直观“Attention 模型”
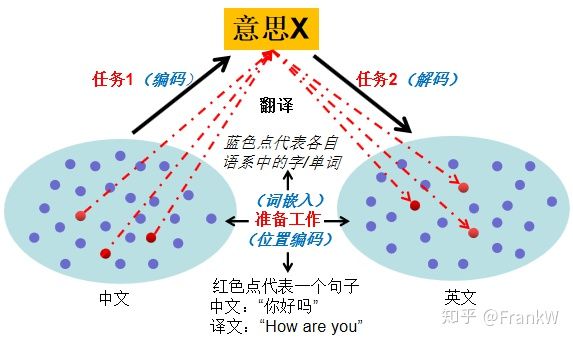
本文试着从直观的角度解析“Attention模型”,应用场景:原文--译文,具体选择 中文--英文,即在将中文翻译为英文这一场景中,直观解析“Attention模型”。
概括
一句中文A翻译为一句英文B主要是完成以下“两项任务”:
理解中文A的意思为X;
将意思X用英文表达出来,即英文B;
在用计算机完成以上任务前,需要以下三点“准备工作”:
需要将中文的字和英文的单词转换为计算机可以理解(计算)的数(即一个字/单词对应转换为一个向量,称为字向量/单词向量),然后计算机才有可能完成以上两项任务,实现翻译;
单词->单词向量另外针对一句中文翻译为一句英文,每个字在句子中的位置也对意思的表达会产生很大的影响,所以每个字在句子中的位置也要定义一个向量来表达(即一个位置对应转换为一个向量,称为位置向量);
位置向量将字向量/单词向量加上位置向量(定义两种向量的维度相同,如都是512维,便于此处元素相加),能更好更全面的代表这句话,为更好的翻译做好准备;
单词向量+位置向量
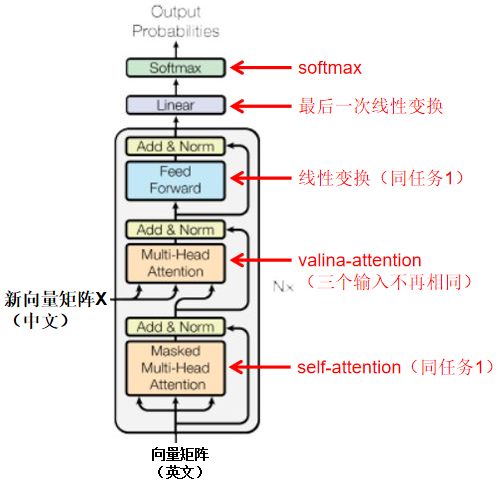
“Attention模型”实现以上内容,具体情况如下图所示:
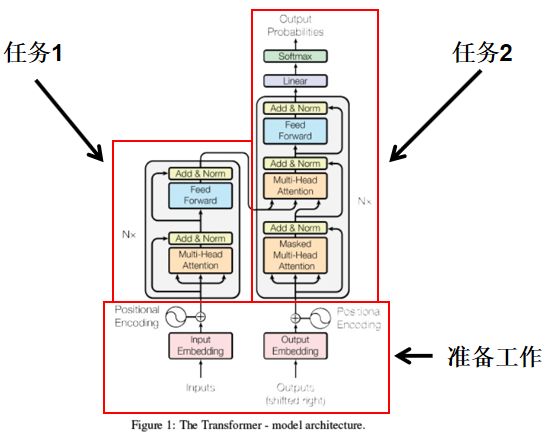
以下针对“准备工作”、任务1和任务2展开讨论;
准备工作
包括字向量/单词向量、位置向量;此处也称为词嵌入,位置编码;
- 字向量/单词向量分别是
随机产生产生的一组512维向量,如字向量,假设选用了3000个常用汉字,每个字对应一个512维的随机向量,则整个字向量就是一个3000 X 512 的二维矩阵,每一行代表一个字;
之所以用随机且选择较大维度(如512维),是为了让生成的各个向量间尽可能的独立,即没有相关性,就像“你、我、他、拿、和、中”指代的具体意思在最初定义时是可以随机互换的,之间也无关系,他们之间的相关性/关系是在该语系语境中根据语义、语法、文化等因素形成的,即上述任务1需要完成的。
(词嵌入,每个词之间没有关系)
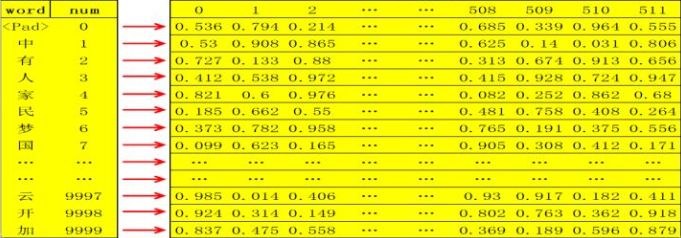
- 位置向量是代表一个字在句子中的位置信息,也定义为一个512维的向量,但并不是随机产生的,而是根据位置确切计算得来,即一个位置对应转化为一个512维向量;

- 假设翻译时定义一句话最大长度是10个字,则该句话对应的字向量是一个10 X 512的二维矩阵(每一行代表一个字),位置向量也是一个10 X 512的二维矩阵(每一行代表对应字的位置信息);两个矩阵相加得新的二维矩阵能更好更全面的表达这句话;
任务1:编码
理解一句中文A的意思为X;此处也称为“编码”
翻译时中文中的“你”、“我”大多时候对应着英文的“you”、“me”,如果都是这样的简单一一对应关系,那翻译是很简单的;而实际情况是绝大多数都是一对多的关系,即同一个中文字在不同的语境中对应的英文是不一样的单词,如“和”字在不同语境中翻译为英文可能是“and”、“sum”、“peace”等。
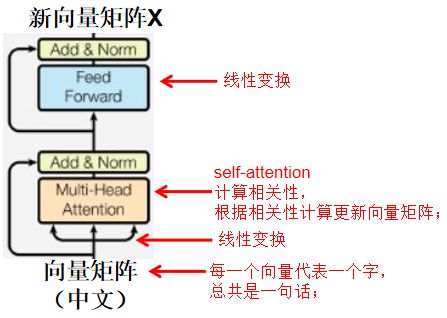
一个字从多个可能的意思中选择一个是根据语境来确定的,即根据这个字与句子中所有字的相关关系来确定;一句话需要计算该句话中每个字与该句子中所有字的相关关系来确定这句话中每个字在该语境中的意思,即确认中文语境;
⭐ 在计算相关性之前,对每一个字对应的向量进行相应的线性变换以便于更好的计算相关性确认最终意思;计算完相关性(确认中文语境)并以此更新向量矩阵后(即self-attention,确认每个字在当前这句话的语境下的“确切意思”),再进行一次线性变换,对这个“确切意思”进行再次拟合校准;
具体情况,如下图所示;
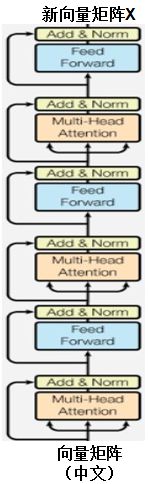
Notes:i~iii是一个处理单元,输入“向量矩阵”和输出“新向量矩阵X”的维度是一样的;完成任务1是以上处理单元循环N次(强化上述效果),设定义N=3(论文中N=8);即由3个处理单元依次链接完成任务1,如下图所示:
任务2:解码
将意思X用英文表达出来,即英文B;此处也称为“解码”
和任务1类似,差异在于:
I. 任务1仅考虑中文语境即可,任务2既考虑中文语境(vanilla-attention),也考虑英文语境(self-attention);
- 和任务1类似,经过N个处理单元后获得的向量矩阵,经过“最后一次线性变换”转换为对应英文语系中各个单词的值,然后由softmax转换为是各个英文单词的概率,完成翻译;
图示如下:
整体简化图示如下:
Attention注意力
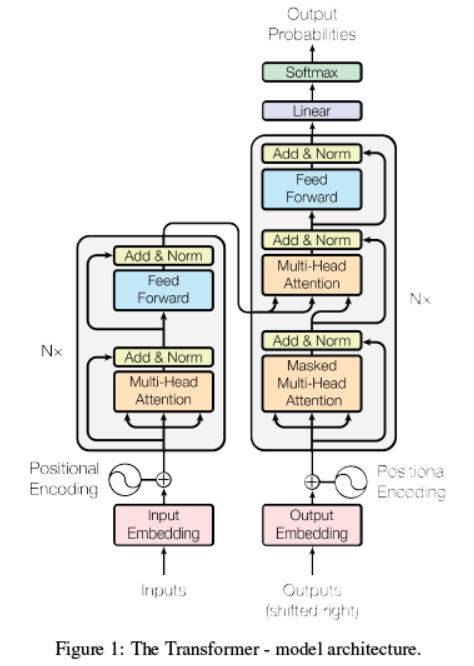
上图是attention模型的总体结构,包含了模型所有节点及流程(因为有循环结构,流程不是特别清楚,下文会详细解释);模型总体分为两个部分:编码部分和解码部分,分别是上图的左边和右边图示;以下选取翻译情景,以模型训练为例解释整个过程;
训练样本:原文译文(一一对应)
编码部分(inputs)
Input embedding:
1.1 将原文的所有单词汇总统计频率,删除低频词汇(比如出现次数小于20次的统一
定义为’
此时总共选出了假设10000个单词,则用数字编号为0~9999,一一对应,定义该对应表为word2num;
然后用xaviers方法生成随机矩阵Matrix :10000行N列(10000行是确定的,对应10000个单词,N列自定义);这样就可以将10000个不同的单词通过word2num映射成10000个不同的数字(int),然后将10000个不同的数字通过Matrix映射成10000个不同的N维向量(如何映射?比如数字0,3,经过 Matrix映射分别变为向量Matrix[0],Matrix[3],维度为N维);
这样,任何一个单词,都可以被映射成为唯一的一个N维向量;
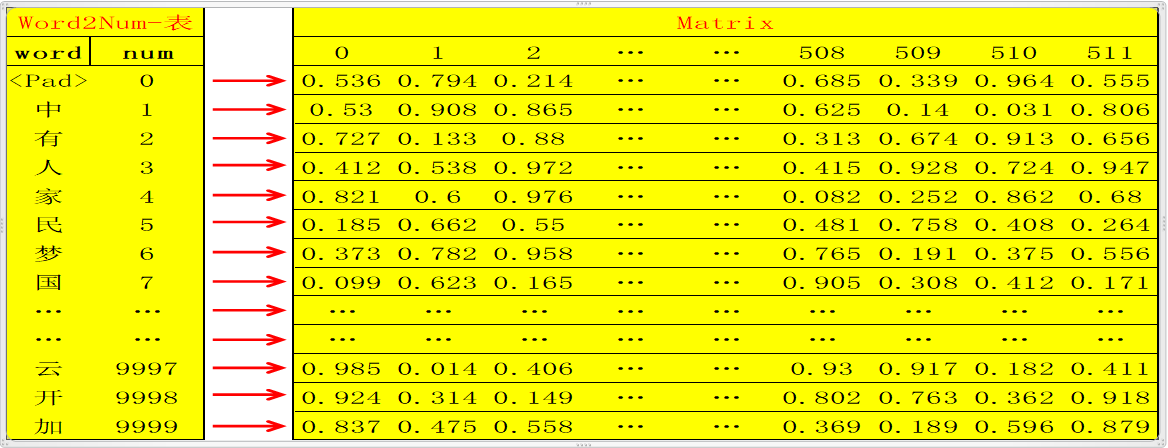
Note:此处N自定义为512
1.2 翻译的时候是一个句子一个句子的翻译,所以需要定义一个句子的标准长度,比如10个单词;如果一句话不足10个单词则用0填充(对应的word即word2num表中的
这样一句话就是标准的10个单词;比如句子 “中国人有中国梦。”,这句话共有八个字(最后一个是结束符),经过word2num变为一列X:1,7,3,2,1,7,6,100,0,0,X经过Matrix映射为10行N列的矩阵matX= [Matrix[1], Matrix[7], Matrix[3], Matrix[2] , Matrix[1] , Matrix[7] , Matrix[6], Matrix[100] , Matrix[0] , Matrix[0]]; embedding 到此基本结束,即完成了将一句话变为 一个矩阵,矩阵的每一行代表一个特定的单词;此处还可以scale一下,即matX*N**(1/2); (**代表次方,即matX中的每一个元素都乘以N的1/2次方,此时N=512,以此来缩放)
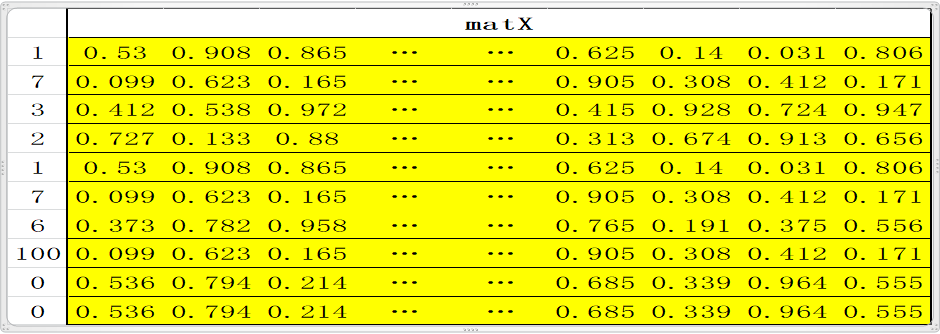
Positional encoding:
2.1 单词在句子中的不同位置体现了不同信息,所以需要对位置进行编码,体现不同的信息情况,此处是对绝对位置进行编码,即位置数字0,1,2,3,…N等,进行运算编码,具体编码如下:
2.1.1 对于句子中的每一个字,其位置pos∈0,1,2,…,9,每个字是N(512)维向量,维度 i (i∈[ 0,1,2,3,4,..N])带入函数计算,
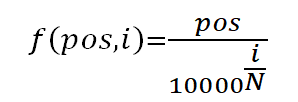
用sin和cos是因为在后面运算过程中会近似出现sin(a)sin(b)+cos(a)cos(b)的形式,根据三角函数公式上式恰好等于cos(a-b),当a和b差小时(即两个字离得近)值大,反之小。这在一定程度上可以表达两个字的距离。
2.1.2 经过如上函数运行一次后,获得了一个10行N列的矩阵matP;每一行代表一个绝对位置信息,此时matP的shape和matX的shape相同;

2.1.3 对于矩阵matP的每一行,第0,2,4,6,...等偶数列上的值用sin()函数激 活,第1,3,5,。。。等奇数列的值用cos()函数激活,以此更新matP;即 matP[:,0::2]=sin(matP[:,0::2]), matP[:,1::2]=cos(matP[:,1::2]);

2.2 至此positional encoding结束,最后通常也会scale一次,即对更新后的matP进行matP*N**(1/2)运算,得到再次更新的matP,此时的matP的shape还是和matX相同;然后将matP和matX相加即matEnc=matP+matX,矩阵matEnc其shape=[10,512];
Multi-head attention循环单元
3.1 然后matEnc进入模型编码部分的循环,即Figure1中左边红色框内部分,每个循环单元又分为4个小部分:multi-head attention, add&norm, feedForward, add&norm;
3.2 Multi-head attention
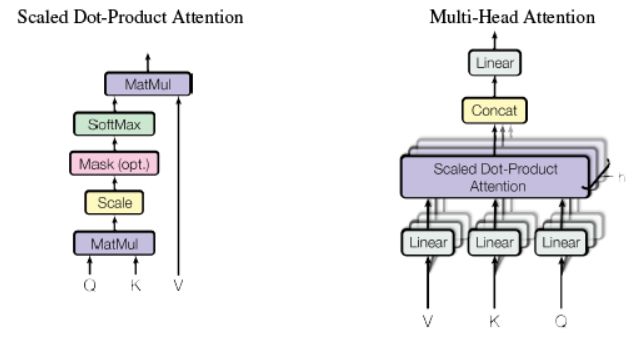
3.2.1 Multi-head attention 由三个输入,分别为V,K,Q,此处V=K=Q=matEnc(在解码部分multi-head attention中的VKQ三者不是这种关系);
3.2.2 首先分别对V,K,Q三者分别进行线性变换,即将三者分别输入到三个单层神经网络层,激活函数选择relu,输出新的V,K,Q(三者shape都和原来shape相同,即经过线性变换时输出维度和输入维度相同);
3.2.3 然后将Q在最后一维上进行切分为num_heads(假设为8)段,然后对切分完的矩阵在axis=0维上进行concat链接起来(纵向连接);对V和K都进行和Q一样的操作;操作后的矩阵记为Q_,K_,V_;
可以变化其维度, 由[1,10,512]变为[8,10,64]
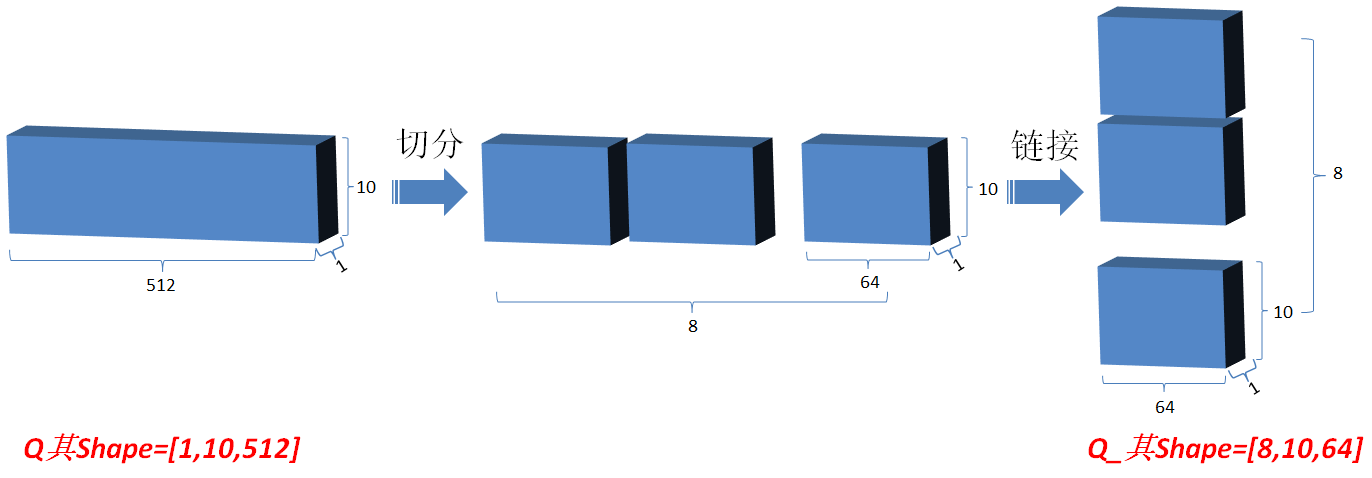

3.2.4 Q_矩阵相乘 K_的转置(对最后2维),生成结果记为outputs,然后对outputs 进行scale一次更新为outputs;此次矩阵相乘是计算词与词的相关性,切成多个num_heads进行计算是为了实现对词与词之间深层次相关性进行计算;
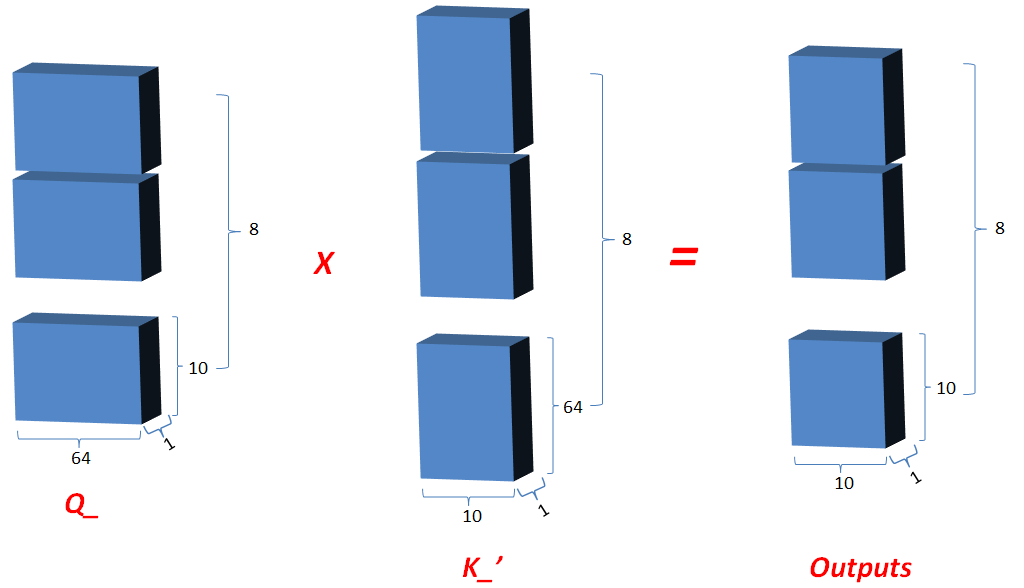
shape(outputs) = (8,10,10)
3.2.5 对outputs进行softmax运算,更新outputs,即outputs=softmax(outputs);
3.2.6 最新的outputs(即K和Q的相关性) 矩阵相乘 V_, 其值更新为outputs;
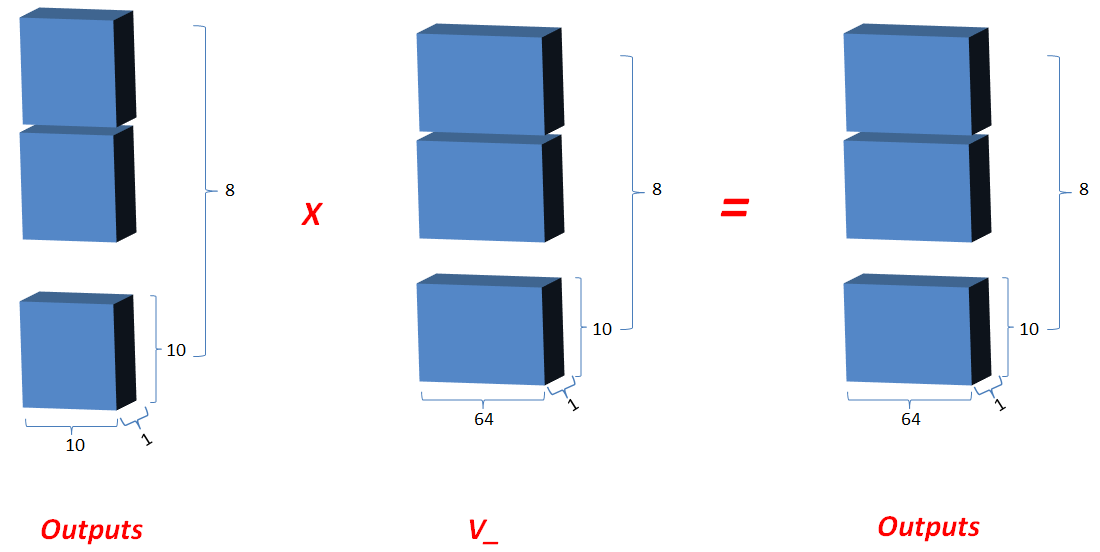
shape(outputs)= (8,10,64)
3.2.7 最后将outputs在axis=0维上切分为num_heads段,然后在axis=2维上合并, 恢复原来Q的维度;
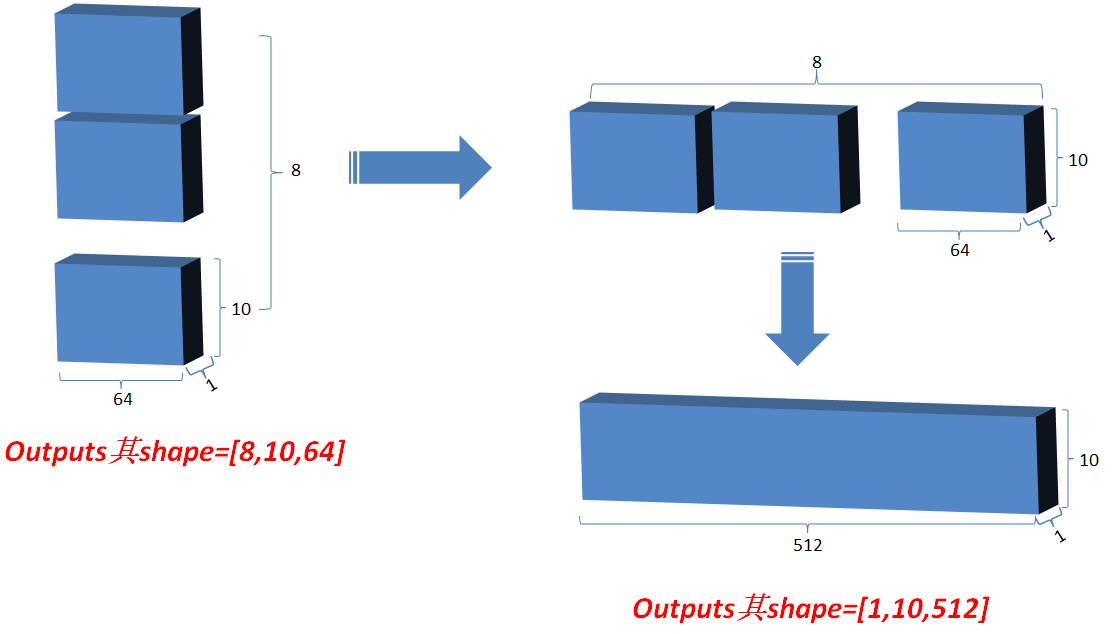
3.3 Add&norm
3.3.1 类似ResNet,将最初的输入与其对应的输出叠加一次,即outputs=outputs+Q, 使网络有效叠加,避免梯度消失;
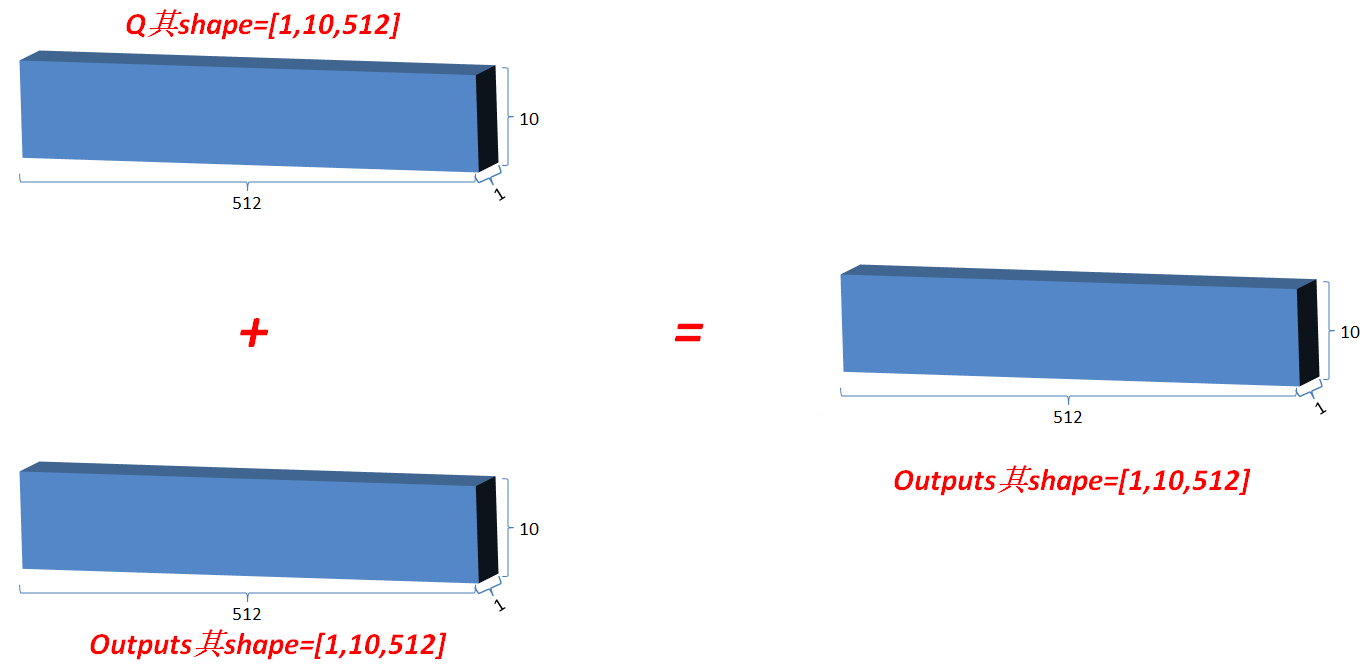
3.3.2 标准化矫正一次,在outputs对最后一维计算均值和方差,用outputs减去均值除以方差+spsilon得值更新为outputs,然后变量gamma*outputs+变量beta;(Norm操作)
3.4 feed Forward (就是dense layer 全连接层)
3.4.1 对outputs进行第一次卷积操作,结果更新为outputs(卷积核为1*1,每一次卷积操作的计算发生在一个词对应的向量元素上,卷积核数目即最后一维向量长度,也就是一个词对应的向量维数);
3.4.2 对最新outputs进行第二次卷积操作,卷积核仍然为1*1,卷积核数目为N;
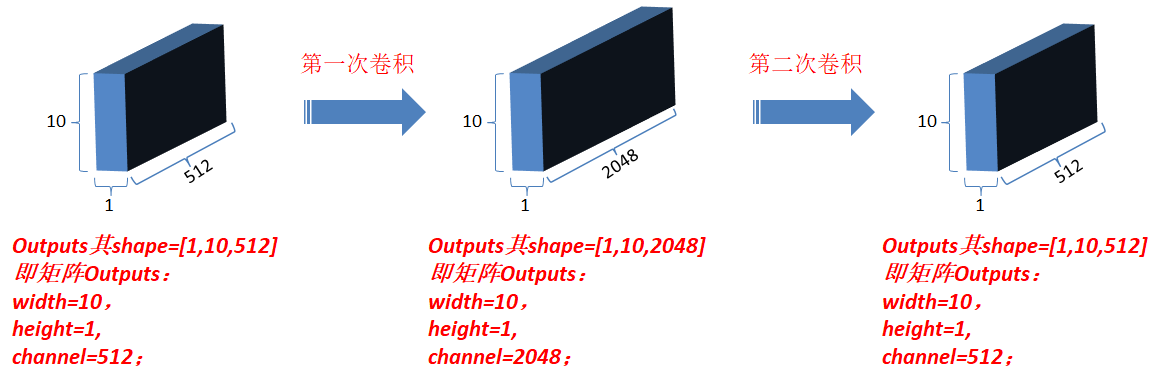
3.5 Add&norm : 和3.3相同,经过以上操作后,此时最新的output和matEnc的shape相同;
3.6 令matEnc=outputs, 完成一次循环,然后返回到3.2开始第二次循环;共循环Nx(自定义;每一次循环其结构相同,但对应的参数是不同的,即是独立训练的);完成Nx次后,模型的编码部分完成,仍然令matEnc=outputs,准备进入解码部分;
解码部分:
此时的outputs指的是上一时间点解码器的输出
Outputs:shifted right右移一位????,是为了解码区最初初始化时第一次输入,并将其统一定义为特定值(在word2num中提前定义);
Outputs embedding: 同编码部分;更新outputs;
Positional embedding:同编码部分;更新outputs; (前三步是准备工作)
进入解码区循环体; (以下是解码器的顺序操作)
4.1 Masked multi-head attention: 和编码部分的multi-head attention类似,但是多了一 次masked,因为在解码部分,解码的时候是从左到右依次解码的,当解出第一个字的时候,第一个字只能与第一个字计算相关性,当解出第二个字的时候,只能计算出第二个字与第一个字和第二个字的相关性,...;所以需要进行一次mask;
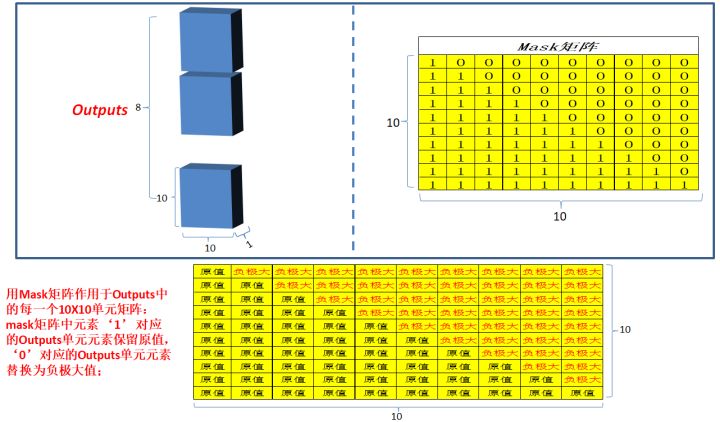
为什么是10*10呢???
4.2 Add&norm:同编码部分,更新outputs;
4.3 Multi-head attention:同编码部分,但是Q和K,V不再相同,Q=outputs,K=V=matEnc;(outputs是上层的输出,k,v是来自编码器的输出)
4.4 Add&norm:同编码部分,更新outputs;
4.5 Feed-Forward:同编码部分,更新outputs;
4.6 Add&norm: 同编码部分,更新outputs;
4.7 最新outputs和最开始进入该循环时候的outputs的shape相同;回到4.1,开始第 二次循环。。。;直到完成Nx次循环(自定义;每一次循环layer结构相同,但对应的参数是不同的,即独立训练的);
Linear: 将最新的outputs,输入到单层神经网络中,输出层维度为“译文”有效单词总数;更新outputs;
Softmax: 对outputs进行softmax运算,确定模型译文和原译文比较计算loss,进行网络优化(参数更新);
注
1.解码器的outputs embedding :在训练的时候就是对应原文的译文,其中第一字统一定义为0,作为输入;在预测时第一次输入也是全是0,然后每循环一次,预测一个字直到出现终止符。
2.对于matEnc=matP+matX,这里为什么要用add,而不是contact ?
matX是一个10行512列的矩阵,每一行代表一个字;
matP是一个10行512列的矩阵,每一行代表一个位置;
对于不一样的句子,matX是不一样的,matP是完全一样的;
则对于不一样的句子,add后是不一样的,contact后至少一半是一样的,从直观上,add似乎更好;
对于一个字,其出现的位置不同,可能表达的意思完全不一样,比如“和”,如果其在句首或者句中出现更可能是“and”的意思,如果在句末出现,更可能是“sum”的意思,而这两个意思几乎完全不一样,即他们的向量完全不一样似乎更合理,而非contact的至少一半一样;
matP矩阵的特点从上到下对应各元素是递增的,matX是随机产生的(比如均值为0的随机数),即大约在0附近波动的数,与matP做add运算后,相当于均值被依次提高,以此代表融入每个字位置信息;因为每次训练的时候均值被提高的量是一定的,所以可以期望模型训练后能“意识”到这一点;
add产生“信息混淆”,比如两个字在两个不同的位置上分别add后,结果相近,从直观上这可能会造成问题;这个问题可以通过加大向量维度来降低其出现概率,比如选择512维是很长的维度了,出现这种概率的问题还是很小的;
如果用contact实际就是在每个字向量后面追加一个位置信息以示区别,做这种区别无需太多维,也许一两维即可;
深度学习算法的可解释性差,分析大多属于理论上的“纸上谈兵”,最可靠的方式,仍是分别以add和contact两种方式建模,大量测试后的结果更为可靠。
待探究
你文章中的逻辑是,对原始Q/K/V做不同线性变换(三个权重矩阵)得到新的Q/K/V→对新的Q/K/V在最后一个维度做切分得到多头(8组Q/K/V)→各组Q/K/V计算attetion值→8组Q/K/V的attetion值concat得到最终的attention值。
而原论文的逻辑是,对原始的Q/K/V做不同的线性变换(8(组)×3个权重矩阵)得到新的8组Q/K/V值→各组Q/K/V计算attention值→8组Q/K/V的attention值concat→concat结果经过一个线性变换(为了还原到最初的维度)得到最终的attention值。
论文提到multi-head attention是为了从不同表征子空间提取信息。个人理解实现这种差异化的提取,是通过多组权重矩阵来实现的,而不是通过embedding值不同分段获取。
在预测阶段,每次预测后底部decoder的输入是可变的,首先是[
],然后是[ , word1 ],再输入[ , word1, word2 ]……,那么decoder内部如何保证它送入linear层的输出是(1, N)的向量呢? 答:[
]时,经过解码区的循环部分后 是一个[1, 512]的矩阵, 经过linear层是准备预测1个字的; [
, word1 ]时,经过解码区的循环部分 是一个[2, 512]的矩阵;经过linear层是准备预测2个字的;以此类推。 也就是说,输入bos,输出word1;然后将bos word1输入,再输出word1 word2;再输入bos word1 word2......每次都把输出的最后一个字加到下一轮输入。
假设target是
我爱中国 ,这算6个字,训练时decoder是不是也输出6个vocab-size长度的向量,那么第一个vocab-size长度的向量预测的是 还是"我"呢? 答:预测的第一个是“我”,
作为一个起始引导使用。 第一个问题是训练和预测时解码端如何运行,我理解训练时使用mask一次性对所有时间步并行进行解码,预测时则需要先预测出上一步的词,再输入预测下一步,所以不能并行。如果我上面说的没错的话,第一个问题是为什么训练时mask没有掩盖自身,也就是对角线不mask,这样的话不就泄露了要预测那个词吗?第二个问题是预测时该如何进行,因为训练时,输入多少个时间步的词就会输出多少个时间步的预测值,但是在预测解码阶段,假设为t,要预测t + 1该如何操作?难道是先将t + 1随便加一个pad上去然后看预测值softmax吗?
答:在训练时,用mask是一次性的解码,因为训练时所有label是已知的,用mask实现同时并行运算;预测时label是未知的,需要一个一个词预测,当预测第一个词时只能知道第一个词和第一个词的相关性,然后再运行模型一遍,预测出第一个词和第二词,依次循环直到出现终止符,这个过程不是并行的。
个人理解: 在训练时,把一整句话都作为解码器的输入,这样可以实现并行运算,因为每一个label都是已知的。而在预测时,需要一步一步来
