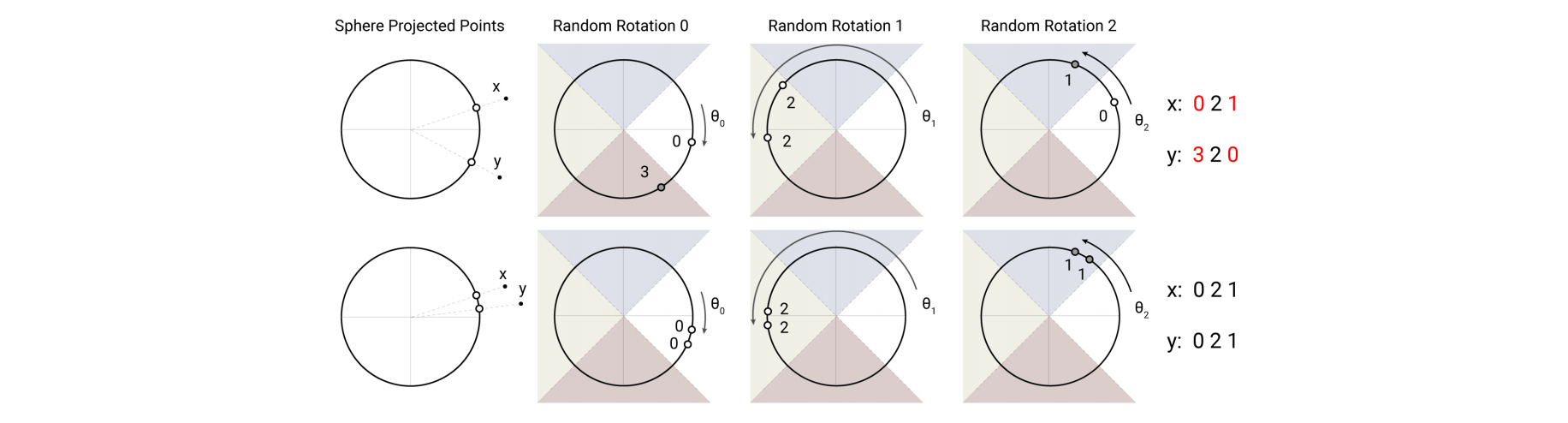 如图所示,划分了四个区间(4个桶bucket),进行了三次Hash。第一次Hash,使得上面两个向量分别归入bucket0和bucket3中,下面两个向量都归入bucket0。第二次Hash,上面两个向量和下面两个,均归入到bucket2中了。我们可以发现
如图所示,划分了四个区间(4个桶bucket),进行了三次Hash。第一次Hash,使得上面两个向量分别归入bucket0和bucket3中,下面两个向量都归入bucket0。第二次Hash,上面两个向量和下面两个,均归入到bucket2中了。我们可以发现
- 相似的向量,也就是相关性大的,容易归入到一个bucket中
- 局部敏感Hash还是有一定的错误率的,我们可以利用多轮Hash来缓解。这也是Reformer的做法,它采取了4轮和8轮的Hash。
整个流程
经过局部敏感Hash后,我们可以将相关性大的key归入同一个bucket中。这样只用在bucket内进行普通Attention即可,大大降低了计算冗余度。为了实现并行计算,考虑到每个bucket包含的向量数目可能不同,实际处理中需要多看一个bucket。整个流程如下 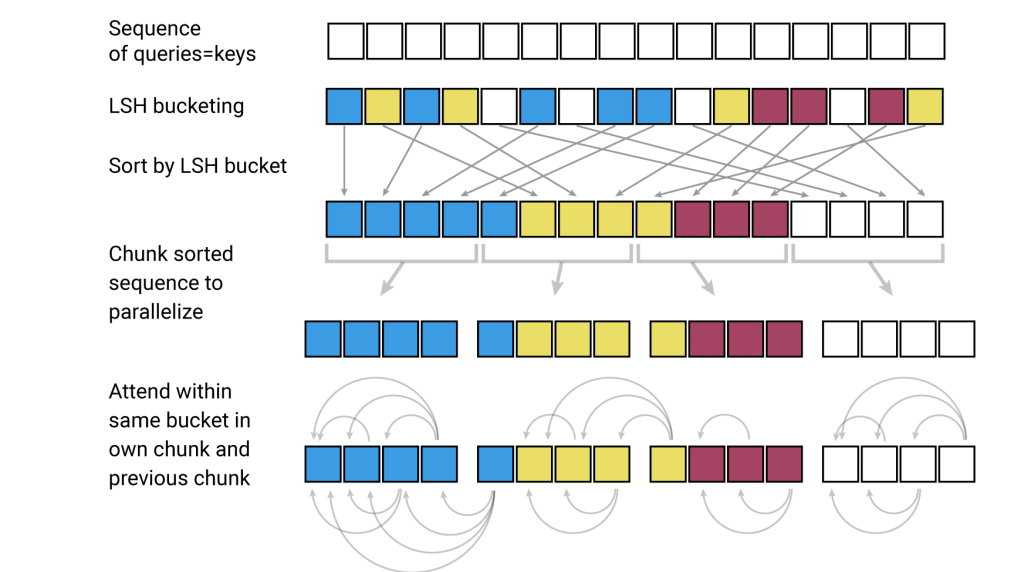
- 让query等于key
- 局部敏感Hash(LSH)分桶。上图同一颜色的为同一个桶,共4个桶
- 桶排序,将相同的桶放在一起
- 为了实现并行计算,将所有桶分块(chunk),每个chunk大小相同
- 桶内计算Attention,由于之前做了分块操作,所以需要多看一个块。
多轮LSH
为了减少分桶错误率,文章采用了多次分桶,计算LSH Attention,Multi-round LSH attention。可以提升整体准确率。如下表。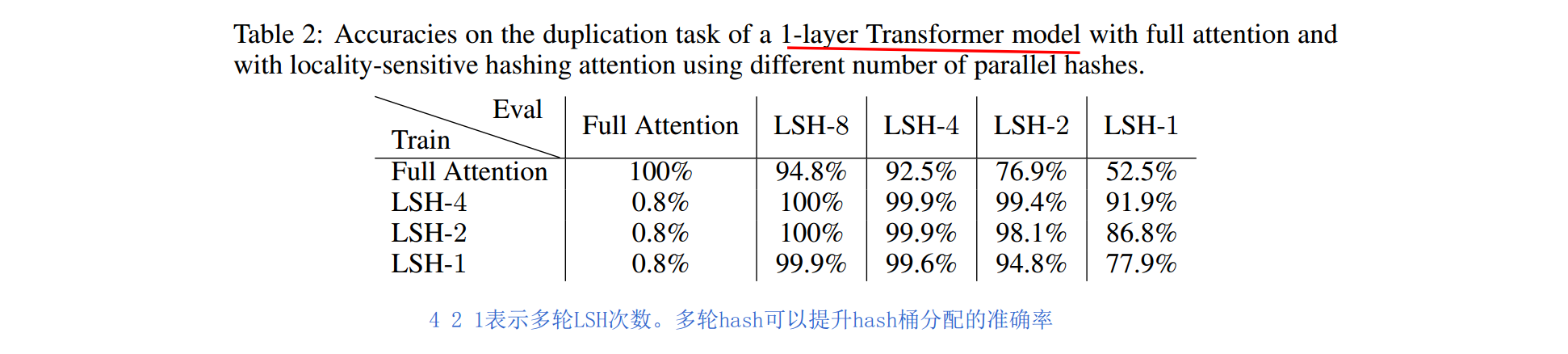
3.2.2 REVERSIBLE TRANSFORMER 可逆Transformer
LSH局部敏感Hash确实比较难理解,可逆Transformer相对好懂一些。这个方案是为了解决Transformer内存占用量,随layers层数线性增长的问题。为什么会线性增长呢?原因是反向传播中,梯度会从top layer向bottom layer传播,所以必须保存住每一层的Q K V向量,也就导致N层就需要N套Q K V。
那有没有办法不保存每一层的Q K V呢?可逆Transformer正是这个思路。它利用时间换空间的思想,只保留一层的向量,反向传播时,实时计算出之前层的向量。所以叫做Reversible。Reformer每一层分为两部分,x1和x2。输出也两部分,y1和y2。计算如下

采用可逆残差连接后,模型效果基本没有下降。这也是make sense的,毕竟可逆是从计算角度来解决问题的,对模型本身没有改变。 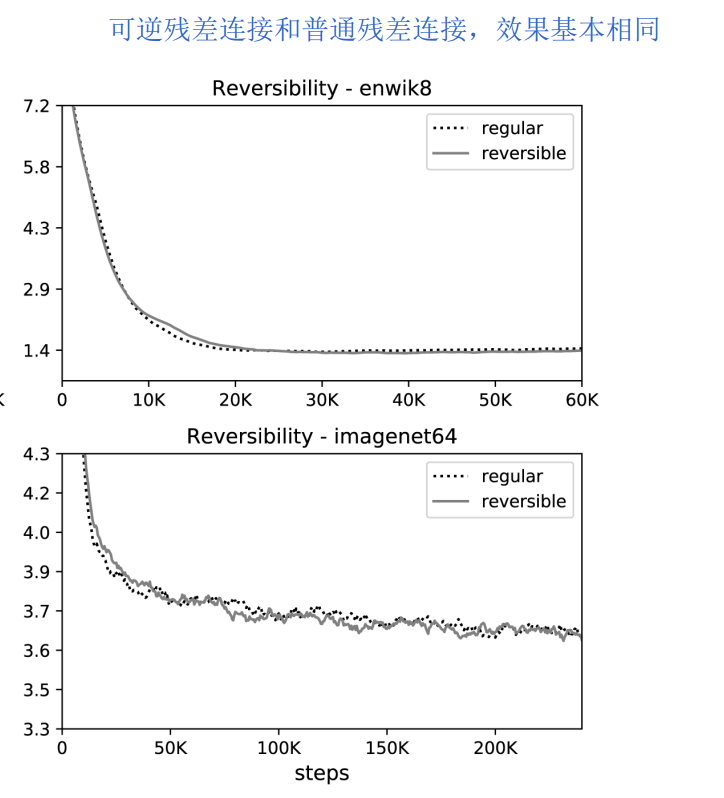
3.2.3 Feed-Forward chunking FF层分块
针对fead-forward层内存消耗过大的问题,Reformer也给出了解决方案,就是FF层分块。如下 
3.3 实验结果
内存和时间复杂度
Reformer三个创新点,大大降低了内存和时间复杂度,消融分析如下 
模型效果
如下为在机器翻译上的效果。Reformer减少了算力消耗,同时也大大增加了长文本编码能力,故模型效果也得到了提升。如下。 
4 Lite Transformer
 论文信息:2020年4月,MIT & 上海交大,ICLR2020 论文地址 https://arxiv.org/abs/2004.11886 代码和模型地址 https://github.com/mit-han-lab/lite-transformer
论文信息:2020年4月,MIT & 上海交大,ICLR2020 论文地址 https://arxiv.org/abs/2004.11886 代码和模型地址 https://github.com/mit-han-lab/lite-transformer
4.1 为什么要做Lite Transformer
主要出发点仍然是Transformer计算量太大,计算冗余过多的问题。跟Adaptive-Span Transformer和Reformer想法一样,Lite Transformer也觉得没必要做Full Attention,很多Attention连接是冗余的。不一样的是,它通过压缩Attention通道的方式实现,将多头减少了一半。与Base Transformer相比,计算量减少了2.5倍。并且文章使用了量化和剪枝技术,使得模型体积减小了18.2倍。
4.2 实现方案
实现方案很简单,仍然采用了原版Transformer的seq2seq结构,创新点为
- multiHead self-attention变为了两路并行,分别为一半的通道数(多头)。如下图a所示。其中左半部分为正常的fully attention,它用来捕获全局信息。右半部分为CNN卷积,用来捕获布局信息。最终二者通过FFN层融合。这个架构称为LONG-SHORT RANGE ATTENTION (LSRA),长短期Attention。
- 为了进一步降低计算量,作者将CNN转变为了一个depth wise卷积和一个线性全连接。dw卷积在mobileNet中有讲过,不清楚可自行谷歌。
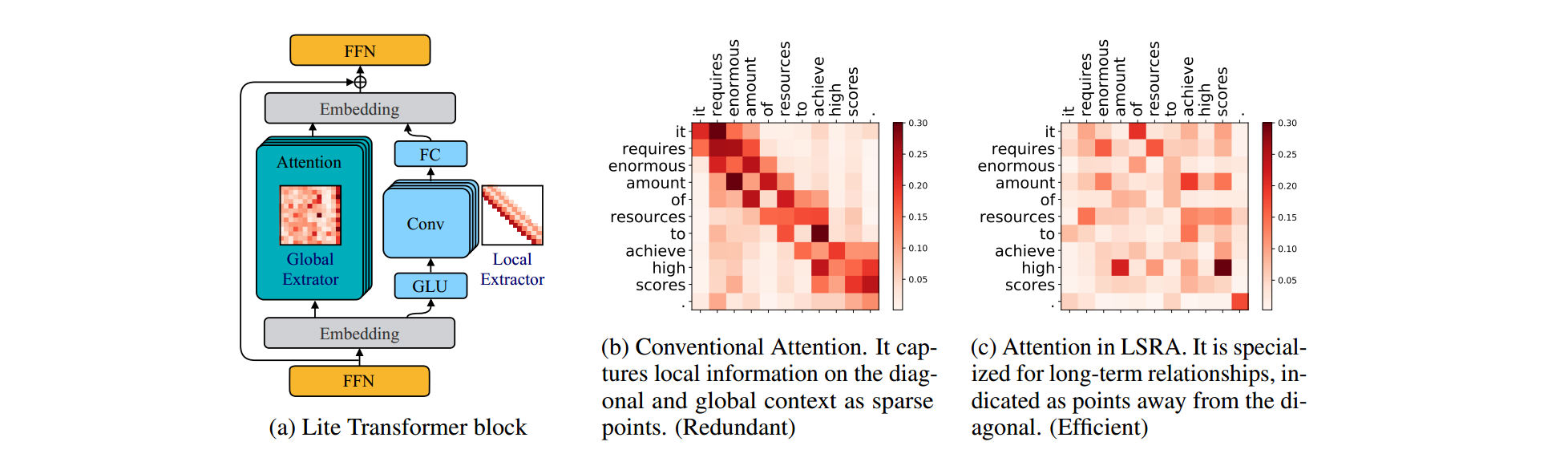
4.3 实验结果
计算复杂度
 如上图,在文本摘要任务上,Lite Transformer计算量相比Base Transformer,减少了2.5倍。同时Rouge指标基本没变。
如上图,在文本摘要任务上,Lite Transformer计算量相比Base Transformer,减少了2.5倍。同时Rouge指标基本没变。
模型体积
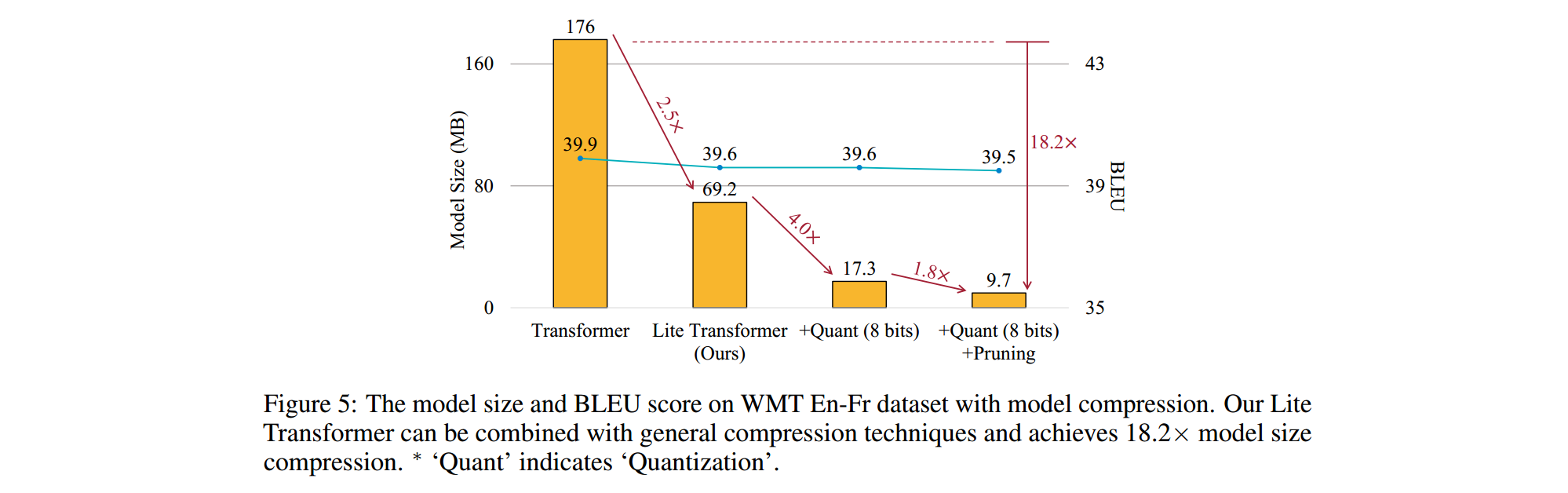 Lite Transformer模型体积只有Transformer的2.5分之一,通过8bit量化和剪枝,最终模型体积下降了18.2倍。
Lite Transformer模型体积只有Transformer的2.5分之一,通过8bit量化和剪枝,最终模型体积下降了18.2倍。
5 其他
其他几篇文章,也建议拜读下
- Generating Long Sequences with Sparse Transformers (OpenAI, 2019.04)
- Adaptively Sparse Transformers (EMNLP2019, 2019.09)
- Compressive Transformers for Long-Range Sequence Modelling (2019.11)
- Transformer on a Diet (2020.02)
🚀Transformer家族4 -- 通用性优化(Universal-Transformer)
1 背景
之前讲Transformer的时候,也提到过它的通用性的缺点。相比于RNN,Transformer不是图灵完备的,虽然大多数任务都是吊打RNN,但在某些看起来极为简单的任务上,却表现很差,比如字符串拷贝等。这个问题其实也不算大,但谷歌还是给出了他的解决方案,也就是Universal Transformer。这篇看看就好了,个人感觉实际应用中作用有限。
2 Universal-Transformer
 论文信息:2018年7月,谷歌,ICLR2019 论文地址 https://arxiv.org/abs/1807.03819 代码和模型地址 https://github.com/tensorflow/tensor2tensor
论文信息:2018年7月,谷歌,ICLR2019 论文地址 https://arxiv.org/abs/1807.03819 代码和模型地址 https://github.com/tensorflow/tensor2tensor
2.1 为什么需要Universal-Transformer
主要的出发点是原版Transformer不是图灵完备的,有些很简单的任务表现很差,比如字符串拷贝。序列任务还是比较偏好于迭代和递归变换,RNN正好满足了这一点,而Transformer不满足。这一点文章称作归纳偏置(Inductive Bias)。深度学习的归纳偏置是什么?
2.2 实现方案
模型结构
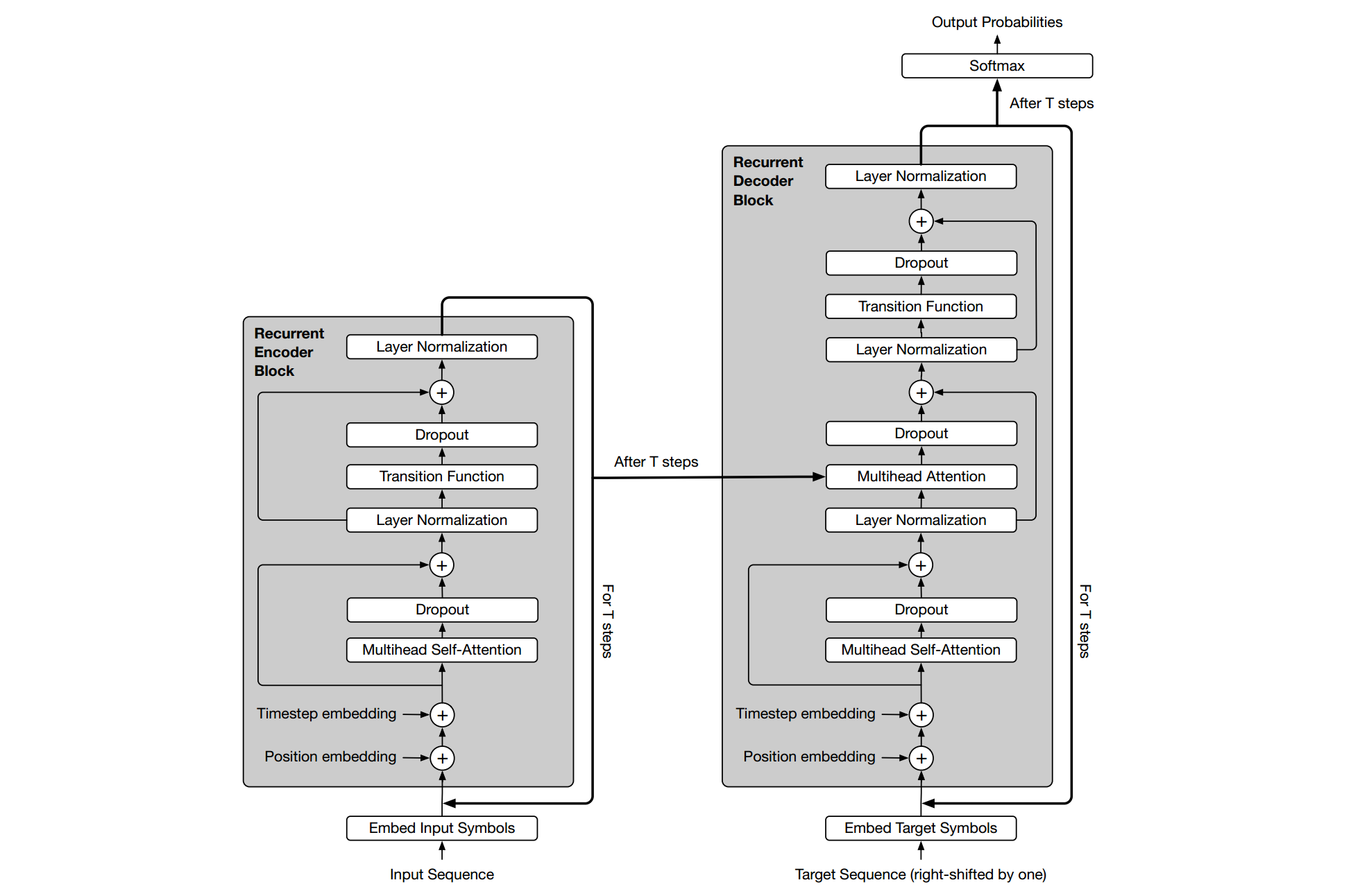 如上所示为Universal-Transformer的结构,仍然为一个基于multiHead self-attention的seq2seq,几点不同
如上所示为Universal-Transformer的结构,仍然为一个基于multiHead self-attention的seq2seq,几点不同
- 引入了时间步step,从而实现了循环递归。除了第一次是原始信息作为输入,之后都是由前一个step的输出作为后一个的输入。
- Feed-forward换成了Transition函数。根据task不同,可选择separable convolution分解卷积和fully-connected neural network全连接神经网络。
- 时间和位置编码,TimeStep embedding和Position embedding,新引入了TimeStep embedding,二者的编码公式和Transformer中的位置编码很像,如下

Adaptive Computation Time(ACT) 自适应计算时间
前人已经提到过ACT了,作者在模型中引用了。序列问题中,有些词语比其他的更模糊。他们需要进行更多次的计算。Universal-Transformer利用了ACT机制,可以对每个token设置自适应计算时间。模型会动态调整每个位置所需的计算steps。当某个位置停止计算后,直接copy它的隐状态到下一step。当所有位置都停止计算后,整个过程才停止。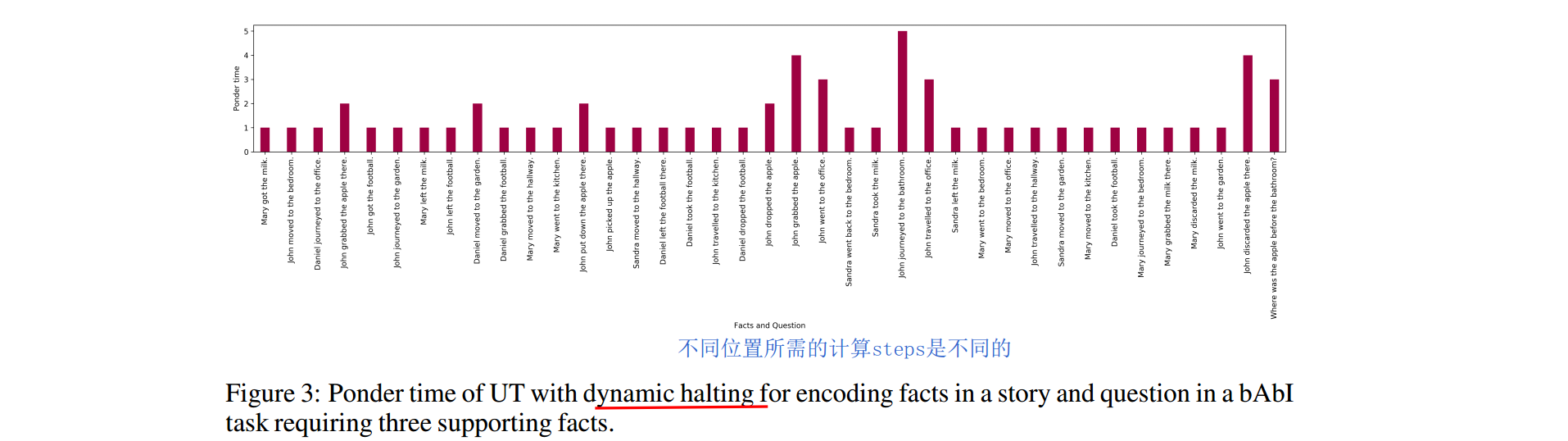 如上,不同位置token所需的计算steps是不同的。
如上,不同位置token所需的计算steps是不同的。
2.3 实验结果
字符串任务
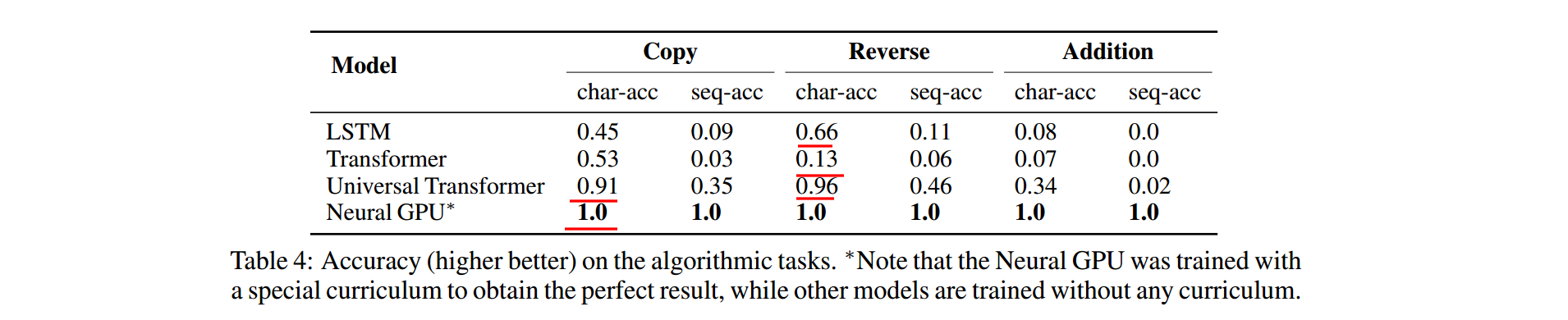 字符串复制、翻转、添加操作的效果。可以发现
字符串复制、翻转、添加操作的效果。可以发现
- Transformer效果确实比较差,比LSTM差很多。这也验证了Transformer通用性确实有些问题,也就是本文的出发点
- Universal-Transformer效果很好,超过LSTM很多,成功解决了原版Transformer的问题
机器翻译
 机器翻译上的结果,Universal-Transformer的BLEU比原版Transformer提高了0.9%
机器翻译上的结果,Universal-Transformer的BLEU比原版Transformer提高了0.9%
🚀Transformer家族5 -- 推理加速(Faster-Transformer 、TurboTransformers)
1 背景
之前介绍了从编码长度、计算效率、通用性等角度对Transformer进行优化,并介绍了几个重要模型。本文介绍如何进行Transformer推理加速。相比于离线训练,在线推理加速更加关键。一方面由于在线流量大,加速可带来硬件成本的节省。另一方面在线推理加速,可大大提升AI应用的用户体验。
事实上,之前的多种方法,特别是计算效率优化,对推理加速很有帮助。这些模型从算法的角度,进行了推理速度优化。本文主要从框架层的角度,讲解如何对推理进行加速。主要带来NVIDIA的Faster-Transformer框架和腾讯的Turbo-Transformer框架。
2 Faster-Transformer
PPT资料:https://on-demand.gputechconf.com/gtc-cn/2019/pdf/CN9468/presentation.pdf 代码地址:https://github.com/NVIDIA/DeepLearningExamples/tree/master/FasterTransformer
实现方案
Faster-Transformer算法结构和原版Transformer基本一致,主要是从框架层角度来实现计算加速。主要方法有
- 算子融合。对除矩阵乘法外的所有算子,进行了合并。比如Add、Sub。从而减少了GPU kernel调度和显存读写。
- 半精度F16优化。
- GELU激活函数、层正则化、softmax等调用频次很高的操作的优化
效果
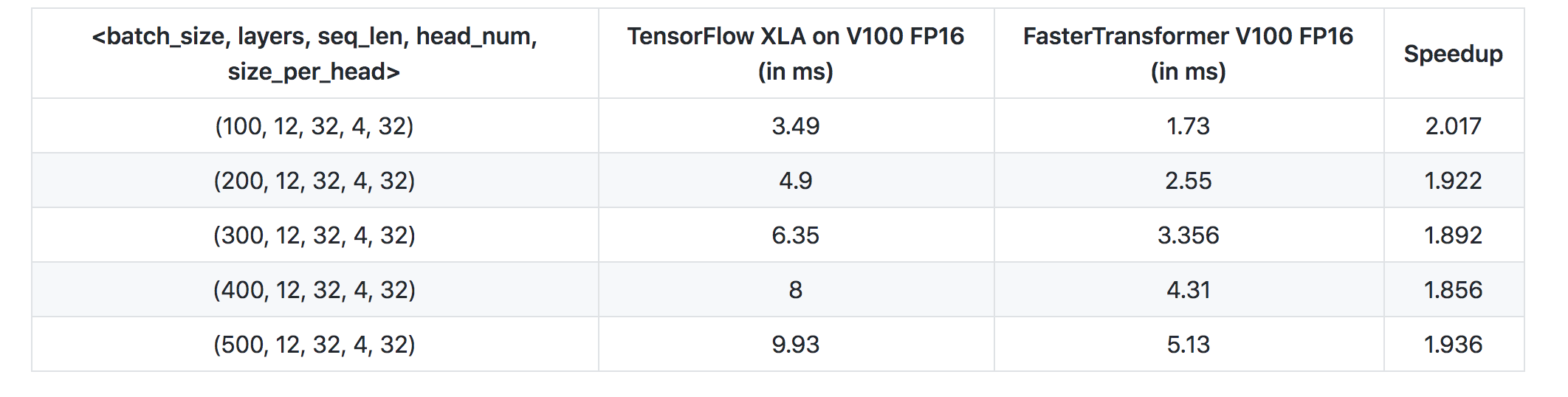 Encoder效果对比如上。Faster-Transformer基本吊打TF XLA,提升速度一倍多。
Encoder效果对比如上。Faster-Transformer基本吊打TF XLA,提升速度一倍多。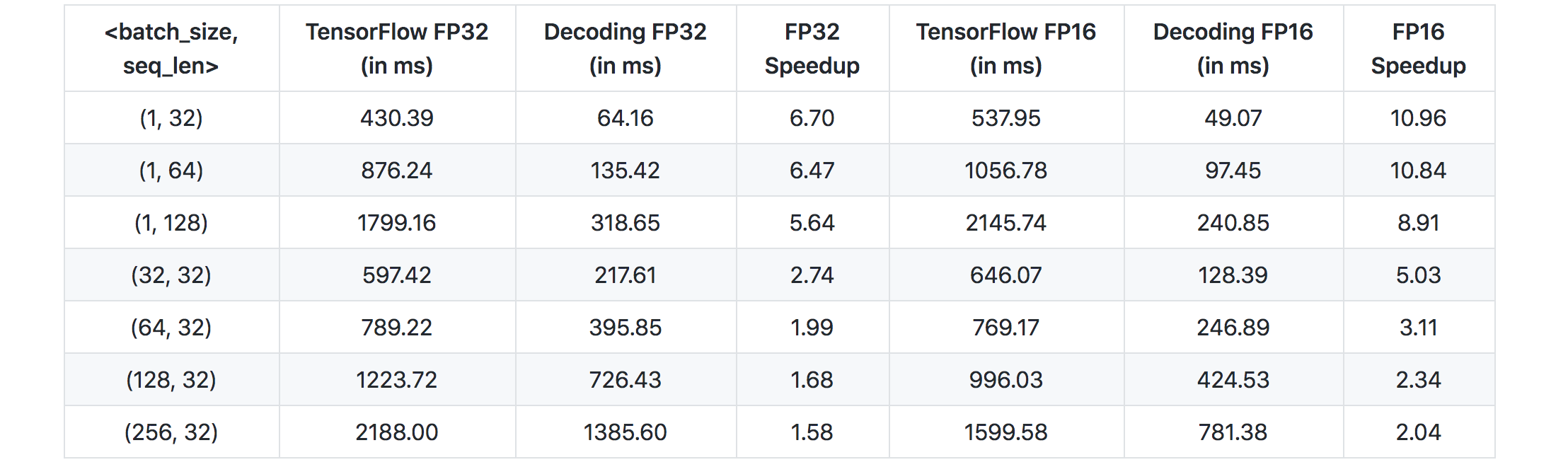 Decoder效果对比如上。对比了32bit和16bit的结果。Decoding FP32和Decoding FP16为Faster-Transformer 的结果,也是吊打原始TensorFlow。
Decoder效果对比如上。对比了32bit和16bit的结果。Decoding FP32和Decoding FP16为Faster-Transformer 的结果,也是吊打原始TensorFlow。
3 TurboTransformers
 代码地址 https://github.com/Tencent/TurboTransformers
代码地址 https://github.com/Tencent/TurboTransformers
实现方案
- 和Faster-Transformer一样,进行了算子融合。从而减少GPU kernel调用和显存占用
- 对于LayerNorm和softmax,由于不适合并行计算,重新开发并实现了并行计算版本。
- 内存缓存,避免频繁释放和分配内存。
和其他方案的对比

效果
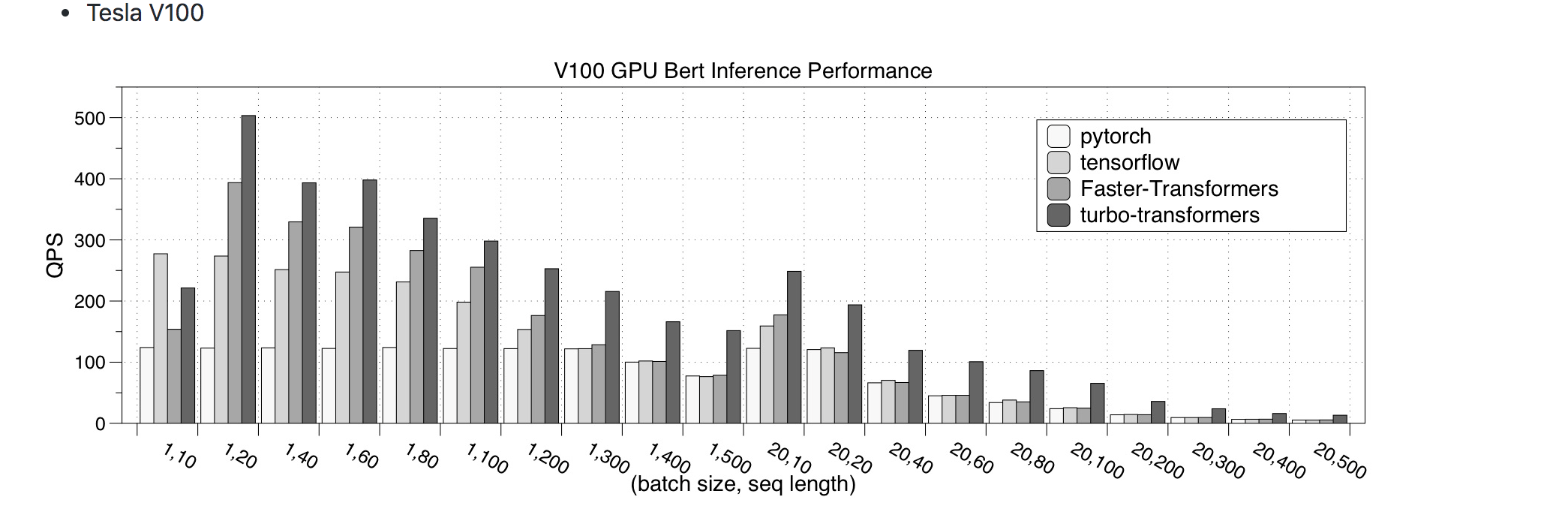 V100上的QPS,越高代表框架性能越好。对比了PyTorch、TensorFlow、Faster-Transformer、turboTransformers的效果,其中turboTransformers效果最好
V100上的QPS,越高代表框架性能越好。对比了PyTorch、TensorFlow、Faster-Transformer、turboTransformers的效果,其中turboTransformers效果最好
🚀邱锡鹏教授:NLP预训练模型综述
1.引言
随深度学习的发展,多种神经网络都被应用在 NLP 任务中,比如 CNN、RNN、GNN 和 attention 机制等,但由于现有的数据集对于大部分有监督 NLP 任务来说都很小,因此,早期的模型对 NLP 任务来说都很“浅”,往往只包含 1-3 层。
而预训练模型(Pre-trained Models, PTMs)的出现将NLP带入一个新的时代,更“深”的模型和训练技巧的增强也使得 PTMs 由“浅”变“深”,在多项任务都达到了 SOTA 性能。
近日,复旦大学的邱锡鹏老师等人发布了预训练模型综述 *Pre-trained Models for Natural Language Processing: A Survey*,从背景、分类到应用与前景对 PTMs 做了详细而全面的调研。

论文标题:Pre-trained Models for Natural Language Processing: A Survey
论文链接: https://arxiv.org/abs/2003.08271
2.背景
2.1 语言表示学习
对于语言来说,一个好的表示应当描绘语言的内在规则比如词语含义、句法结构、语义角色甚至语用。
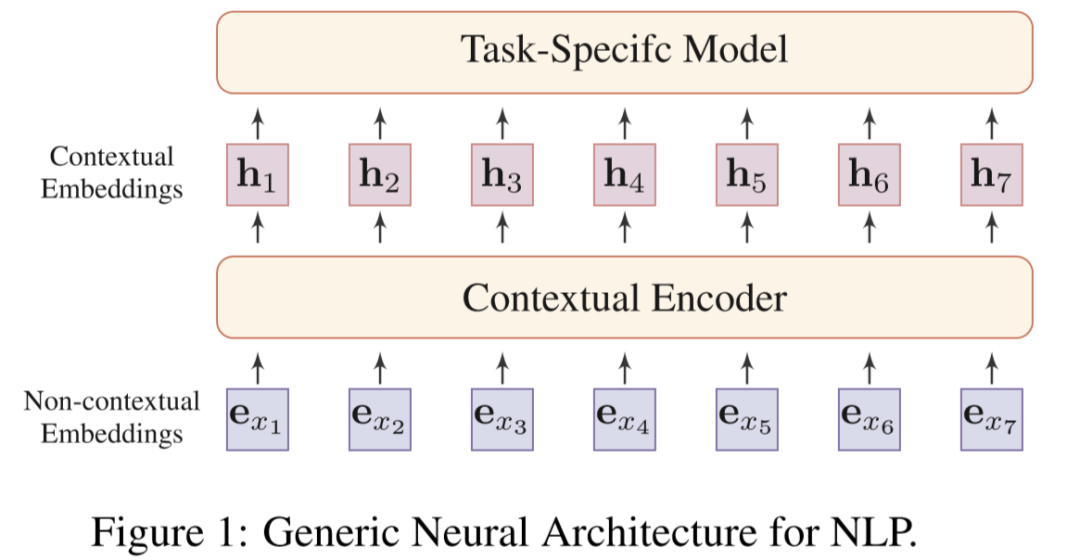
而分布式表示的核心思想就是通过低维实值向量来描述一段文本的意义,而向量的每一个维度都没有对于意义,整体则代表一个具体的概念。图 1 是 NLP 的通用神经体系架构。
有两种 embedding(词嵌入)方式:上下文嵌入和非上下文嵌入,两者的区别在于词的 embedding 是否根据词出现的上下文动态地改变。
非上下文嵌入:表示语言的第一步就是将分离的语言符号映射到分布式嵌入空间中。也就是对于词汇表中的每个单词(词根),通过 lookup table 映射到一个向量。
这种嵌入方式有两个局限:一是一个词通过这种方法获得的词嵌入总是静态且与上下文无关的,无法处理多义词;二是难以解决不在词汇表中的词(针对这个问题,很多 NLP 任务提出了字符级或词根级的词表示,如 CharCNN、FastText、Byte-Pair Encoding (BPE))。
上下文嵌入:为解决多义性和上下文相关的问题,将词在不同上下文的语义做区分。通过对词(词根)的 token 加一层 Neural Contextual Encoder(神经上下文编码器)得到词的上下文嵌入。
2.2 神经上下文编码器
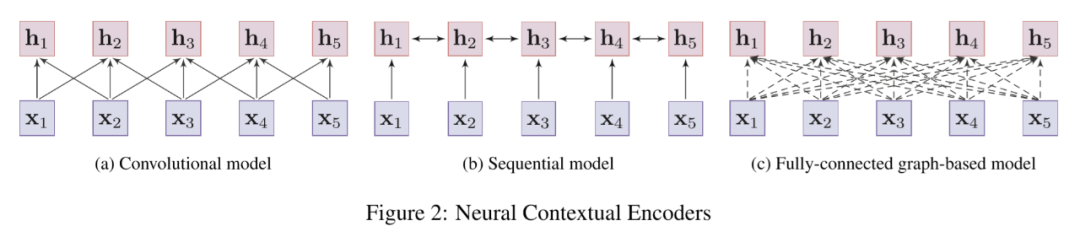
如图 2 中所示,大部分的神经上下文编码器都可以被分为三类:卷积模型、序列模型、基于图的模型。
卷积模型 :卷积模型通过卷积操作将输入句子中的 embeddings 与其相邻的局部信息集成。
序列模型 :序列模型通常使用 RNN(如 LSTM 和 GRU)来描述词的上下文表示。实践中,双向 RNN 常用于收集词的两边信息,但表现往往会受到长程依赖问题的影响。
基于图的模型 :基于图的模型将词视做节点,通过预先定义的语言结构(如句法结构和语义联系)来学习上下文表示。但如何构造一个好的图结构往往严重依赖于专家知识和外部 NLP 工具,如依存分析器。
实际操作中往往直接通过一个全连接图来建模并让模型自己学习结构(一般通过自注意力机制)。一个典型的成功运用就是 Transformer。
分析:卷积模型和序列模型都很难解决词之间的长程依赖问题,而 Transformer 虽然能更好地描述词之间的深层联系,却往往需要非常大的语料来训练,且容易在中等规模的数据集上过拟合。
2.3 为什么要预训练?
正如上文提到的,模型参数的数量增长迅速,而为了训练这些参数,就需要更大的数据集来避免过拟合,而大规模的标注数据集成本又非常高。而相比之下,大规模未标注的语料却很容易构建。
为了利用大量的未标注文本数据,我们可以先从其中学习一个好的表示,再将这些表示用在别的任务中。这一通过 PTMs 从未标注大规模数据集中提取表示的预训练过程在很多 NLP 任务中都取得了很好的表现。
预训练的优点可以总结为以下三点:1 在大规模语料上通过预训练学习通用语言表示对下游任务很有帮助;2) 预训练提供了更好的模型初始化参数,使得在目标任务上有更好的泛化性能和更快的收敛速度;3) 预训练是一种有效的正则化方法,能够避免在小数据集上过拟合。
3.PTMs概述
PTMs 的主要区别在于上下文编码器的使用、预训练任务和目标。上下文编码器已在 2.2 中做了叙述,接下来对预训练任务进行分析,并提出一种 PTMs 分类方法。
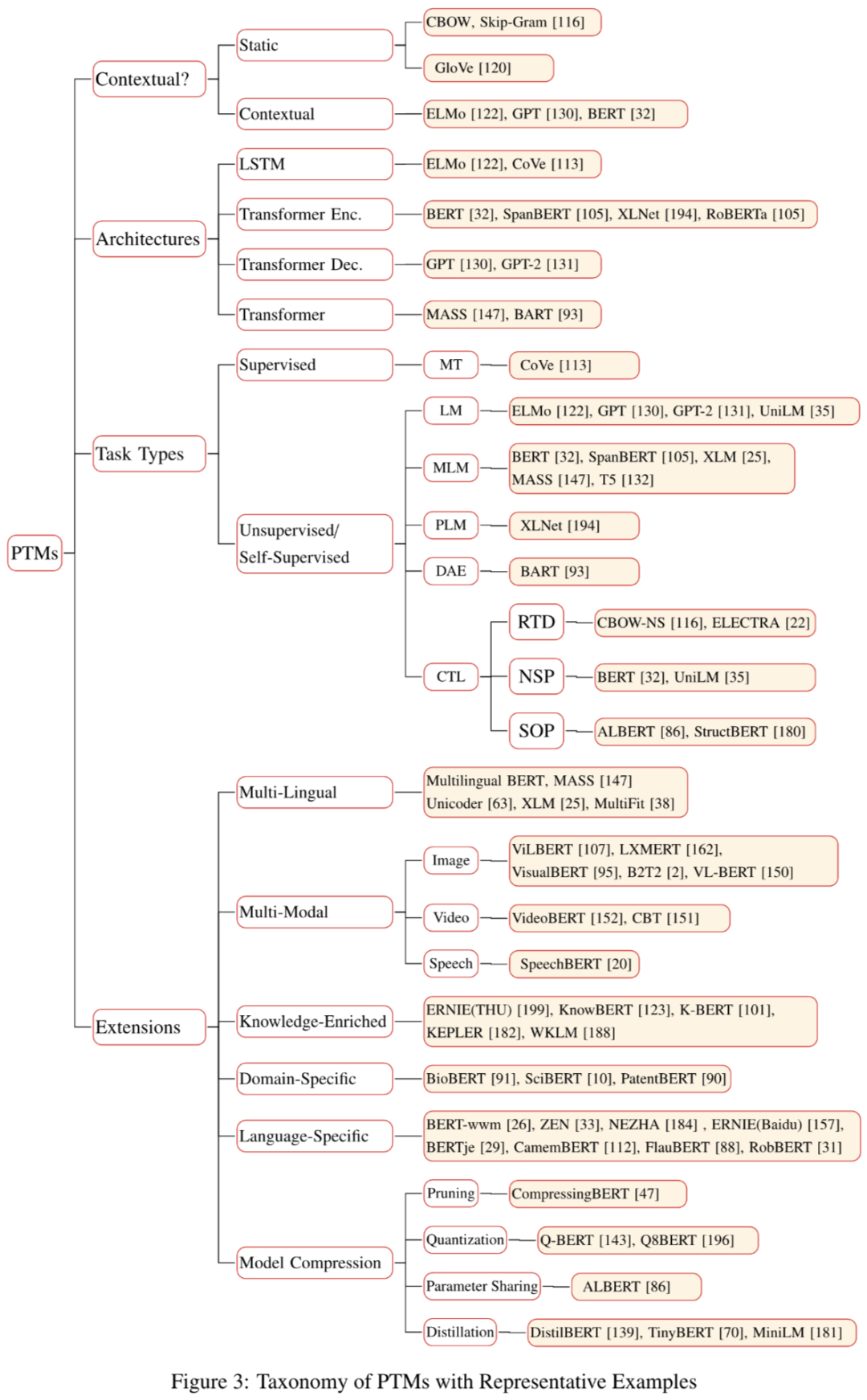
如图 3,这一部分内容作者在文中有一张非常详细的分类图可供参考。
表 1 从多个角度区分了文中提到的一些 PTMs。
3.1 预训练任务
PTMs 按照预训练任务类型可以被分为两类:有监督学习、无监督学习/自监督学习。
有监督学习的预训练任务主要有机器翻译 (MT),典型的模型是 CoVe。而下文进一步根据实现思路将自监督/无监督任务分为两类,一是基于上下文的 (LM, DAE, PLM),二是基于对比的 (CTL)。
3.1.1 语言模型 (LM)
作为 NLP 中最常见的无监督任务,LM 一般指自回归 LM (auto-regressive LM) 或者单向 LM (unidirectional LM)。具体训练过程是基于一个大的语料,通过最大似然估计 (MLE) 训练计算一个句子出现的概率。
然而单向 LM 的缺点则是只能编码一个词左侧的文本和其自身,而更好的上下文应该编码左右两侧的文本。针对这一缺点,解决方案是双向 LM (BiLM),即一个从左到右和一个从右到左的模型的组合。
3.1.2 去噪声自编码器 (Denoising Autoencoder, DAE)
这里将原文中 Masked Language Modeling (MLM) 与 DAE 合并为一个部分,因为一般将 BERT 中提出的 MLM 看作是基于 DAE 的思路实现的。
DAE 的目的是通过向输入文本中添加噪声,利用含噪声的样本去重构不含噪声的输入。主要有五个实现方式:挡住 (MASK) token、删除 token、填充 token、句子排列、文本轮换。
MLM 随机选出一些词用 [MASK] 标记,然后去预测被 MASK 的词。但由于被 MASK 的词并不出现在 fine-tuning 的过程中,会导致预训练和微调的过程出现不一致性。针对这种情况,BERT 通过 80% [MASK],10% 随机 token,10% 原 token 的方式来进行 mask。
而 MLM 的一种变体,Seq2SeqMLM,则是通过将 encoder-decoder (Seq2Seq) 应用到 MLM 上,这种变体有利于 Seq2Seq 类型的下游任务,比如 QA,总结和机器翻译。这一结构主要用在 MASS 和 T5 中。
而在 BERT 之后的很多论文都对 MLM 做了一些改进以增强性能,作者将其总结为 E-MLM (Enhanced Masked Language Modeling)。
其中 RoBERTa 使用动态 masking,UniLM 将对 mask 的预测扩展到三种任务:单向、双向和 Seq2Seq。XLM 通过一种串联并行双语句对叫做 TLM (translation language modeling) 的模型实现 MLM。
而 SpanBERT 和 StructBERT 则是引入了结构化信息。而 ERINE (Baidu) 则是选择 MASK 实体和短语,E-BERT 和 ERINE (THU) 则是利用了实体 embedding 方法,这三者都是借助了外部知识来丰富 MLM。
3.1.3 排列语言模型(PLM)
针对 MLM 中使用 MASK 导致的预训练与微调过程的不一致,Permuted Language Modeling (PLM) 对于一个给定序列,生成其所有可能排列进行采样作为训练的目标。值得注意的是,PLM 并不改变原始文本的位置,而是重新定义 token 预测的顺序。
3.1.4 对比学习(CTL)
CTL (Contrastive Learning) 基于一种“learning by comparison”的思路,假设某些观测文本对比随机采样文本在语义上更相似,通过构建正样本和负样本并度量距离来实现学习。CTL 通常比 LM 具有更少的计算复杂度,也因此成为一个值得选择的 PTMs 训练标准。
3.1.5 Deep InfoMax (DIM)
DIM 最初是在 CV 领域提出的用于最大化图像全局特征与局部特征之间的互信息(Mutual Information)的方法。
InfoWord 将 DIM 引入到语义表达学习中,提出用 DIM objective 以最大化句子的全局表示和一个 N-gram 的具备表示之间的互信息。
噪声对比估计(Noise-Contrastive Estimation,NCE)通过训练一个二元分类器来区分真实样本和假样本,训练词嵌入。NCE 的思想也被用在 word2vec 中。
3.1.6 Replaced Token Detection (RTD)
RTD 和 NCE 大体相同,根据上下文来预测 token 是否替换。
CBOW 的 negetive sampling 就可以看作是一个 RTD 的简单版本,其中采样是根据词汇表中的分布进行采样。
ELECTRA 基于 RTD 提出了一种新的 generator-discriminator 框架。首先用 MLM 任务训练 generator,再用 generator 的权重初始化 discriminator,再用判别任务(判别哪些 token 被 generator 替换过)训练 discriminator。
最终在下游任务只需要对 discriminator 进行 fine-tuning。TRD 也是一种很好的解决 MLM 导致的不一致问题的方法。
WKLM 则是通过在实体层面(entity-level)进行词替换,替换为同一个实体类型的实体名。
3.1.7 Next Sentence Prediction (NSP)
NSP 训练模型区分两个输入语句是否为训练语料中连续的片段,在选择预训练句对时,第二个句子 50% 是第一个句子实际的连续片段,50% 是语料中的随机段落。NSP 能够教会模型理解两个输入句子之间的联系,从而使得如 QA 和 NLI 这种对此类信息敏感的下游任务受益。
然而,近来 NSP 的必要性也遭到了质疑,XLNet 的作者发现不用 NSP loss 的单句训练优于使用 NSP 的句对训练。RoBERTa 的作者进一步分析表明:在对单个文本中的文本块训练时,去除 NSP 会在下游任务稍微提高性能。
3.1.8 Sentence Order Prediction (SOP)
NSP 结合了主题预测相关性预测,而因为主题预测更容易,模型将更依赖于主题预测。为更好建模句子之间的相关性,ALBERT 提出使用 SOP loss 替换 NSP loss,SOP 使用一个文档中的两个连续片段作为正样本,将这两个片段交换顺序作为负样本。
采用了 SOP 的 ALBERT 在多项下游任务中结果都优于 BERT。StructBERT 和 BERTje 也使用 SOP 作为自监督学习任务。
3.2 PTMs的拓展
3.2.1 引入知识的PTMs
通常 PTMs 都是用大量语料训练通用的语言表示,而将外部的领域知识引入到 PTMs 被证明式有效的。自 BERT 以来,就有很多预训练任务用以将外部知识纳入 PTMs,如:
LIBERT:linguistically-informed BERT ,通过附加语言约束任务纳入了语言知识。
SentiLR:通过对每个单词添加情感极性,将 MLM 拓展至 Label-Aware MLM (LA-MLM),在多个情感分类任务达到 SOTA。
SenseBERT:不仅能预测被 mask 的 token,还能预测 WordNet 中的 supersense。
ERINE (THU):将知识图谱中预训练的实体嵌入与文本中相应的实体提及相结合,以增强文本表示。
KnowBERT:端到端将带实体连接模型与实体表示集成。
KEPLER:将知识嵌入和语言模型对象联合。
K-BERT:不同于以上几个模型通过实体嵌入引入知识图谱中的结构化信息,K-BERT 通过直接将知识图谱中相关三元组引入句子,获得一个 BERT 的拓展的树形输入。
K-Adapter:针对不同预训练任务独立训练不同的适配器以引入多种知识,以解决上述模型在注入多种知识出现的遗忘问题。
3.2.2 多模态PTMs
随 PTMs 在 NLP 领域的广泛应用,一些多模态 PTMs 也被设计出来,在一些语音、视频、图像数据集上进行了预训练,比如:
- 视频-语言:VideoBERT、CBT
- 图像-语言:用于 visual question answering (VQA) and visual commonsense reasoning (VCR),如 ViLBERT、LXMERT、VisualBERT、B2T2、VLBERT、 Unicoder-VL、UNITER
- 音频-文本:用于端到端 Speech Question Answering (SQA) 任务,如 SpeechBERT
3.2.3 领域预训练PTMs
大多数 PTMs 都是在 Wikipedia 这样的通用领域语料库上训练的,这就限制了他们在特定领域内的表现。
近期有一些用专业领域语料训练的 PTMs,比如:生物医学领域的 BioBERT,科学领域的 SciBERT,临床医学领域的 ClinicalBERT。还有一些工作尝试将预训练模型更好地使用目标应用,比如生物医学实体归一化、专利分类等。
3.2.4 多语言与特定语言PTMs
学习多语言文本表示对于跨语言 NLP 任务是很重要的。早期工作着力于学习来自同一语义环境下的多语言词嵌入,这一方法往往缺乏语言间的校准。近期有如下几个多语言 PTMs:
Multilingual-BERT:M-BERT,在 Wikipedia 上 104 种种语言的文本上进行 MLM 训练,每个训练样本都是单语言的,也没有专门设计跨语言目标,但即便如此,M-BERT 在跨语言任务上表现还是非常好。
XLM:通过结合跨语言任务 TLM (translation language modeling),提升了 M-BERT 的性能。
Unicoder:提出三个跨语言预训练任务:1) cross-lingual word recovery; 2) cross-lingual paraphrase classification; 3) cross-lingual masked language model。
除此之外还有一些单语言的 PTMs:BERT-wwm,ZEN,NEZHA,ERNIE (Baidu),BERTje,CamemBERT, FlauBERT ,RobBERT 。
3.3 如何压缩PTMs
预训练模型往往包含至少几千万个参数,这也使得模型难以部署到生活中的线上服务以及资源有限的设备上,这就使得模型压缩成为一条可能能够压缩模型尺寸并提高计算效率的方法。表 2 展示了一些压缩的 PTMs 的对比。
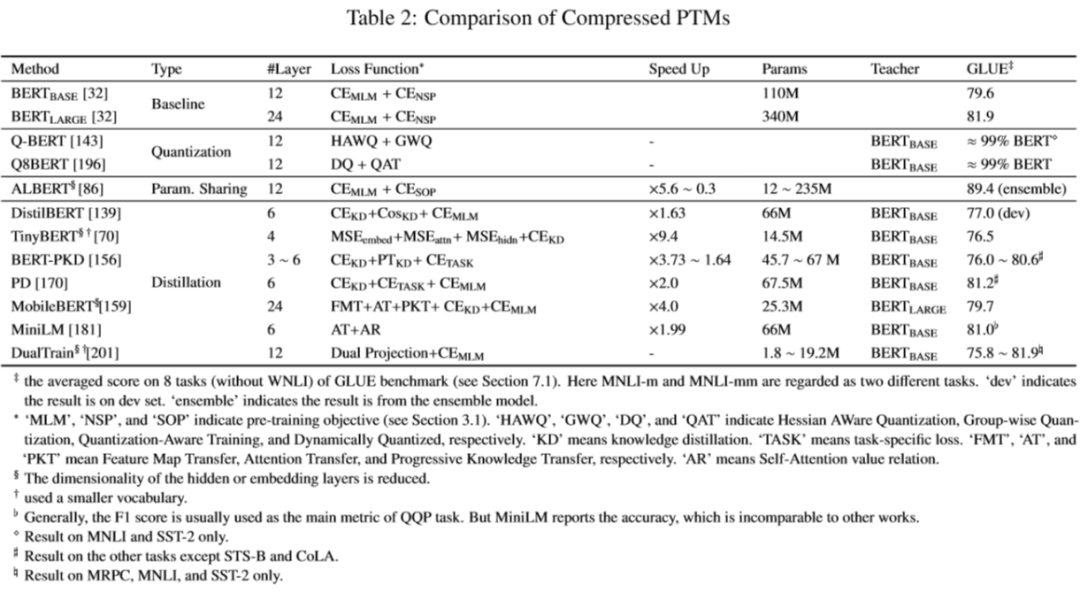
压缩 PTMs 一般有四个方法:
- 剪枝(pruning):去除不那么重要的参数(e.g. 权重、层数、通道数、attention heads)
- 量化(weight quantization):使用占位更少(低精度)的参数
- 参数共享(parameter sharing):相似模型单元间共享参数
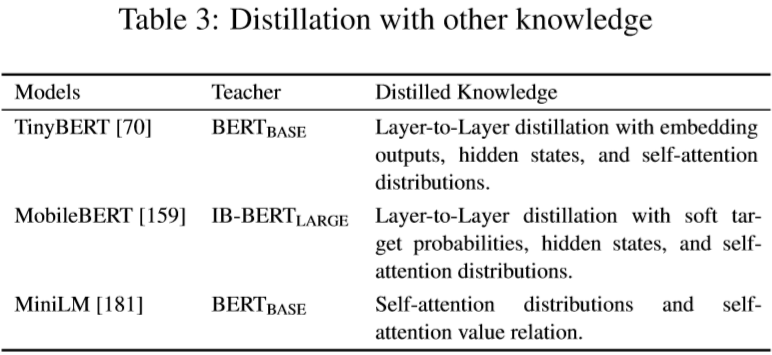
- 知识蒸馏(knowledge diistillation):用一些优化目标从大型 teacher 模型学习一个小的 student 模型,一些利用知识蒸馏的 PTMs 见表 3。
4.如何将PTMs应用至下游任务
4.1 迁移学习
迁移学习就是将源任务中的知识适应到目标任务,将 PTMs 适应到下游任务是一种顺序迁移学习任务。那么,如何迁移呢?我们需要考虑以下几个问题:
- 选择合适的预训练任务:近期,LM 是最流行的预训练任务,也有效解决了很多 NLP 问题。但不同的预训练任务在不同的下游任务上有不同的效果,比如 NSP 任务能帮助 PTM 理解句子之间的关系,因此 PTM 对于 QA 和 NLI 这样的下游任务很有帮助。
- 选择合适的模型架构:比如 BERT 使用的 MLM 和 Transformer 结构使其擅长 NLU 任务,却很难生成语言。
- 选择合适的语料:下游任务的数据应该接近 PTMs 的预训练任务。
- 选择合适的layers:在“深”的预训练模型中,不同的 layer 往往描绘不同种类的信息。有三种选择 layers 的方式:1) 只用 Embedding,如 word2vec 和 Glove;2) Top Layer,如 BERT;3) All Layers,如 ELMo。
- 是否进行fine-tune:模型迁移一般有两种方法:特征提取和 fine-tuning。特征提取的参数是冻结的,且往往需要特定任务的体系结构。fine-tunig 的参数是非冻结的,比特征提取方法更为通用且方便。
4.2 fine-tuning的策略
自 ULMFit 和 BERT 起,fine-tuning 已经成为 PTMs 主要的适配方法。这里有一些实用的 fine-tunig 策略:
- 两阶段 fine-tuning:两阶段迁移的方法在预训练和 fine-tuning 阶段引入了一个中间阶段。在第一阶段,通过中间任务或语料来微调模型。在第二阶段,通过目标任务微调模型。
- 多任务 fine-tuning:liu等人在多任务学习框架下对 BERT 进行了微调,结果显示多任务学习和预训练是互补的方法。
- 采用额外的适配器 fine-tuning:fine-tuning 的主要缺点是参数效率低,在每一个下游任务上都有各自的 dine-tuning 参数。对此的解决方案是在固定原始参数时引入一些可以 fine-tuning 的适配器。
- 其他:逐层解冻而非连续 fine-tune 所有层;self-ensemble 和 self-distillation
5.一些PTMs的资源
一些开源的应用:
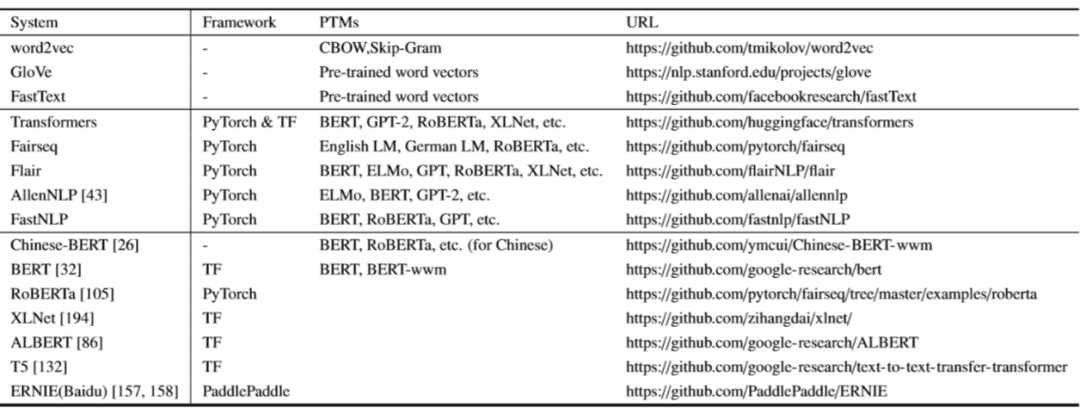
word2vec:
https://github.com/tmikolov/word2vec
GloVe:
https://nlp.stanford.edu/projects/glove
FastText:
https://github.com/facebookresearch/fastText
Transformers:
https://github.com/huggingface/transformers
Fairseq:
https://github.com/pytorch/fairseq
Flair:
https://github.com/flairNLP/flair
AllenNLP:
https://github.com/allenai/allennlp
FastNLP:
https://github.com/fastnlp/fastNLP
Chinese-BERT:
https://github.com/ymcui/Chinese-BERT-wwm
BERT:
https://github.com/google-research/bert
RoBERTa:
https://github.com/pytorch/fairseq/tree/master/examples/roberta
XLNet:
https://github.com/zihangdai/xlnet/
ALBERT:
https://github.com/google-research/ALBERT
T5:
https://github.com/google-research/text-to-text-transfer-transformer
ERNIE (Baidu):
https://github.com/PaddlePaddle/ERNIE
相关资源:
论文列表:
https://github.com/thunlp/PLMpapers
https://github.com/tomohideshibata/BERT-related-papers
https://github.com/cedrickchee/awesome-bert-nlp
BERT Lang Street(收集 BERT 在不同数据集和任务上的表现):
https://bertlang.unibocconi.it/
BERTViz(应用 transformer 的模型的注意力可视化):
https://github.com/jessevig/bertviz
6.应用
6.1 通用评估标准
GLUE (The General Language Understanding Evaluation) 标准是一个集合了 9 个自然语言理解任务的标准。
其中包括:单个句子分类任务(CoLA和SST-2)、文本对分类任务(MNLI, RTE, WNLI, QQP, MRPC)、文本相似度任务(STSB)、相关性排行任务(QNLI)。GLUE 标准能够能够很好地评估模型的鲁棒性和通用性。
而近期 NLP 的快速发展促使了新的标准 SuperGLUE 的提出,相比 GLUE,SuperGLUE 有更多富有挑战性且多种多样的任务,如指代消解和 QA。
6.2 机器翻译
机器翻译(Machine Translation, MT)也是 NLP 的一项重要任务。几乎所有 MT 模型都使用了 encoder-decoder 框架。而近期随预训练模型的发展,也有不少尝试将 BERT 之类的预训练模型用于初始化 encoder,取得了一定成效。
6.3 问答系统
问答系统(Question answering, QA)或是狭义概念的机器阅读理解(machine reading comprehension, MRC)也是 NLP 的重要任务。
从易到难,有三种类型的 QA 任务:单回合提取 QA (single-round extractive QA, SQuAD)、多回合生成QA (multi-round generative QA, CoQA)、多跳问答 (multi-hop QA, HotpotQA)。
针对提取 QA,有通过 PTM 初始化 encoder 的回溯阅读架构(retrospective reader architecture);针对多回合生成 QA,有“PTM+Adversarial Training+Rationale Tagging+Knowledge Distillation”架构;针对多跳 QA,有“Select, Answer, and Explain” (SAE) 系统。
6.4 情感分析
BERT 通过在广泛使用的情感分析数据集 SST-2 上进行微调后,表现超过了先前的 SOTA 模型。而后又有很多将 BERT 进行调整以应用在 aspect 级的情感分析(ABSA)任务上。
6.5 总结
从长文本中总结出短文本也是近期 NLP 的热点。也有很多尝试将 PTM 应用在总结文本任务上,如将 BERT 通过插入 [CLS] token 来学习句子表示的模型 BERTSUM。
6.6 命名实体识别
命名实体识别(Named Entity Recognition, NER)也是知识提取的一个基础任务,在很多 NLP 任务上都有重要作用。TagLM 和 ELMo 利用预训练语言模型的最后一层的输入和各层的加权总和作为词嵌入的一部分。
7.未来方向
7.1 PTMs的上界
随 BERT 的出现,我们可以发现,很多模型都可以通过更长的训练步长不在和更大的语料来提升性能,比如去年的 T5 使用的 C4 数据集。而我们也可以通过加深模型来提升性能,比如 Turing-NLG 使用了 72 个 transformer 层。
PTMs 的共同目标都是学习语言的本质通用知识(或者说是世界的知识),然而,随着模型的不断加深,语料的不断增大,训练模型的花销也越来越大。一种更可行的解决方案是设计更有效的模型架构、自监督预训练任务、优化器和软硬件方面的技巧等。ELECTRA 就是这个方向上一个很好的尝试。
7.2 面向任务的预训练与模型压缩
在实践中,不同的下游任务要求 PTMs 拥有不同的功能。而 PTMs 与下游目标任务间的差异通常表现在两方面:模型架构与数据分布。较大的 PTMs 通常情况下会有更好的性能,但实际问题是如何在低容量设备和低时延应用上使用如此庞大的 PTM。
除此之外,我们可以通过模型压缩来将通用 PTMs 教给面向对象的 PTM。尽管 CV 中对 CNNs 的压缩已经非常成熟,但 Tansformer 的全连接结构使得模型压缩非常具有挑战性。
7.3 PTMs架构
Transformer 是 PTMs 的一个高效的框架,但 Transformer 的局限在于计算复杂度。由于 GPU 显存大小的限制,目前大多数 PTM 无法处理序列长度超过 512 个 token 的序列。搭配这一限制需要改进 Transformer 的结构,如 Transformer-XL。因此,寻求更有效的模型架构对于解决长程文本信息也是很重要的。
7.4 Fine-tunig中的知识迁移
Fine-tuning 是目前将 PTM 的知识迁移至下游任务的主要方法,但参数效率却很低,每个下游任务都有特定的 fine-tuned 参数。
一个可以改进的解决方案是固定 PTMs 的原始参数,并为特定任务添加小型的可微调的适配器,这样就可以在不同的下游任务使用共享的 PTMs。从 PTM‘s 中挖掘知识也可以更灵活,比如:知识提取、知识蒸馏、数据增加、将 PTMs 作为外部知识等等。
7.5 PTMs的可解释性与可靠性
PTMs 的深且非线性的架构使得决策制定的过程非常不透明。近期,可解释人工智能(explainable artificial intelligence, XAI)成为热点。通过对模型词嵌入的研究我们可以分析 PTMs 中的语言和世界知识,但更多有关注意力机制的可解释性的问题还值得探讨。
PTMs 这种深模型很容易受到对抗样本的扰动而产生错误的预测。在 CV 领域,对抗攻击与防御已经被广泛学习,而由于语言的特性,文本的对抗还非常具有挑战性。PTMs 的对抗防御也对于提升 PTMs 的鲁棒性很重要。
8.总结
邱锡鹏老师的这篇综述很全面地概括了预训练模型,也非常适合初学者当作一个 roadmap 来阅读。我们可以看到 NLP 的发展过程是非常令人感动的,从最开始的“要表示语言”的目标,使用词袋模型和 N-gram。
再想到“词语具有多义性”,所以需要有上下文,使用 LSTM。LSTM 只有单向,那就使用双向 LSTM。“想要更大范围的上下文”,就产生了 transformer。
“再大一些”,有了 transformer-XL。还是不够好,怎么办?“更多知识”,于是不断加大语料库,不断堆 GPU,直到 T5 探索了“Limits of Transfer Learning with a Unified Text-to-Text Transformer”。
模型太大,成本太高,那就压缩模型,改进框架,于是有了 ELECTRA。预训练模型缺乏尝试推理能力,那就知识提取,于是有了 COMET。每一步尝试都是在靠近语言的本质与世界的知识。
“The whole of science is nothing more than a refinement of everyday thinking.”
