logits
在tensorflow代码中,经常会出现logits,logits表示的含义就是在模型的最后一层输出后,进入到Softmax函数之前得到的n维向量。是feature的抽象。
logits是未归一化的概率, 一般也就是 softmax层的输入。所以logits和lables的shape一样
而softmax是在一个n分类问题中,输入一个n维的logits向量,输出一个n维概率向量,其物理意义是logits代表的物体属于各类的概率。是对logits进行归一化。
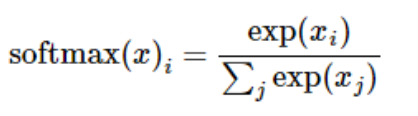
输入softmax的Logits中最大的一维会成为输出中同样最大的一维。例如:
1 | 4分类问题的 |
beam search
在sequence2sequence模型中,beam search的方法只用在测试的情况,因为在训练过程中,每一个decoder的输出是有正确答案的,也就不需要beam search去加大输出的准确率。
我们需要翻译中文“我是中国人”--->英文“I am Chinese”
假设我们的词表大小只有三个单词就是I am Chinese。那么如果我们的beam size为2的话,我们现在来解释,
如下图所示,我们在decoder的过程中,有了beam search方法后,在第一次的输出,我们选取概率最大的"I"和"am"两个单词,而不是只挑选一个概率最大的单词。
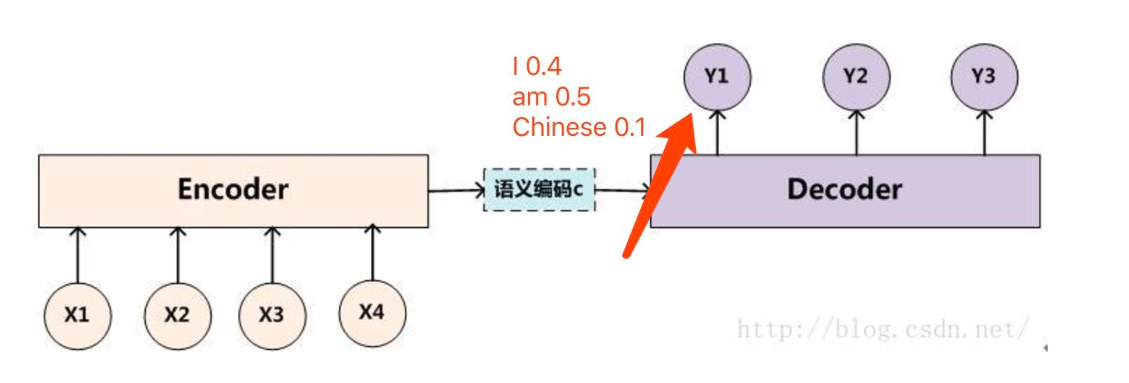
然后接下来我们要做的就是,把“I”单词作为下一个decoder的输入算一遍得到y2的输出概率分布,把“am”单词作为下一个decoder的输入算一遍也得到y2的输出概率分布。
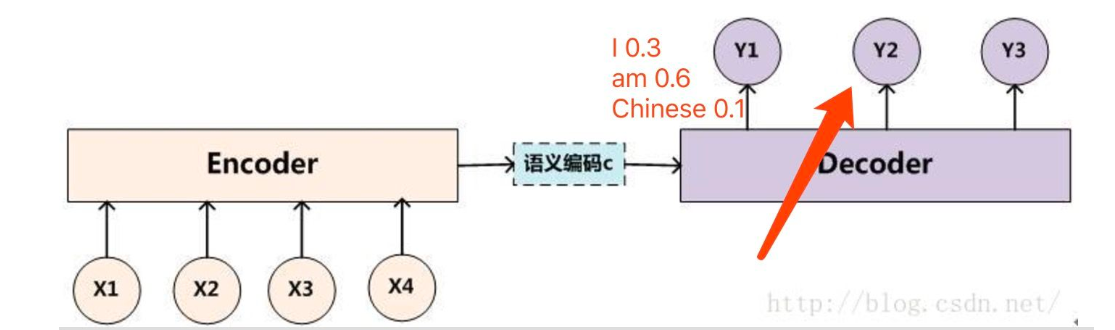
比如将“I”单词作为下一个decoder的输入算一遍得到y2的输出概率分布如下:
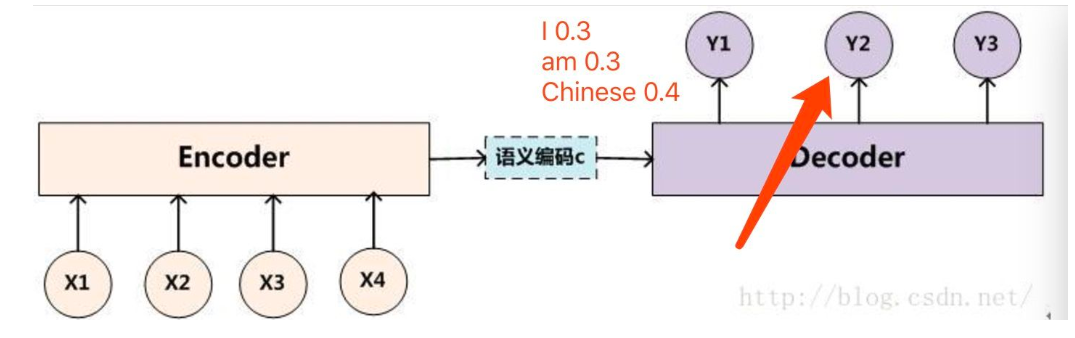
比如将“am”单词作为下一个decoder的输入算一遍得到y2的输出概率分布如下:
那么此时我们由于我们的beam size为2,也就是我们只能保留概率最大的两个序列,此时我们可以计算所有的序列概率:
“I I” = 0.40.3 "I am" = 0.40.6 "I sChinese" = 0.4*0.1
"am I" = 0.50.3 "am am" = 0.50.3 "am Chinese" = 0.5*0.4
我们很容易得出俩个最大概率的序列为 “I am”和“am Chinese”,然后后面会不断重复这个过程,直到遇到结束符为止。
最终输出2个得分最高的序列。
这就是seq2seq中的beam search算法过程
TPU -tensorflow
在神经网络学习过程中,需要进行矩阵运算,包括大量的加法和乘法,所以关键点是我们该如何快速执行大型矩阵运算,同时还需要更小的能耗。
与CPU和GPU的对比
CPU:CPU 非常灵活,硬件无法一直了解下一个计算是什么,直到它读取了软件的下一个指令。
缺点:每一个 CPU 的算术逻辑单元(ALU,控制乘法器和加法器的组件)都只能一个接一个地执行它们,每一次都需要访问内存,限制了总体吞吐量,并需要大量的能耗。
GPU:在单个处理器中使用成千上万个 ALU。现代 GPU 通常在单个处理器中拥有 2500-5000 个 ALU,意味着你可以同时执行数千次乘法和加法运算。在并行化的应用中很好,比如神经网络的矩阵乘法。
缺点:因为 GPU 在其 ALU 上执行更多的并行计算,它也会成比例地耗费更多的能量来访问内存,同时也因为复杂的线路而增加 GPU 的物理空间占用。
TPU的工作特点
TPU 不能运行文本处理软件、控制火箭引擎或执行银行业务,但它们可以为神经网络处理大量的乘法和加法运算,同时 TPU 的速度非常快、能耗非常小且物理空间占用也更小。常用于加速神经网络
TPU 可以在神经网络运算上达到高计算吞吐量,同时能耗和物理空间都很小。
参考
TPU 加速深度学习 https://www.ednchina.com/news/201809041331.html
PPT 解释了 TPU 的特性与定义 tpudemo.com
