
ACL 2020
code url (official torch) : https://github.com/namisan/mt-dnn
被引用次数:11
背景
泛化性和鲁棒性对于机器学习来说是很重要的,对抗训练可以增强鲁棒性,但是同时也会使泛化性受到损失;
BERT等大型自然语言模型已经在泛化性方面取得了巨大的进步,然而这种预训练模型容易受到对抗攻击
问题
如何使得大型NLP模型兼得泛化性和鲁棒性?
解决
提出了一种通用算法ALUM (Adversarial training for large neural Language Models), 把对抗训练用到了预训练和微调两个阶段,通过对抗训练来提高模型的泛化性和鲁棒性。
对抗训练的方法是针对embedding space,通过最大化对抗损失、最小化模型损失的方式进行对抗,在下游任务上取得了一致的效果提升。
这种对抗训练方法不仅能够在BERT上有提高,而且在RoBERTa这种已经预训练好的模型上也能有所提高,说明对抗训练的确可以帮助模型纠正易错点。
算法可以应用在任何基于transformer的语言模型中
贡献

模型
准备
tokenization使用的是BPE(Byte-PairEncoding)
模型基于BERT和 RoBERTa模型,但是在训练策略上与前两者有所改动如下:
在一个epoch中,掩码率以每经过20%的epoch,增加5%掩码率的增速使得掩码率从5%增加到25%

标准训练目标函数
标准的预训练和微调函数都可以认为是在训练数据上进行最小化标准差

对抗训练

ALUM算法
基于几个关键想法:
扰动embedding空间,优于直接对输入文本应用扰动。
通过虚拟对抗训练为标准目标添加正则化项。比传统的对抗训练有效果,尤其是在标签有噪声时。
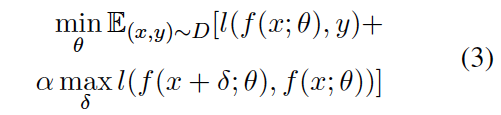
其中超参α用于调节标准差和鲁棒差的平衡
(预训练α = 10,微调α = 1)
- 因为有最大化操作,所以训练昂贵。
- 有利于embedding邻域的标签平滑。
算法流程
首先使用标准目标(1)训练模型;然后使用虚拟对抗训练(3)继续训练。


总结
本文提出了一种通用的对抗性训练算法ALUM:
对抗预训练可以显著提高泛化能力和鲁棒性。
ALUM大大提高了BERT和RoBERTa在各种NLP任务中的准确性,并且可以与对抗微调相结合以获得进一步的收益。
未来的发展方向:
- 进一步研究对抗性预训练在提高泛化和鲁棒性方面的作用;
- 对抗性训练加速;
- 将ALUM应用于其他领域。
论文提出了一个通用的模型无关的对抗训练算法架构,可以应用在任何基于transformer的语言模型中。可以尝试去结合模型
