🚀others
python的einops rearrange()函数
例子:
假设我有一个3-D数组:
1 | [[[0,1,2], |
我想按列重新排列:
1 | [[0,1,2,3,4,5], |
使用einops:
1 | einops.rearrange(a, 'x y z -> y (x z) ') |
并且我建议根据上下文(例如时间,高度等)为轴指定有意义的名称(而不是xyz)。 这将使您易于理解代码的作用
1 | In : einops.rearrange(a, 'x y z -> y (x z) ') |
Epoch、Iteration、Batch_size
https://blog.csdn.net/program_developer/article/details/78597738
python中字符串前 r'', b'', u'', f'' 的含义
🚀tensorflow
tf.tile()用法
Dataset API 和 Iterator
Dataset API 和 Iterator
https://blog.csdn.net/briblue/article/details/80962728
TensorFlow中的Dataset API
https://blog.csdn.net/dqcfkyqdxym3f8rb0/article/details/79342369
TensorFlow data模块详解
https://www.weaf.top/posts/cd5ba0c4/
使用Tensorflow的DataSet和Iterator读取数据
https://www.jianshu.com/p/bcff8a99b15b
tensorflow数据读取机制(附代码)
https://zhuanlan.zhihu.com/p/27238630
Dataset API入门教程
https://zhuanlan.zhihu.com/p/30751039
Dataset.from_generator
看个简单的示例:
1 | #创建一个Dataset对象 |
以上打印结果为:1 2 3 4 5 6 7 8 9
from_generator
创建Dataset由其生成元素的元素generator。
函数形式:from_generator(generator,output_types,output_shapes=None,args=None)
参数generator:一个可调用对象,它返回支持该iter()协议的对象 。如果args未指定,generator则不得参数; 否则它必须采取与有值一样多的参数args。 参数output_types:tf.DType对应于由元素生成的元素的每个组件的对象的嵌套结构generator。 参数output_shapes:tf.TensorShape 对应于由元素生成的元素的每个组件的对象 的嵌套结构generator 参数args:tf.Tensor将被计算并将generator作为NumPy数组参数传递的对象元组。
具体例子
1 | #定义一个生成器 |
以上代码运行结果:0 1 2
tf strip() 和 split()
Summary用法 -tensorborad可视化
math.ceil()
.format() 格式化函数
tf.shape(A) 和 A.get_shape().as_list() 和 tf.split()
- tf.shape(A) # 獲取張量A(陣列,list, tensor張量)的大小,返回的是一個list
- x.get_shape(),只有tensor才可以使用這種方法,返回的是一個元組
- tf.split(dimension, num_split, input):dimension的意思就是輸入張量的哪一個維度,如果是0就表示對第0維度進行切割。num_split就是切割的數量,如果是2就表示輸入張量被切成2份,每一份是一個列表。
tf.range()
1 | w=tf.range(3) |
os.path()
| 方法 | 说明 |
|---|---|
| os.path.abspath(path) | 返回绝对路径 |
| os.path.basename(path) | 返回文件名 |
| os.path.join(path1[, path2[, ...]]) | 把目录和文件名合成一个路径 |
| os.path.dirname(path) | 返回文件路径 |
| os.path.exists(path) | 如果路径 path 存在,返回 True;如果路径 path 不存在,返回 False。 |
| os.path.split(path) | 把路径分割成 dirname 和 basename,返回一个元组 |
embedding_lookup()
tf.nn.embedding_lookup()就是根据input_ids中的id,寻找embeddings中的第id行。比如input_ids=[1,3,5],则找出embeddings中第1,3,5行,组成一个tensor返回。
模型保存和加载
Saver的作用是将我们训练好的模型的参数保存下来,以便下一次继续用于训练或测试;Restore的用法是将训练好的参数提取出来。
1.Saver类训练完后,是以checkpoints文件形式保存。提取的时候也是从checkpoints文件中恢复变量。 Checkpoints文件是一个二进制文件,它把变量名映射到对应的tensor值 。
2.通过for循环,Saver类可以自动的生成checkpoint文件。这样我们就可以保存多个训练结果。例如,我们可以保存每一步训练的结果。但是为了避免填满整个磁盘,Saver可以自动的管理Checkpoints文件。例如,我们可以指定保存最近的N个Checkpoints文件。
Tensorflow模型保存和读取tf.train.Saver
目标:训练网络后想保存训练好的模型,以及在程序中读取以保存的训练好的模型。
首先,保存和恢复都需要实例化一个 tf.train.Saver。
saver = tf.train.Saver()
然后,在训练循环中,定期调用 saver.save() 方法,向文件夹中写入包含了当前模型中所有可训练变量的 checkpoint 文件。
saver.save(sess, save_path, global_step=step)
之后,就可以使用 saver.restore() 方法,重载模型的参数,继续训练或用于测试数据。
saver.restore(sess, save_path)
模型的恢复用的是restore()函数,它需要两个参数restore(sess, save_path),save_path指的是保存的模型路径。我们可以使用tf.train.latest_checkpoint()来自动获取最后一次保存的模型。如:
1 | model_file=tf.train.latest_checkpoint('ckpt/') |
一次 saver.save() 后可以在文件夹中看到新增的四个文件,
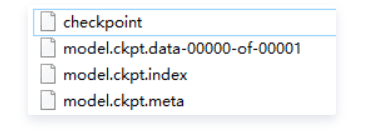
实际上每调用一次保存操作会创建后3个数据文件并创建一个检查点(checkpoint)文件,简单理解就是权重等参数被保存到 .ckpt.data 文件中,以字典的形式;图和元数据被保存到 .ckpt.meta 文件中,可以被 tf.train.import_meta_graph 加载到当前默认的图。
saver.restore()时填的文件名,因为在saver.save的时候,每个checkpoint会保存三个文件,如 my-model-10000.meta, my-model-10000.index, my-model-10000.data-00000-of-00001
在import_meta_graph时填的就是meta文件名,我们知道权值都保存在my-model-10000.data-00000-of-00001这个文件中,但是如果在restore方法中填这个文件名,就会报错,应该填的是前缀,这个前缀可以使用tf.train.latest_checkpoint(checkpoint_dir)这个方法获取。
下面代码是简单的保存和读取模型:(不包括加载图数据)
1 | import tensorflow as tf |
注:
- saver 的操作必须在 sess 建立后进行。
- model.ckpt 必须存在给定文件夹中,‘tmp/model.ckpt’ 这里至少要有一层文件夹,否则无法保存。
- 恢复模型时同保存时一样,是 ‘tmp/model.ckpt’,和那3个文件名都不一样。
如果不用tf.train.latest_checkpoint()来自动获取最后一次保存的模型,则怎么做呢?
Saver中的max_to_keep 参数
keras中的TimeDistributed函数
https://blog.csdn.net/u012193416/article/details/79477220
https://keras.io/zh/layers/wrappers/
tf.concat()详解
1 | tf.concat([tensor1, tensor2, tensor3,...], axis) |
shape
numpy数据的形状:
1 | x.shape() |
list 数据的形状:
1 | np.shape(x) |
注:如果写x.shape() , 则会报错ValueError: invalid literal for int() with base 10
torsor形状:
1 | x.get_shape() |
keras 的 fit函数
fit中以call()方法的形式来run session
Model 类继承
可以通过继承 Model 类并在 call 方法中实现你自己的前向传播,以创建你自己的完全定制化的模型,(Model 类继承 API 引入于 Keras 2.2.0)。
这里是一个用 Model 类继承写的简单的多层感知器的例子:
1 | import keras |
网络层定义在 __init__(self, ...) 中,前向传播在 call(self, inputs) 中指定。在 call 中,你可以指定自定义的损失函数,通过调用 self.add_loss(loss_tensor) (就像你在自定义层中一样)。
在类继承模型中,模型的拓扑结构是由 Python 代码定义的(而不是网络层的静态图)。这意味着该模型的拓扑结构不能被检查或序列化。因此,以下方法和属性不适用于类继承模型:
model.inputs和model.outputs。model.to_yaml()和model.to_json()。model.get_config()和model.save()。
关键点:为每个任务使用正确的 API。Model 类继承 API 可以为实现复杂模型提供更大的灵活性,但它需要付出代价(比如缺失的特性):它更冗长,更复杂,并且有更多的用户错误机会。如果可能的话,尽可能使用函数式 API,这对用户更友好。
关于tensorflow的session、tensor、shape等基础知识(整理)
在tensorflow程序中,tensor只是占位符,在会话层没有run出tensor的值之前,我们是无法获知tensor的值的
https://blog.csdn.net/jiongnima/article/details/78524551
tf.layers.flatten
在保留第0轴的情况下对输入的张量进行Flatten(扁平化)
代码示例:
1 | x=tf.placeholder(shape=(None,4,4),dtype='float32') |
输出: 将后两维进行合并
1 | Tensor("flatten/Reshape:0", shape=(?, 16), dtype=float32) |
tf.layers.dense
全连接层 ,相当于添加一个层。只改变输入的最后一维
python - Tensorflow中 None,-1和?之间的区别
None表示未指定的维度。因此,如果您定义了一个占位符,您可以使用None来表示“这个维度可以有任何大小”。 占位符可以有多个None维度这仅仅意味着多个维度可以是不同的大小甚至整个形状都可以None来指定未知的维数。 -1是TensorFlow的一条指令,用于自行推断维度的大小。在tf.reshape(input, [-1, input_size])中,这意味着“重塑它,使第二个维度input_size,第一个维度是匹配元素总数所需的任何内容”。 这并不一定意味着维数是未知的,因为对于None如果输入张量的已知大小为10个元素,并且将其重塑为[-1, 2],则张量流能够推断出完整的形状[5, 2]。 -1纯粹是为了方便。你可以把形状写下来,而不是让Tensorflow推断出来None另一方面,对于接受可变大小张量是必要的。 一个形状中只能有一个-1。多个是没有意义的,因为不可能推断出形状。例如,如果一个张量中有12个元素,则未定义将其重塑为[-1, -1, 2]——我们是否应该这样做?[3, 2, 2]?[2, 3, 2]?… 最后,问号正是tensorflow在打印张量和/或其形状时用来标记“未知”维度的内容。您发布的示例实际上会产生语法错误——您不能自己使用问号。未知维度的原因当然可以是具有[6, 1, 2]维度的占位符,并且通常根据占位符定义的张量(即应用于它们的某些运算的结果)也将具有未知维度。此外,有些操作可能没有指定(部分)它们的输出形状,这也可能导致未知。 这里可能还有一些我遗漏的技术细节,但根据经验:使用None作为占位符,使用None进行整形。这应该涵盖大多数用例。
?==None,维度是未知的
-1代表根据推断之后的维度
(3,)表明张量是一个一维数组,这个数组的长度为3
keras的 call 函数、build 函数
build() 用来初始化定义weights, 这里可以用父类的self.add_weight() 函数来初始化数据, 该函数必须将 self.built 设置为True, 以保证该 Layer 已经成功 build , 通常如上所示, 使用 super(MyLayer, self).build(input_shape) 来完成。
call() 用来执行 Layer 的职能, x就是该层的输入,x与权重kernel做点积,生成新的节点层,即当前 Layer 所有的计算过程均在该函数中完成。
__init__()和build()函数都在对Layer进行初始化,都初始化了一些成员函数
__init__():保存成员变量的设置
build():在call()函数第一次执行时会被调用一次,这时候可以知道输入数据的shape。返回去看一看,果然是__init__()函数中只初始化了输出数据的shape,而输入数据的shape需要在build()函数中动态获取,这也解释了为什么在有__init__()函数时还需要使用build()函数
call()函数则是在该layer被调用时执行。
tf.expand_dims()
1 | tf.expand_dims(input, dim, name=None) #在指定位置增加维度 |
tf.boolean_mask()
选择张量的特定维度的值
1 | tf.boolean_mask(tensor,mask,name='boolean_mask',axis=None) |
https://blog.csdn.net/wuguangbin1230/article/details/81334544
tf.gfile
提供了文件操作的API,包括文件的读取、写入、删除、复制等等。
tf.contrib.learn框架
主要了解了tf.contrib.learn.ModeKeys.TRAIN/EVAL/INFER
高级API:tf.contrib_learn 。tf.contrib.learn.ModeKeys用来区分fit/evaluate/predict
https://www.itread01.com/content/1547568549.html
tensorflow变量作用域(variable scope)
🚀pytorch
PyTorch torch.nn.Parameter()
作用:对于self.v = torch.nn.Parameter(torch.FloatTensor(hidden_size)),也就是将一个不可训练的类型Tensor转换成可以训练的类型parameter并将这个parameter绑定到这个module里面(net.parameter()中就有这个绑定的parameter,所以在参数优化的时候可以进行优化的),所以经过类型转换这个self.v变成了模型的一部分,成为了模型中根据训练可以改动的参数了。
使用这个函数的目的也是想让某些变量在学习的过程中不断的修改其值以达到最优化。
PyTorch nn.Linear()
用于设置网络中的全连接层的
pytorch nn.embedding() 词向量
词嵌入在 pytorch 中非常简单,只需要调用 torch.nn.Embedding(m, n) 就可以了,m 表示单词的总数目,n 表示词嵌入的维度,其实词嵌入就相当于是一个大矩阵,矩阵的每一行表示一个单词。
随机初始化
pytorch torch.mean()
torch.mean(input, dim, keepdim=False, out=None)
返回新的张量,其中包含输入张量input指定维度dim中每行的平均值。
若keepdim值为True,则在输出张量中,除了被操作的dim维度值降为1,其它维度与输入张量input相同。否则,dim维度相当于被执行torch.squeeze()维度压缩操作,导致此维度消失,最终输出张量会比输入张量少一个维度。
参数:
- input (Tensor) - 输入张量
- dim (int) - 指定进行均值计算的维度
- keepdim (bool, optional) - 输出张量是否保持与输入张量有相同数量的维度
- out (Tensor) - 结果张量
例子:
a = torch.randn(4, 5) a 0.3168 0.4953 -0.6758 -0.5559 -0.6906 0.2241 2.2450 1.5735 -1.3815 -1.5199 0.0033 0.5236 -0.9070 -0.5961 -2.1281 0.9605 1.5314 -0.6555 -1.2584 -0.4160 [torch.FloatTensor of size 4x5] torch.mean(a, 1, True) -0.2220 0.2283 -0.6209 0.0324 [torch.FloatTensor of size 4x1]
np.triu() & np.tril()
1 | def triu(m, k): |
https://blog.csdn.net/weixin_37724529/article/details/102881776
pytorch forward的使用以及原理 --pytorch使用
PyTorch torch.nn.Parameter()详解
pytorch view()
PyTorch中view函数作用为重构张量的维度
torch.view(参数a,参数b,.....),其中参数a=3,参数b=2决定了将一维的tt1重构成3*2维的张量。 有时候会出现torch.view(-1)或者torch.view(参数a,-1)这种情况。则-1参数是需要估算的。
1 | import torch |
则result2为
1 | tensor([[-0.3623, -0.6115, 0.7283], |
pytorch model.parameters()
这个方法会获得模型的参数信息 。
model.parameters()方法返回的是一个生成器generator,每一个元素是从开头到结尾的参数,parameters没有对应的key名称,是一个由纯参数组成的generator,查看Module的参数信息,用于更新参数,或者用于模型的保存。
pytorch torch.optim.lr_scheduler
用于设置学习率的衰减
pytorch torch.gather()
例子
1 | b = torch.Tensor([[1,2,3],[4,5,6]]) |
观察它的输出结果:
1 | 1 2 3 |
这里是官方文档的解释
1 | torch.gather(input, dim, index, out=None) → Tensor |
⭐ 可以看出,gather的作用是这样的,index实际上是索引,具体是行还是列的索引要看前面dim 的指定,比如对于我们的栗子,【1,2,3;4,5,6,】,指定dim=1,也就是横向,那么索引就是列号。index的大小就是输出的大小,所以比如index是【1,0;0,0】,那么看index第一行,1列指的是2, 0列指的是1,同理,第二行为4,4 。这样就输入为【2,1;4,4】,参考这样的解释看上面的输出结果,即可理解gather的含义。
gather在one-hot为输出的多分类问题中,可以把最大值坐标作为index传进去,然后提取到每一行的正确预测结果,这也是gather可能的一个作用。
pytorch 损失函数NLLLoss和CrossEntropyLoss ()
pytorch enisum函数
pytorch apply()函数
apply(fn):将fn函数递归地应用到网络模型的每个子模型中,主要用在参数的初始化。
pytorch model.state_dict()方法
pytorch 中的 state_dict 是一个简单的python的字典对象,将每一层与它的对应参数建立映射关系.(如model的每一层的weights及偏置等等)
注意:
(1)只有那些参数可以训练的layer才会被保存到模型的state_dict中,如卷积层,线性层等等,像什么池化层、BN层这些本身没有参数的层是没有在这个字典中的;
(2)这个方法的作用一方面是方便查看某一个层的权值和偏置数据,另一方面更多的是在模型保存的时候使用。
pytorch argparse以及dd_argument() 的action使用方法
argparse
argparse 是 Python 内置的一个用于命令项选项与参数解析的模块,通过在程序中定义好我们需要的参数,argparse 将会从 sys.argv 中解析出这些参数,并自动生成帮助和使用信息。当然,Python 也有第三方的库可用于命令行解析,而且功能也更加强大,比如 docopt,Click。
argparse简单实例
我们先来看一个简单示例。主要有三个步骤:
- 创建 ArgumentParser() 对象
- 调用 add_argument() 方法添加参数
- 使用 parse_args() 解析添加的参数
现在我们来简单的测试一下:
1 | import argparse |
打印出来的内容为:
1 | /home/user/anaconda3/bin/python3.6 /home/user/lly/pyGAT-master/test.py |
argparse模块中的action参数
store_true 是指带触发action时为真,不触发则为假,2L说的代码去掉default初始化,其功能也不会变化
parser.add_argument('-c', action='store_true')
#python test.py -c => c是true(触发)
#python test.py => c是false(无触发)
就是要看在运行py文件的时候,是否有带参数,有的话就是触发,否则就是无触发。
触发的话,就是设置True,无触发就是设置false(或者是后面的default),具体参考如下链接实例
一般可以写在脚本script里
https://blog.csdn.net/liuweiyuxiang/article/details/82918911
定制类 廖雪峰python
https://www.liaoxuefeng.com/wiki/1016959663602400/1017590712115904
pytorch dataset与dataloader
Python中json模块的load/loads方法
json格式数据
pytorch chunk()函数
用于对张量分块,参数含义如下:

