2020-09-11 08:30:54.735834: Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 AVX512F FMA 2020-09-11 08:30:54.821023: Successfully opened dynamic library libcuda.so.1 2020-09-11 08:30:55.698894: XLA service 0x5654b4f86600 executing computations on platform CUDA. Devices: 2020-09-11 08:30:55.699000: StreamExecutor device (0): Tesla M60, Compute Capability 5.2 2020-09-11 08:30:55.699022: StreamExecutor device (1): Tesla M60, Compute Capability 5.2 2020-09-11 08:30:55.699042: StreamExecutor device (2): Tesla M60, Compute Capability 5.2 2020-09-11 08:30:55.699062: StreamExecutor device (3): Tesla M60, Compute Capability 5.2 2020-09-11 08:30:55.732911: CPU Frequency: 2100000000 Hz 2020-09-11 08:30:55.738953: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x5654b54aa810 executing computations on platform Host. Devices: 2020-09-11 08:30:55.739001: I tensorflow/compiler/xla/service/service.cc:175] StreamExecutor device (0): <undefined>, <undefined> 2020-09-11 08:30:55.741878: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1640] Found device 0 with properties: name: Tesla M60 major: 5 minor: 2 memoryClockRate(GHz): 1.1775 pciBusID: 0000:b1:00.0 2020-09-11 08:30:55.742665: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1640] Found device 1 with properties: name: Tesla M60 major: 5 minor: 2 memoryClockRate(GHz): 1.1775 pciBusID: 0000:b2:00.0 2020-09-11 08:30:55.743420: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1640] Found device 2 with properties: name: Tesla M60 major: 5 minor: 2 memoryClockRate(GHz): 1.1775 pciBusID: 0000:da:00.0 2020-09-11 08:30:55.744263: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1640] Found device 3 with properties: name: Tesla M60 major: 5 minor: 2 memoryClockRate(GHz): 1.1775 pciBusID: 0000:db:00.0 2020-09-11 08:30:55.744692: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Could not dlopen library 'libcudart.so.10.0'; dlerror: libcudart.so.10.0: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /home/dell2/.mujoco/mjpro150/bin:/usr/local/cuda-10.1/lib64: 2020-09-11 08:30:55.744798: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Could not dlopen library 'libcublas.so.10.0'; dlerror: libcublas.so.10.0: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /home/dell2/.mujoco/mjpro150/bin:/usr/local/cuda-10.1/lib64: 2020-09-11 08:30:55.744891: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Could not dlopen library 'libcufft.so.10.0'; dlerror: libcufft.so.10.0: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /home/dell2/.mujoco/mjpro150/bin:/usr/local/cuda-10.1/lib64: 2020-09-11 08:30:55.744980: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Could not dlopen library 'libcurand.so.10.0'; dlerror: libcurand.so.10.0: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /home/dell2/.mujoco/mjpro150/bin:/usr/local/cuda-10.1/lib64: 2020-09-11 08:30:55.745070: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Could not dlopen library 'libcusolver.so.10.0'; dlerror: libcusolver.so.10.0: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /home/dell2/.mujoco/mjpro150/bin:/usr/local/cuda-10.1/lib64: 2020-09-11 08:30:55.745166: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Could not dlopen library 'libcusparse.so.10.0'; dlerror: libcusparse.so.10.0: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /home/dell2/.mujoco/mjpro150/bin:/usr/local/cuda-10.1/lib64: 2020-09-11 08:30:55.750141: I tensorflow/stream_executor/platform/default/dso_loader.cc:42] Successfully opened dynamic library libcudnn.so.7 2020-09-11 08:30:55.750170: W tensorflow/core/common_runtime/gpu/gpu_device.cc:1663] Cannot dlopen some GPU libraries. Skipping registering GPU devices... 2020-09-11 08:30:55.750542: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1181] Device interconnect StreamExecutor with strength 1 edge matrix: 2020-09-11 08:30:55.750706: 0 1 2 3 2020-09-11 08:30:55.750797: 0: N Y Y Y 2020-09-11 08:30:55.750887: 1: Y N Y Y 2020-09-11 08:30:55.750974: 2: Y Y N Y 2020-09-11 08:30:55.751059: 3: Y Y Y N Device mapping: /job:localhost/replica:0/task:0/device:XLA_GPU:0 -> device: XLA_GPU device /job:localhost/replica:0/task:0/device:XLA_GPU:1 -> device: XLA_GPU device /job:localhost/replica:0/task:0/device:XLA_GPU:2 -> device: XLA_GPU device /job:localhost/replica:0/task:0/device:XLA_GPU:3 -> device: XLA_GPU device /job:localhost/replica:0/task:0/device:XLA_CPU:0 -> device: XLA_CPU device 2020-09-11 08:30:55.757190: I tensorflow/core/common_runtime/direct_session.cc:296] Device mapping: /job:localhost/replica:0/task:0/device:XLA_GPU:0 -> device: XLA_GPU device /job:localhost/replica:0/task:0/device:XLA_GPU:1 -> device: XLA_GPU device /job:localhost/replica:0/task:0/device:XLA_GPU:2 -> device: XLA_GPU device /job:localhost/replica:0/task:0/device:XLA_GPU:3 -> device: XLA_GPU device /job:localhost/replica:0/task:0/device:XLA_CPU:0 -> device: XLA_CPU device
CUDA_VISIBLE_DEVICES=1 Only device 1 will be seen CUDA_VISIBLE_DEVICES=0,1 Devices 0 and 1 will be visible CUDA_VISIBLE_DEVICES="0,1" Same as above, quotation marks are optional CUDA_VISIBLE_DEVICES=0,2,3 Devices 0, 2, 3 will be visible; device 1 is masked CUDA_VISIBLE_DEVICES="" No GPU will be visible1234567
代码中指定
在Python代码中添加以下内容:
1 2
import os os.environ["CUDA_VISIBLE_DEVICES"] = "1"#只使用GPU1

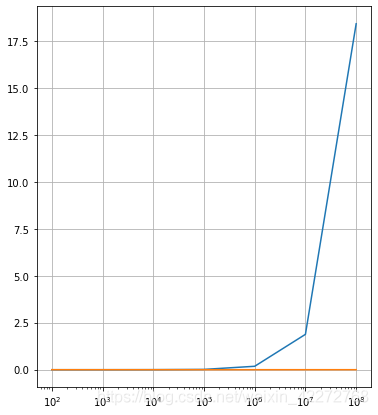 蓝线是cpu的耗时,而红线是gpu的耗时。
蓝线是cpu的耗时,而红线是gpu的耗时。