对数似然
最大化对数似然,因此值越大越好。例如,对数似然值 -3 比 -7 好。
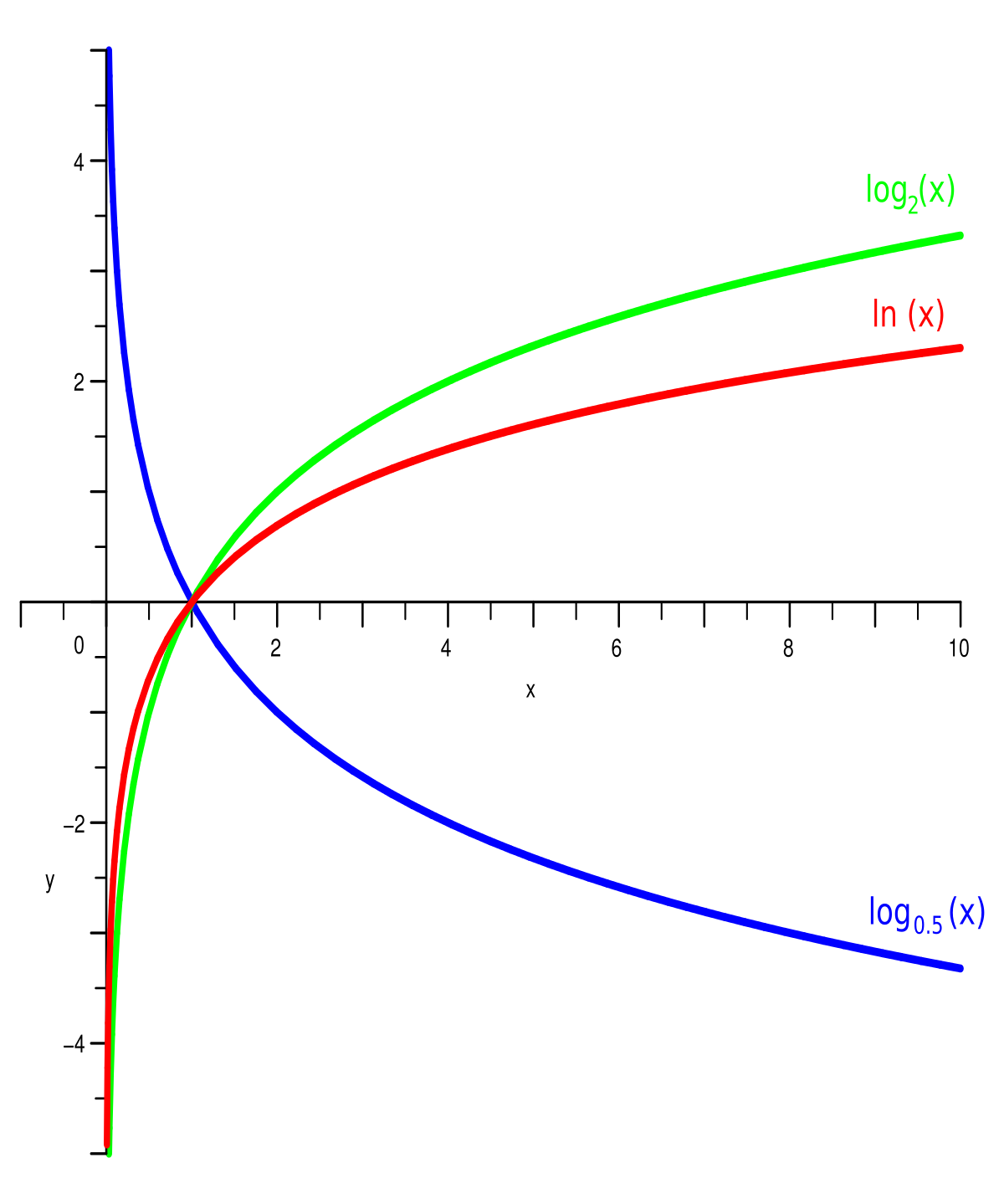
对数为负值是完全可能的,如下图log函数
高斯分布中考虑对数似然而不是似然
通过最大似然函数来确定高斯分布中未知参数的值,实际上,最大化似然函数的对数更方便。因为对数是其论证的单调递增函数,函数的对数的最大化等价于函数本身的最大化。logaithm不仅简化了后续的数学分析,而且还有助于数学计算,因为大量小概率的乘积很容易使计算机的数值精度下降,但是log就可以通过计算总和来解决。
- 当要计算随机变量的joint likelihood时很有用,他们之间独立,并且分布相同。
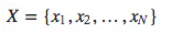
联合概率是所有点的概率的乘积:
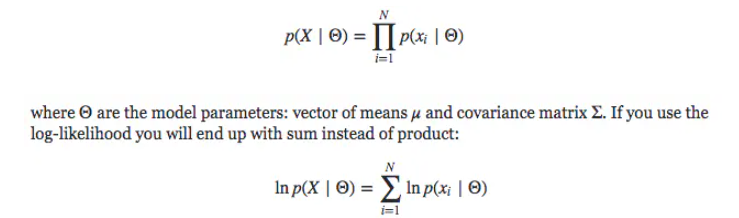
如果是log,则只需要求和即可
- 由于是高斯分布,使用log避免了计算指数
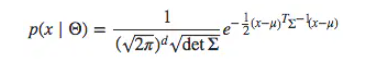
可以写成:
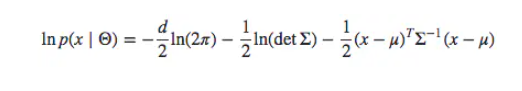
- ln x是单调递增的函数,因此log-likelihood和likelihood有相同的关系
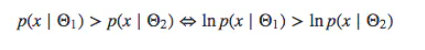
负对数似然是一种用于解决分类问题的 损失函数 ,它是似然函数得一种自然对数形式,可用于测量两种概率分布之间的相似性,其取负号是为了让最大似然值和最小损失相对应,是最大似然估计及相关领域的常见函数形式。
机器学习中,习惯用优化 算法 求最小值,因此会用到负对数似然,这是分类问题中的常见的损失函数,且能拓展到 多分类 问题。
负对数似然和似然估计
负对数似然是一种用于解决分类问题的 损失函数 ,它是似然函数的一种自然对数形式,可用于测量两种概率分布之间的相似性,其取负号是为了让最大似然值和最小损失相对应,是最大似然估计及相关领域的常见函数形式。
机器学习中,习惯用优化 算法 求最小值,因此会用到负对数似然,这是分类问题中的常见的损失函数,且能拓展到 多分类 问题。
最大似然估计
归纳偏置(Inductive Bias)
在机器学习中,很多学习算法经常会对学习的问题做一些假设,这些假设就称为归纳偏置(Inductive Bias)。
归纳(Induction)是自然科学中常用的两大方法之一(归纳与演绎, induction and deduction),指的是从一些例子中寻找共性、泛化,形成一个比较通用的规则的过程;偏置(Bias)是指我们对模型的偏好。
因此,归纳偏置可以理解为,从现实生活中观察到的现象中归纳出一定的规则(heuristics),然后对模型做一定的约束,从而可以起到“模型选择”的作用,即从假设空间中选择出更符合现实规则的模型。其实,贝叶斯学习中的“先验(Prior)”这个叫法,可能比“归纳偏置”更直观一些。
在深度学习方面也是一样。以神经网络为例,各式各样的网络结构/组件/机制往往就来源于归纳偏置。
在卷积神经网络中,我们假设特征具有局部性(Locality)的特性,即当我们把相邻的一些特征放在一起,会更容易得到“解”;在循环神经网络中,我们假设每一时刻的计算依赖于历史计算结果;还有注意力机制,也是基于从人的直觉、生活经验归纳得到的规则。
CNN的inductive bias应该是locality和spatial invariance,即空间相近的grid elements有联系而远的没有,和空间不变性(kernel权重共享)
RNN的inductive bias是sequentiality和time invariance,即序列顺序上的timesteps有联系,和时间变换的不变性(rnn权重共享)
图灵完备(turing complete)
在可计算性理论里,如果一系列操作数据的规则(如指令集、编程语言、细胞自动机)按照一定的顺序可以计算出结果,被称为图灵完备(turing complete)。
一个有图灵完备指令集的设备被定义为通用计算机。如果是图灵完备的,它(计算机设备)有能力执行条件跳转(if、while、goto语句)以及改变内存数据。 如果某个东西展现出了图灵完备,它就有能力表现出可以模拟原始计算机,而即使最简单的计算机也能模拟出最复杂的计算机。所有的通用编程语言和现代计算机的指令集都是图灵完备的(C++ template就是图灵完备的),都能解决内存有限的问题。图灵完备的机器都被定义有无限内存,但是机器指令集却通常定义为只工作在特定的、有限数量的RAM上。
🚀 目标检测
🚀 二分图匹配(bipartite matching )
https://liam.page/2016/04/03/Hungarian-algorithm-in-the-maximum-matching-problem-of-bigraph/
解决vscode乱码问题,VSCode设置自动推导文件编码
LINUX 杀死、暂停、继续、后台运行进程
ctrl + z
可以将一个正在前台执行的命令放到后台,并且暂停
若想恢复到前台,则
- jobs #查看当前有多少在后台运行的命令 会有序号 job号
- fg 〔job号〕 将后台中的命令调至前台继续运行 如: fg %1
Benchmark 和 baseline
benchmark:N-COUNT A benchmark is something whose quality or quantity is known and which can therefore be used as a standard with which other things can be compared.
通俗的讲,一个算法之所以被称为benchmark,是因为它的性能已经被广泛研究,人们对它性能的表现形式、测量方法都非常熟悉,因此可以作为标准方法来衡量其他方法的好坏。 这里需要区别state-of-the-art(SOTA),能够称为SOTA的算法表明其性能在当前属于最佳性能。如果一个新算法以SOTA作为benchmark,这当然是最好的了,但如果比不过SOTA,能比benchmark要好,且方法有一定创新,也是可以发表的。
baseline:N-COUNT A baseline is a value or starting point on a scale with which other values can be compared.
通俗的讲,一个算法被称为baseline,基本上表示比这个算法性能还差的基本上不能接受的,除非方法上有革命性的创新点,而且还有巨大的改进空间和超越benchmark的潜力,只是因为是发展初期而性能有限。所以baseline有一个自带的含义就是“性能起点”。这里还需要指出其另一个应用语境,就是在算法优化过程中,一般version1.0是作为baseline的,即这是你的算法能达到的一个基本性能,在算法继续优化和调参数的过程中,你的目标是比这个性能更好,因此需要在这个base line的基础上往上跳。
简而言之, benchmark一般是和同行中比较牛的算法比较,比牛算法还好,那你可以考虑发好一点的会议/期刊; baseline一般是自己算法优化和调参过程中自己和自己比较,目标是越来越好,当性能超过benchmark时,可以发表了,当性能甚至超过SOTA时,恭喜你,考虑投顶会顶刊啦。
object detection与object recognition区别
object recognition(目标识别)
给定一幅图像
检测到图像中所有的目标(类别受限于训练集中的物体类别)
得到检测到的目标的矩形框,并对所有检测到的矩形框进行分类

Object Recognition: In a given image you have to detect all objects (a restricted class of objects depend on your dataset), Localized them with a bounding box and label that bounding box with a label.
object detection(目标检测)
与object recognition目标类似
但只有两个类别,只需要找到目标所在的矩形框和非目标矩形框
例如,人脸检测(人脸为目标、背景为非目标)、汽车检测(汽车为目标、背景为非目标)


Object Detection: it’s like Object recognition but in this task you have only two class of object classification which means object bounding boxes and non-object bounding boxes. For example Car detection: you have to Detect all cars in a given image with their bounding boxes.
class-agnostic和class-specific的区别
For a class-aware(class-specific) detector, if you feed it an image, it will return a set of bounding boxes, each box associated with the class of the object inside (i.e. dog, cat, car). It means that by the time the detector finished detecting, it knows what type of object was detected.
For class-agnostic detector, it detects a bunch of objects without knowing what class they belong to. To put it simply, they only detect “foreground” objects. Foreground is a broad term, but usually it is a set that contains all specific classes we want to find in an image, i.e. foreground = {cat, dog, car, airplane, …}. Since it doesn’t know the class of the object it detected, we call it class-agnostic.
对抗攻击(adversarial attack)
概念
对抗攻击英文为adversarial attack。即对输入样本故意添加一些人无法察觉的细微的干扰,导致模型以高置信度给出一个错误的输出。
首先通过一些图片来对这个领域有一个直观的理解:对抗攻击就是使得DNN误判的同时,使得图片的改变尽可能少。

从图中可以看的出来,DNN在左图中正常地把狗识别成狗,而在左图上添加一些扰动(perturbation)之后形成右图,在肉眼看来,这两张图片并没有什么区别,按正常左右两图的识别结果应该是一样的,但是DNN却在右图中不正常的把狗识别成了人、火车等等。

在原图上加一个人肉分辨不出来的Perturbation之后,可以使得识别出现错误
对抗攻击从image attack起源,逐渐完善理论,然后慢慢扩大到了video attack以及在NLP、强化学习等领域中的应用。
其中的思想大致可以按下面理解:深度神经网络对输入图片的特征有了一个比较好的提取,但是具体提取了什么特征以及为什么提取这个特征不知道。所以我们需要试图找到那个模型认为很重要的位置,然后尝试着去改变这个位置的像素值,使得DNN对输入做出一个误判。
