
EMNLP 2020
code url (official torch) : https://github.com/ChunyuanLI/Optimus
被引用次数:9
背景
在NLP领域中,VAE是一个很有效的生成模型和表示学习框架
PLM(Pre-trained language models)一般可以分为两种。(1)基于transformer的encoder的BERT, 用于自然语言理解任务。它能够输出一个上下文的表示信息,用于下游任务;(2)基于transformer的decoder的GPT-2,用于自然语言生成任务。它能够以自回归的方式产生文本序列(机器翻译)
问题
前人想着去结合语言理解任务和语言生成任务,如UniLM、T5模型,效果有提升,但是这些模型缺少一种在紧密(compact)空间(低维空间)中显式的建模,导致很难在一个abstract level去控制语言的生成和表示

VAE可以克服这种局限性,可以生成higher-level 的句子表示,从而控制low-level 的word-by-word generation。
但是目前VAE都是应用在浅层的模型中,例如two-layer LSTMs ,这限制了模型的表现
解决
提出了OPTIMUS, the first large-scale pre-trained deep latent variable models for natural language. ,一个统一的潜在编码空间在大型文本库(large text corpus)训练完之后,在多个下游任务(自然语言理解、自然语言生成)中进行微调
以下是OPTIMUS的优点,它结合了BERT和GPT-2的优势,用于处理自然语言任务,同时相比于BERT和GPT-2,克服了它们的局限性


贡献
提出首个大规模预训练隐变量生成模型OPTIMUS;
高效地将隐变量和预训练的GPT-2相结合( Latent vector injection),提出两种结合方法;
发现大规模预训练可以减缓KL Vanishing的问题;
在多个任务上取得显著的效果。
模型
目标函数
一般的自然语言模型(如GPT-2)的生成目标,依靠前面的输出的token来预测后面的token,通常训练是通过maximum likelihood estimate (MLE). 但是这样也有局限性,前面已经提到了
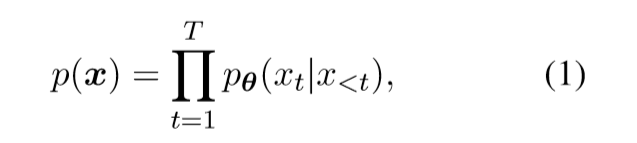
在生成阶段(训练阶段),模型的生成基于隐变量z,对于给定的文本x,VAE的生成目标,相比于公式(1)多了一个条件z,即显式地依赖z。
z是高层次的语义特征,来指导生成低层次的x,即句法和词汇
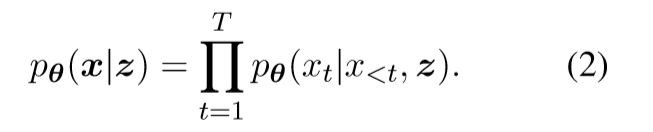
这里θ表示的是用于文本生成的解码器。而隐变量是通过一个编码器得到的,可以形式化为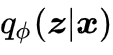
此时的证据下界(ELBO)就是
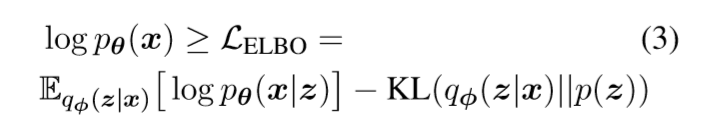
在本文中,添加了一个超参β, 用于控制训练过程。
所以目标函数可以转化为如下形式,Lβ

LE是重构损失( (or negative log-likelihood(NLL)), LR是KL散度(正则项),用于让生成的z逼近先验p(z)
模型架构
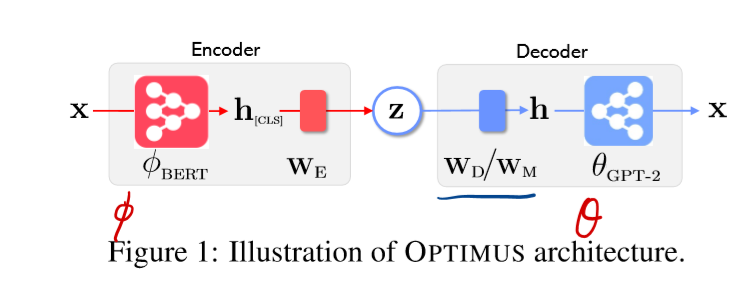
可以看出来,模型架构比较简单,但是一些细节也要考虑一下
基本流程如下:
1.使用预训练好的BERT和GPT-2参数,用于OPTIMUS模型encoder和decoder参数的初始化;
此时BERT(L=12,H=768,A=12,Total Parameters=110M) and GPT-2 (L=12,H=768, A=12,,Total Parameters=117M),其中L表示transformer block的层数;H表示中间隐藏层的维度;A表示自注意力头的个数
可以发现,BERT和GPT-2的超参L、H、A都是一样的
- 对于初始化后的OPTIMUS,在大型文本库(large text corpus)的训练集下进行预训练
- 预训练完OPTIMUS,再在具体的下游任务上进行微调
Connecting BERT & GPT-2
同时在连接BERT和GPT-2中,存在一些问题
问题1 Tokenization(如何分词)
BERT和GPT-2采取了不同的分词方法,如何去表示句子?
解决
在BERT中用的是Word Piece Embeddings (WPE)分词方法,在GPT-2中, 用的是 Byte Pair Encoding (BPE),
本文中同时采取了两种方法

等于没说。。。
是否可以统一分词方法 ?
问题2 融合隐变量和GPT-2
如何高效地将Z融合进GPT-2中?
解决
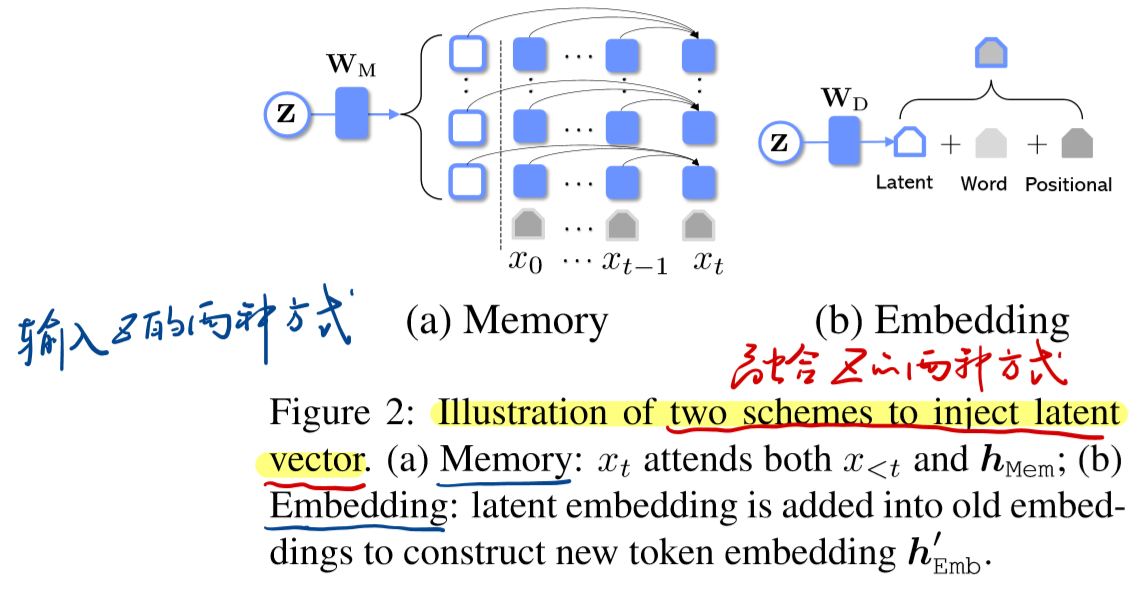
该如何把隐变量z提供给解码器呢?
本文提供两种方法,分别为记忆(Memory)和嵌入(Embedding):

经过实验验证,使用Memory比Embedding方法更有效,作者给出理由如下,就是Memory能够使得decoder在每一层都能直接获得潜在信息,而Embedding只能在输入输出才能获得信息。 Memory能从潜在信息中获得更多的信息用于生成任务

在本文中,默认Memory和Embedding方法一起使用
OPTIMUS的预训练
存在一个问题,就是当VAE和auto regressive models在一起训练时,会出现“KL-vanishing problem”,或者说是“posterior collapse”
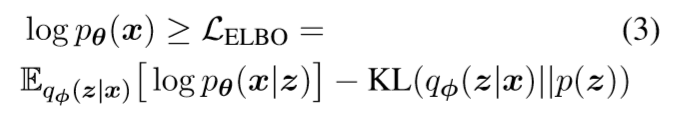
ELBO 包含reconstruction loss和KL loss两部分。我们的目标是最大化ELBO,等价于最小化KL项并最大化reconstruction项。存在如下问题:
问题1.对于reconstruction部分,当扮演p(x|z)角色的decoder足够强大,仅凭自己就可以model q(x)分布,那么也没有必要去依赖z。
问题2.对于KL项,如果简单的将data x和latent variable z无关并让q(z|x) = q(z) = p(z),即posterior退化为和prior一样的高斯,KL就可以取得最小值0。
所以针对上述问题,本文在预训练的时候做了如下优化:
对β使用循环调度(cyclical schedule),一共10个 periods 来加强β的作用;
每一个 period中,在训练的前一半,设置β=0 只训练encoder,避免了上述问题1;对后一半的前一半,将其增长到1,对最后四分之一,固定为1;
当β≠0的时候,加入KL thresholding scheme (KL 阈值),保证KL项始终大于一个常数 λ,这样可以避免了上述问题2,避免LR项取得最小值0。此时LR被替换为 hinge loss
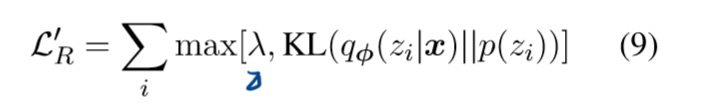

实验
预训练OPTIMUS之后,剩下的就是对不同的任务进行微调了。本文在三类任务上实验:语言模型、受限文本生成和自然语言理解

总结
VAE和PLM在自然语言处理中都是很重要的部分,自然会想到将二者结合起来
总体来说,论文没太多创新点,而且在正文部分有些故弄玄虚,明明一个很简单的概念,说的让人无法理解,非要绕个弯子,可能这样会让人觉得更高深些吧,但是对于后来的研究者来说很痛苦
代码还没有看,准备再读读代码,加深模型的理解
更改方向
1.用更好的方法去解决KL vanishing 问题
2.统一分词方法是否有更好的结果
3.使用最新的VAE方法/PLM方法去解决问题
4.结合T-CVAE框架
5.因为NLP模型普遍对于对抗攻击很敏感,所以增加对抗思想,提高模型的鲁棒性。结合论文《Adversarial Training for Large Neural Language Models》(ACL 2020)中的通用算法ALUM去解决对抗攻击的问题
参考
OPTIMUS https://zhuanlan.zhihu.com/p/143517152
KL vanishing https://zhuanlan.zhihu.com/p/64071467
