前言
最近了解了一下小样本学习的相关知识,这几天看了几篇论文介绍如下
综述
Generalizing from a Few Examples : A Survey on Few-Shot Learning
简介
问题
(a)例如典型的 MNIST 分类问题,一共有 10 个类,训练集一共有 6000 个样本,平均下来每个类大约 600 个样本,但是我们想一下我们人类不需要这么多样本,这表明当前的深度学习技术和我们人类智能差距还是很大的,要想弥补这一差距,小样本学习是一个很关键的问题。
- 如果想要构建新的数据集(以分类数据集为例),我们需要标记大量的数据,但是有的时候标记数据集需要某些领域的专家(例如医学图像的标记),这费时又费力,因此如果我们可以解决小样本学习问题,只需要每个类标记几张图片就可以高准确率的给剩余大量图片自动标记。
以上两个原因使得小样本学习的研究成为热点。
小样本学习(Few-Shot Learning,以下简称 FSL )用于解决当可用的数据量比较少时,如何提升神经网络的性能。
定义
以下是FSL的一些符号术语


FSL是机器学习的一个子领域,所以先来介绍一下机器学习定义
机器学习:

给定一个任务T,任务的性能P,给定一些经验E,比如通过训练学习得到的标注数据,可以提升任务T的性能P
以下是简单例子

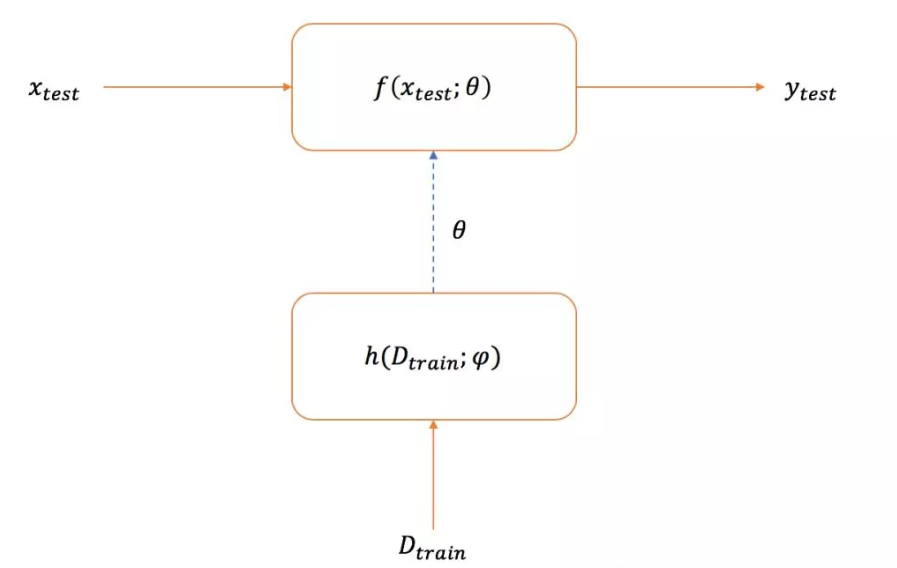
在传统机器学习中需要很多样本信息,但是在实际中是很困难的,所以FSL就是解决这类问题。在训练集Dtrain中提供的监督信息有限的情况下,包括(输入xi和对应的输出yi),来获得好的学习性能
FSL 小样本学习
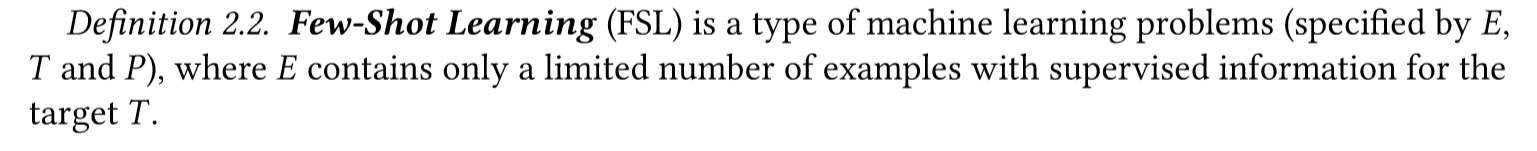
和机器学习定义类似,只是E包含了有限的监督信息的样例(example)。也即,每个类class中包含了很少的有标签样例。
小样本分类主要就是学习一个分类器h,能够预测每一个输入数据xi的标签yi,通常使用的是N-way-K-shot分类方法,N个类,每个类有K个例子。其中 Dtrain包括I=KN个例子
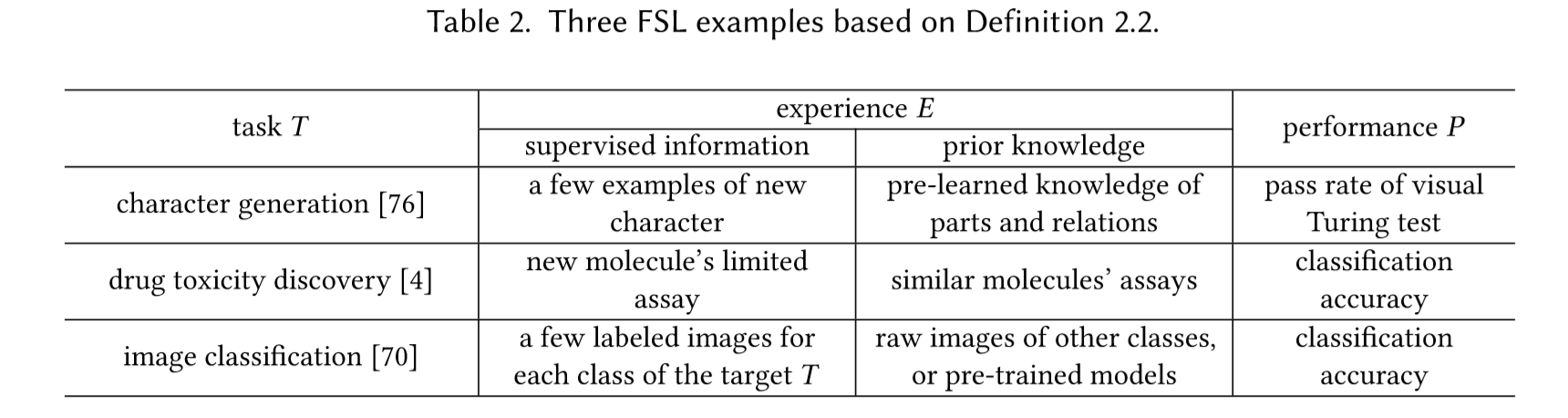
只要关注的是image classification .可以看到相比于机器学习,FSL在经验E部分多了一个prior knowledge,也就是如果只是一些少的监督信息的样例不足以去解决tesk T中的问题,如图像分类。所以还是需要结合一些先验知识。
处理目标T(target T)时,在E中的监督信息如果只有一个例子的话,那么就是one-shot learning。
处理目标T(target T)时,当E中没有任何监督信息例子的话,那么就是zero-shot learning。
Zero-shot Learing 就是训练样本里没有这个类别的样本,但是如果我们可以学到一个好的映射,这个映射好到我们即使在训练的时候没看到这个类,但是我们在遇到的时候依然能通过这个映射得到这个新类的特征。
即:训练集中没有出现过的类别,能自动创造出相应的映射。
主要问题
在机器学习中寻找最适合的假设时通常都是通过找到一组最优的参数来确定这个假设,并通过给定的训练集,最小化损失函数这一目标来指示最优参数的搜索,最小化损失函数如下所示:
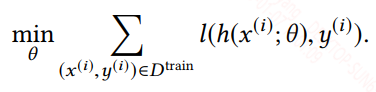
在训练模型中,我们是通过训练集来拟合真实分布,我们训练出来的分布和真实分布往往不一样,这中间的差值称为期望风险(期望损失),表达式如下:
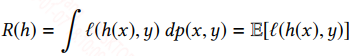
理论上说,让期望风险最下化才能逼近真实分布,但因为你并不知道真实分布,所有最小化期望风险是无法实现的
在机器学习中通常用经验风险来替换期望风险,经验风险就是在训练集上预测的结果和真实结果的差异,也是我们常说的损失函数,表达式如下:
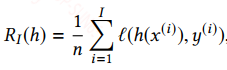
我们给出下面一个符号描述:

h^是真实分布的假设
h∗是假设空间H中最接近h^的假设
而hI是通过最小化经验损失得到的假设。根据机器学习中的误差分解可得:
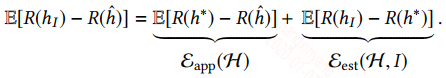
等式右边第一项表示的是假设空间H中最优的假设和真实假设的误差,这一项其实由所选择的模型和参数的初始化分布决定的,这也就是为什么有的时候,模型选择的简单了,给再多的数据也训练不好,欠拟合。
第二项就是训练得到的假设和H中最优假设的误差,我们训练得到的假设也是从假设空间H中选择的,但有时候会陷入局部最优,或者提供的训练数据分布有偏差,导致无法到全局最优。
但理论上对于第二项,当样本数量II足够大时,有:
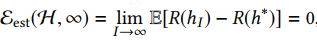

传统的机器学习都是建立在大规模的训练数据上的,因此εest(H,I)是很小的,但是在FSL任务上,训练数据很小,因此εest(H,I)是很大的,此时采用传统的训练模式,如softmax+交叉熵,是极容易陷入过拟合的。
所以需要更多的先验知识
具体的图如下:

解决方法-分类:
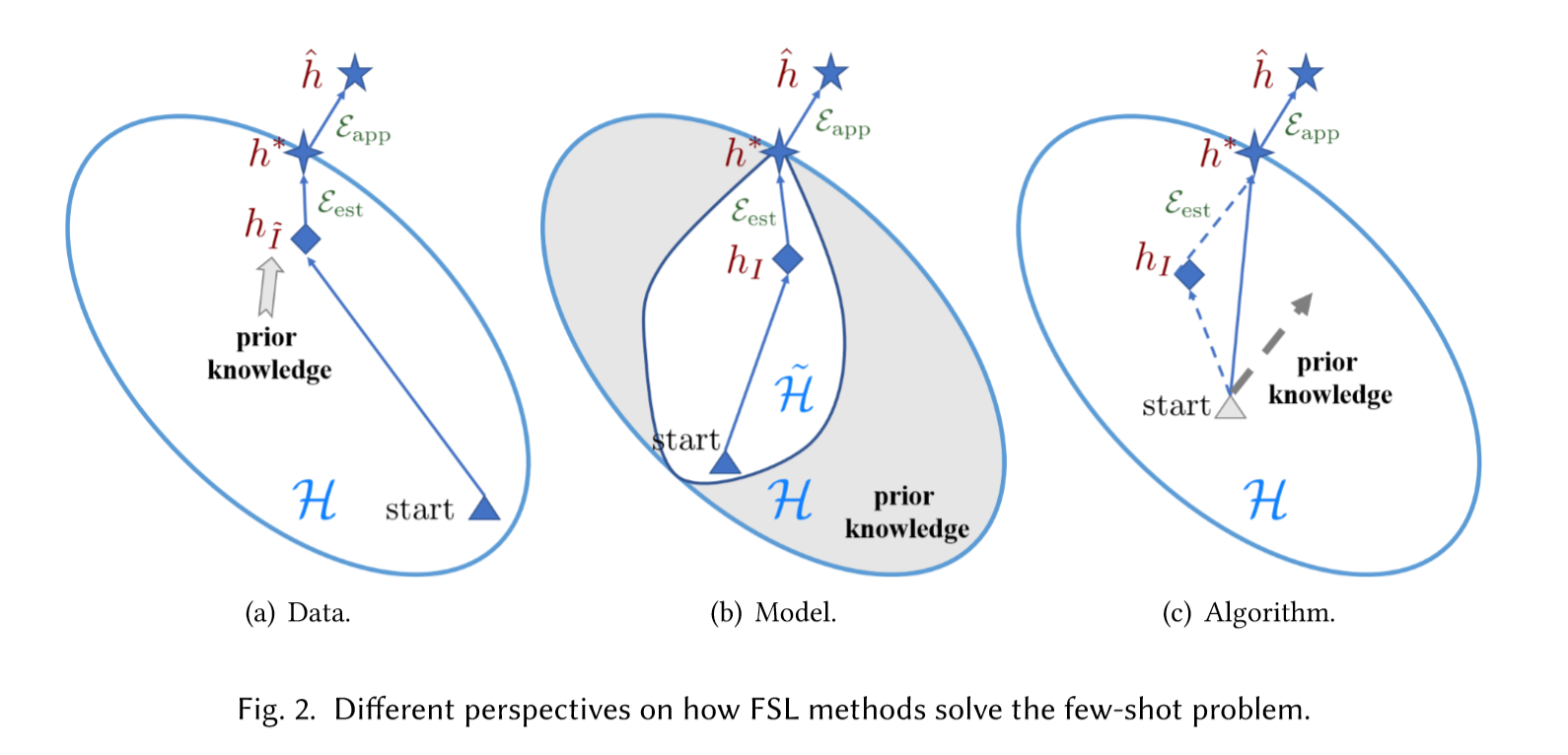
假设空间的确定就是模型函数的可行性范围
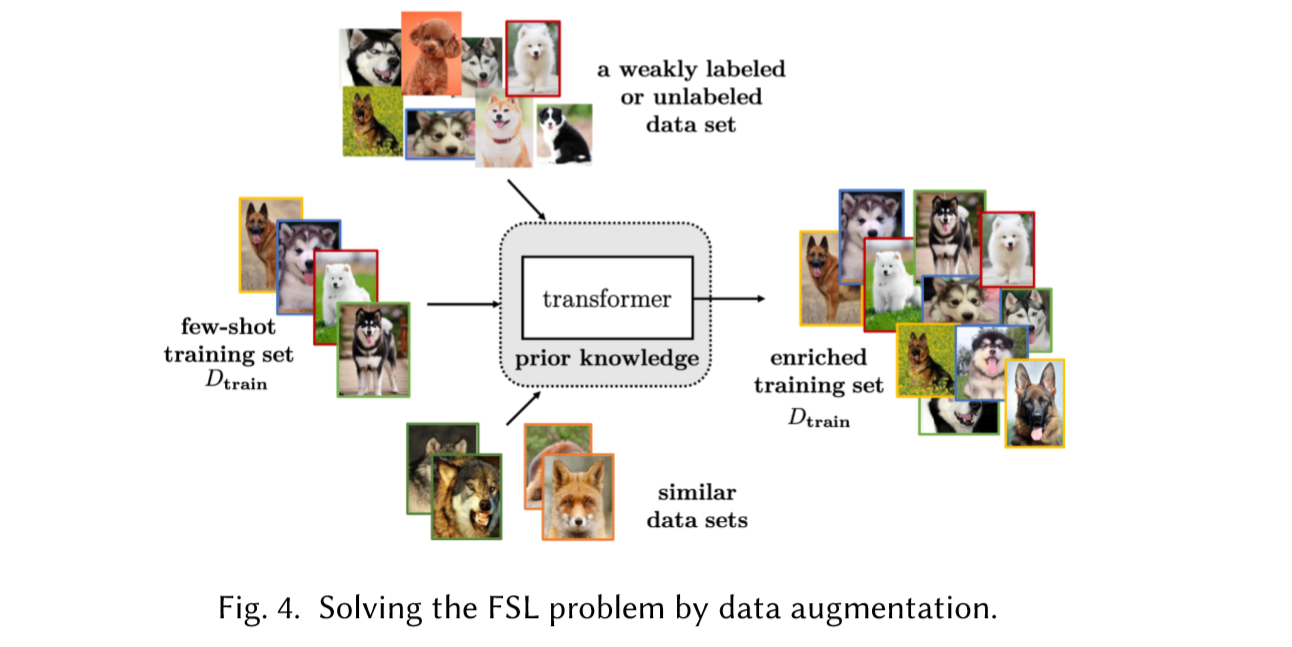
Data
Data就是通过先验知识来做数据增强, 数据量增大可以获得可靠的hI,自然能解决上述问题。
通常进行手动操作对FSL进行数据预处理。例如在图像上,比如图片的旋转剪切放缩等,句子中的同义词替换等,以及复杂的生成模型生成和真实数据相近的数据。数据增强的方式有很多种,大量的合适的增强一定程度上可以缓解FSL问题,但需要耗费大量的精力,以及很强的域知识,只是针对特定的数据集,很难应用到其它数据集中,因此不能很好的解决FSL问题
分类

Model
通过先验知识来限制模型复杂度,降低假设空间H的大小,使得当前的数据集可以满足
如果我们想使用机器学习模型来解决FSL问题,我们需要使用假设空间H很小的模型,这样样本复杂度也就小了,对于一些简单的任务,这样是可行的,但是对于复杂的任务,小的模型会导致εapp(H)很大,而现实中大多数任务都很复杂,它们的特征很多,且特征维度也很高。
因此我们只能一开始给一个假设空间H很大的模型,然后通过一些先验知识将这个空间中无效的hypothesis去掉,缩小假设空间H,但实际上和模型剪枝中的理念类似,你一开始给一个小的模型,这个模型空间离真实假设太远了,而你给一个大的模型空间,它离真实假设近的概率比较大,然后通过先验知识去掉哪些离真实假设远的假设。
Algorithm
通过先验知识来提供一个好的搜索策略,可以是一个好的搜索起始点,也可以是一个明确的搜索策略,来寻找最优点。
在机器学习中我们通常使用SGD以及它的变体,如ADAM,RMSProp等来更新参数,寻找最优的参数,对应到假设空间H中最优的假设h∗。这种方式在有大量的数据集的情况下可以用来慢慢迭代更新寻找最优参数,但是在FSL任务中,样本数量很少,这种方法就失效了。在这一节,我们不再限制假设空间。
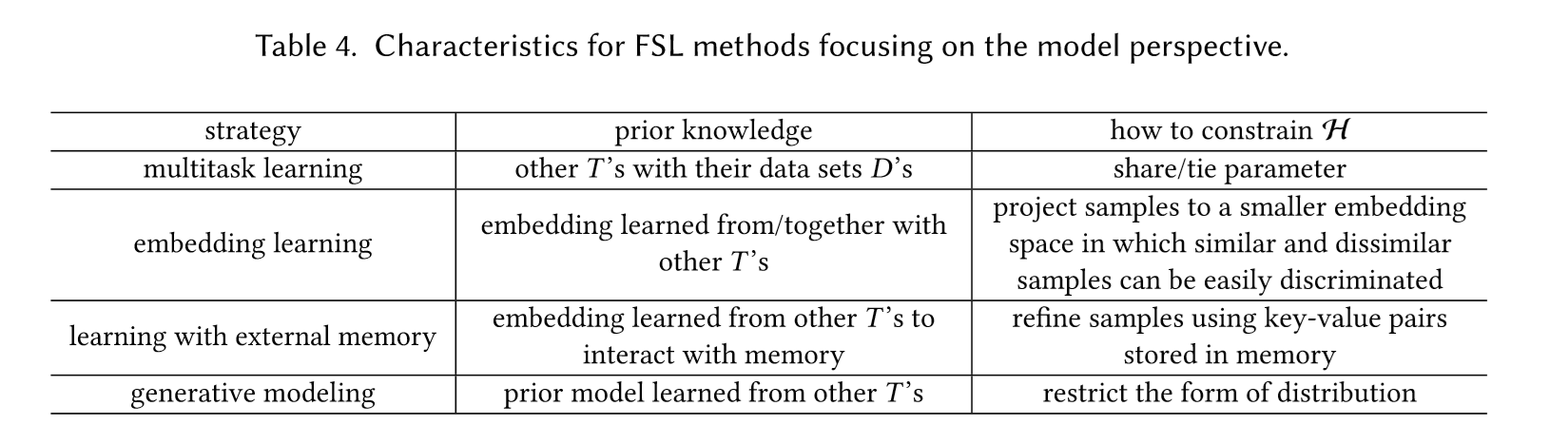
根据使用不同的先验知识,可以将ALGORITHM分为下面3类:

接下来的工作都是围绕这几个方向展开来求解FSL问题。
应用
Few-shot Learning Meta Learning 在监督学习领域的应用。
Meta Learning研究Task!
Meta Learning,又称为 learning to learn,在 meta training 阶段将数据集分解为不同的 meta task,去学习类别变化的情况下模型的泛化能力,在 meta testing 阶段,面对全新的类别,不需要变动已有的模型,就可以完成分类。如果我们构建的深度学习系统能够学到先验知识,并且能够利用这些知识,我们就可以在新的问题上学的更快更好!那么,这个就是Meta Learning要做的事情了
不是要学一个具体的模型,我们要学的是一个先验知识。如果我们已有的先验知识来帮助我们解决新的问题,那么我们对于新的问题就可以不需要那么多的样本,从而解决 few-shot 问题。
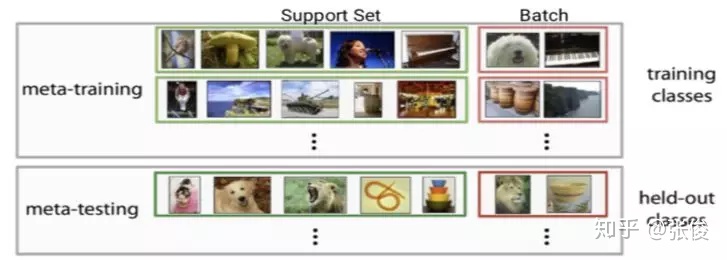
形式化来说,few-shot 的训练集中包含了很多的类别,每个类别中有多个样本。在训练阶段,会在训练集中随机抽取 C 个类别,每个类别 K 个样本(总共 CK 个数据),构建一个 meta-task,作为模型的支撑集(support set)输入;再从这 C 个类中剩余的数据中抽取一批(batch)样本作为模型的预测对象(batch set)。即要求模型从 C*K 个数据中学会如何区分这 C 个类别,这样的任务被称为 C-way K-shot 问题。
图 1 展示的是一个 2-way 5-shot 的示例,可以看到 meta training 阶段构建了一系列 meta-task 来让模型学习如何根据 support set 预测 batch set 中的样本的标签;meta testing 阶段的输入数据的形式与训练阶段一致(2-way 5-shot),但是会在全新的类别上构建 support set 和 batch。每一行都是一个task,包含了task的train set和test set。
我们可以把每一个task当做一个meta learning的训练样本。我们要通过多种task的训练,从而在Meta-test的时候也就是在新的task上取得好效果。
 ▲ 图1:Few-shot Learning示例
▲ 图1:Few-shot Learning示例
通常解决办法
HyperNetwork 生成参数
HyperNetwork 简单说就是用一个网络来生成另外一个网络的参数。
那么我们这里非常直接,我们的设想就是希望用一个hypernetwork输入训练集数据,然后给我输出我的对应模型也就是上图f的参数,我们希望输出的这个参数能够使得在测试图片上取得好的识别效果。
有了这样设计,这个hypernetwork其实就是一个meta network。大家可以看到,本来基本的做法是用训练集直接训练这个模型f,但是现在我们用这个hypernetwork不训练了,直接给你输出参数,这等价于hypernetwork学会了如何学习图像识别,这也是为什么meta learning也同时叫做learning to learn的原因。
训练
训练过程中,每次训练(episode)(Dtrain | Dtest)都会采样得到不同 meta-task,所以总体来看,训练包含了不同的类别组合,这种机制使得模型学会不同 meta-task 中的共性部分,比如如何提取重要特征及比较样本相似等,忘掉 meta-task 中 task 相关部分。通过这种学习机制学到的模型,在面对新的未见过的 meta-task 时,也能较好地进行分类。
这里有个所谓的episodic training!一个episode就是包含了一个task,有训练集有测试集。我们使用训练集输入到hypernetwork,得到f的参数,然后使用测试集输入到f 得到预测的标签,最后用测试集的样本标签得到模型的loss,之后就用梯度下降进行训练。所以我们可以看到,整个模型是端到端的。通过大量的episodic training,也就是大量的task进行训练,我们就可以训练出一个模型出来。
在 meta training 阶段将数据集分解为不同的 meta task,去学习类别变化的情况下模型的泛化能力,在 meta testing 阶段,面对全新的类别,不需要变动已有的模型,就可以完成分类。
其它
inductive learning 与 transductive learning
在训练过程中,已知testing data(unlabelled data)是transductive learing
在训练过程中,并不知道testing data ,训练好模型后去解决未知的testing data 是inductive learing
通俗地来说inductive learning是特殊到一般的学习,测试数据只是用来测试这个通用模型的好坏;transductive learning是特殊到特殊的学习,目的就是解决target domain的问题。

现在有这个问题,已知ABC的类别,求问号的类别,
inductive learning就是只根据现有的ABC,用比如kNN距离算法来预测,在来一个新的数据的时候,还是只根据5个ABC来预测。
transductive learning直接以某种算法观察出数据的分布,这里呈现三个cluster,就根据cluster判定,不会建立一个预测的模型,如果一个新的数据加进来 就必须重新算一遍整个算法,新加的数据也会导致旧的已预测问号的结果改变
representation learning
在机器学习领域,表征学习(或特征学习)是一种将原始数据转换成为能够被机器学习有效开发的一种技术的集合。在特征学习算法出现之前,机器学习研究人员需要利用手动特征工程(manual feature learning)等技术从原始数据的领域知识(domain knowledge)建立特征,然后再部署相关的机器学习算法。
特征学习弥补了这一点,它使得机器不仅能学习到数据的特征,并能利用这些特征来完成一个具体的任务。
表征学习的目标不是通过学习原始数据预测某个观察结果,而是学习数据的底层结构(underlying structure),从而可以分析出原始数据的其它特性。
特征学习可以被分为两类:监督式特征学习(Supervised Representation Learning)和无监督式特征学习(Unsupervised Representation Learning)。
在监督特征学习中,被标记过的数据被当做特征用来学习。例如神经网络(Neural Networks),多层感知器(Multi-Layer Perception),监督字典学习(Supervised Dictionary Learning)。
在无监督特征学习中,未被标记过的数据被当做特征用来学习。例如无监督字典学习(Unsupervised Dictionary Learning),主成分分析(Principal Component Analysis),独立成分分析(Independent Component Analysis),自动编码(Auto-encoders),矩阵分解(Matrix Factorization) ,各种聚类分析(Clustering)及其变形。
https://www.jiqizhixin.com/graph/technologies/64d4c374-6061-46cc-8d29-d0a582934876
论文-Edge-Labeling Graph Neural Network for Few-shot Learning
CVPR 2019
code url: https://github.com/khy0809/fewshot-egnn
Abstract
在本文中,提出了一种新颖的边标记图神经网络(edge-labeling graph neural network )(EGNN),该网络将边标记图上的深层神经网络应用于小样本学习。
以前在小样本学习中使用的图神经网络(GNN)方法是基于节点标记框架( node-labeling framework)的,该框架对聚类内的相似度和聚类间不相似度进行隐式地建模(implicitly modeling)。 相反,提出的EGNN学会预测图上的边标签,而不是节点标签,从而通过直接利用聚类内的相似性和聚类间不相似性来迭代更新边标签,从而实现显式聚类的进化。 它也非常适合在各种类别上执行而无需重新训练,并且可以轻松扩展以执行直推推理(transductive inference)。
EGNN的参数是通过带有边标记损失(edge-labeling loss)的episodic training来学习的,从而获得了针对未见的低数据问题的可普遍推广的模型。
在带有两个基准数据集的有监督和半监督的小样本图像分类任务上,提出的EGNN大大提高了现有GNN的性能。
对GNN的改进,提高了GNN的性能
预测图上的边标签,而不是节点标签,直接利用聚类内的相似性和聚类间不相似性来迭代更新边标签,从而实现显式聚类的进化。
背景
GNN可以很好的处理数据之间丰富的关系结构,是迭代地通过消息传递(message passing)从邻居节点进行特征聚合。而小样本学习算法已显示要求充分利用support集和query集之间的关系,因此使用GNN可以自然地解决小样本学习问题。
GNN解决小样本学习问题的思路:
先建立一个从support到query的全连接的图,节点使用嵌入向量和独热编码label表示,通过邻居聚合迭代的更新节点feature,完成对query的分类。
问题
然而以前在小样本学习中使用的图神经网络(GNN)方法是基于节点标记框架( node-labeling framework)的,该框架对聚类内的相似度和聚类间不相似度进行隐式建模(implicitly modeling)。
解决
提出的EGNN学会预测图上的边标签,而不是节点标签,从而通过直接利用聚类内的相似性和聚类间不相似性来迭代更新边标签,从而实现显式聚类的进化。
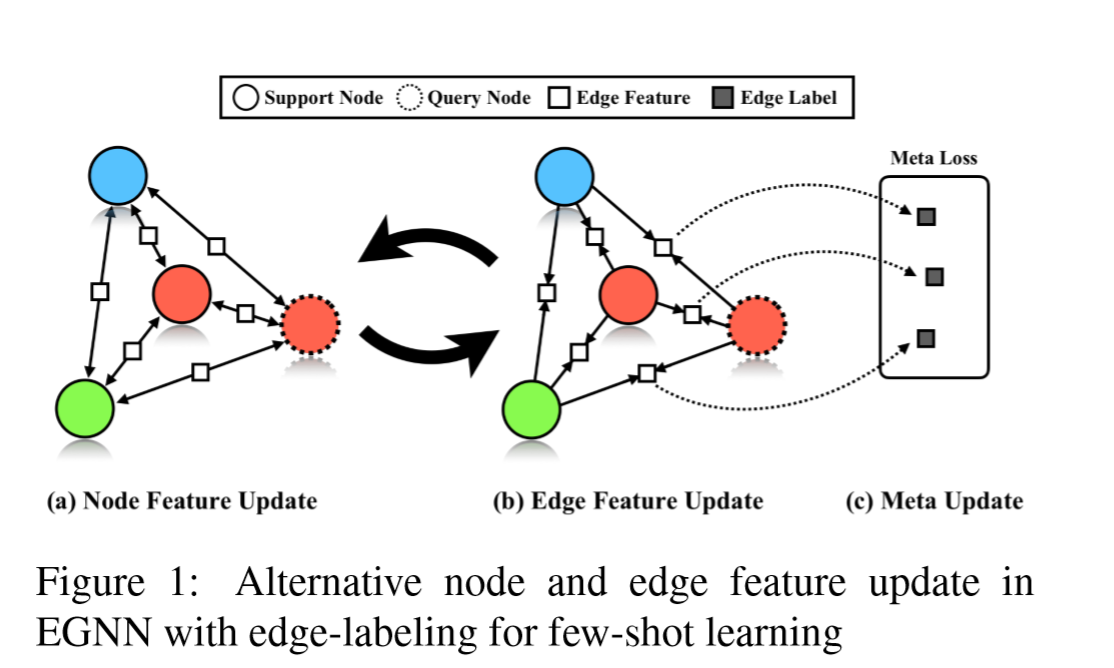
贡献
EGNN首次使用边标注的方式构建,利用的是 episodic training framework
在小样本分类的有监督和半监督任务中,表现超过了所有的GNN。同时,证明显式聚类和分别利用类内相似、类间不同都是有效的。
模型
术语介绍

过程
每个episode中的支持集S都用作标记的训练集,在该训练集上训练模型以最小化其在查询集Q上的预测损失。此训练过程逐个episode反复进行,直到收敛为止。
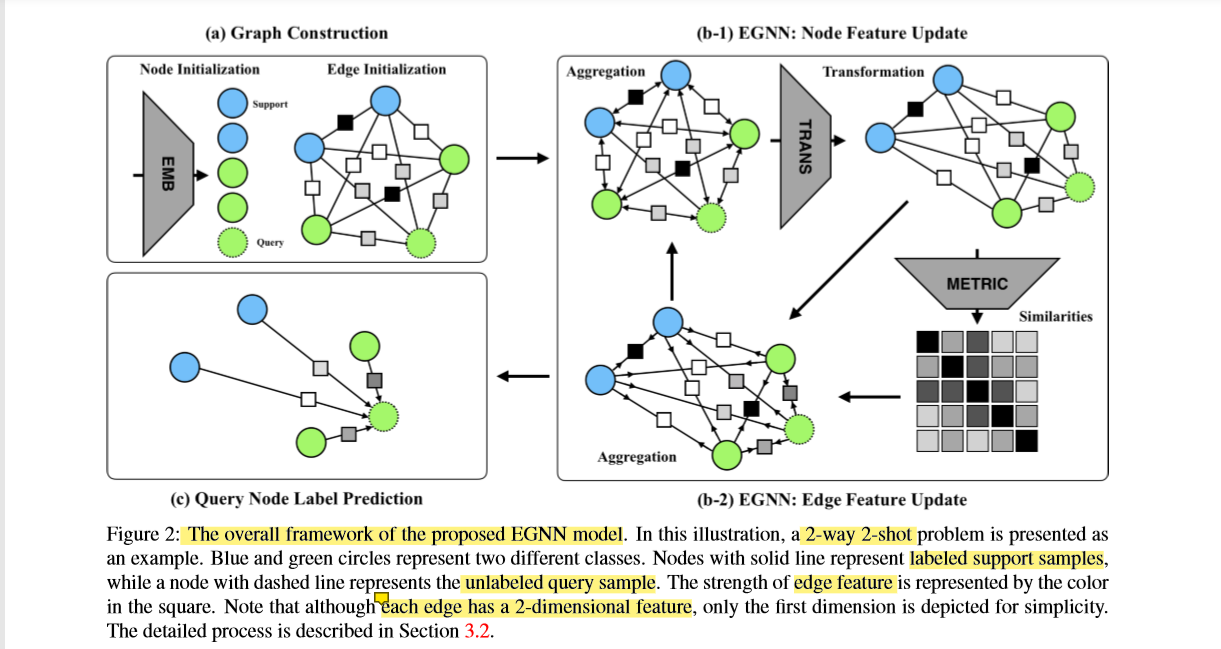
给出tesk所有样本的特征表示,那么就可以构建一个全连接图,其中每个节点代表一个样本,每个边代表两个连接点之间的关系。
伪代码

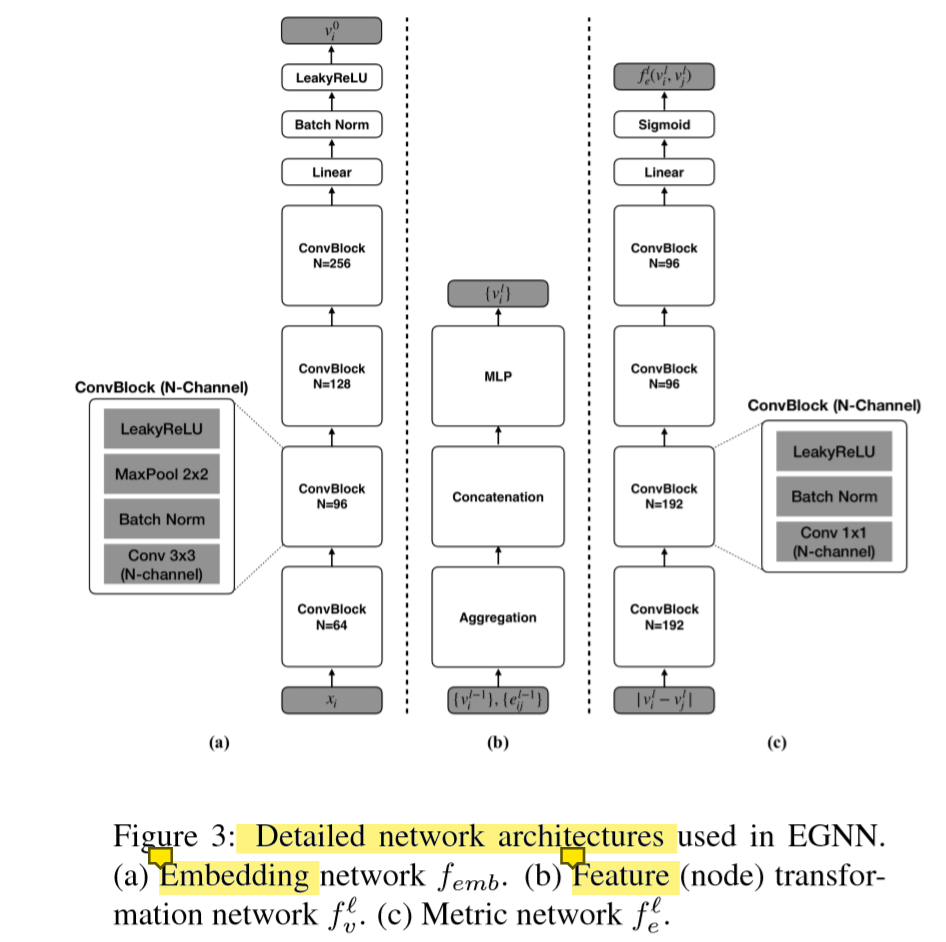
我们可以看到,这个整体更新的方式像极了EM算法。 第一步是获取特征,这个embedding的网络在文章的图3。
点特征先通过图(a)的卷积嵌入网络进行初始化, 边特征也被初始化如下面公式 第二步是初始化边
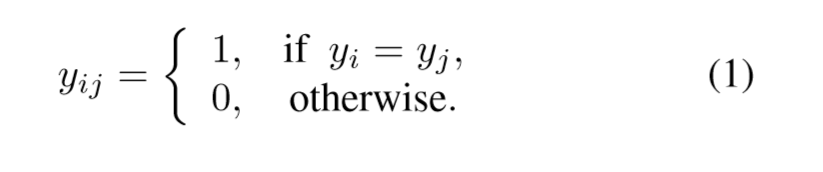
如果两个点是同一个标签,那么就是1, 否则就是0
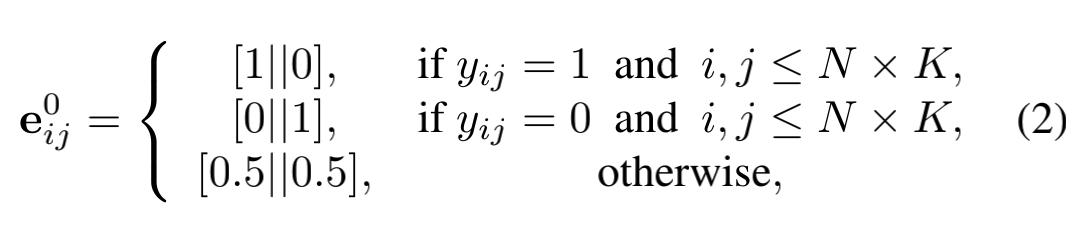
如果其是同一类,或者其不是同一类,或者其相邻节点不属于支持集
第三步是进入一个更新循环。
第四步是更新节点 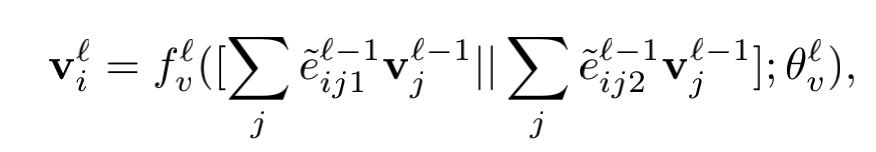
是把边的不同维数的特征(分别代表类内,和类间(相似性和不相似性))和节点特征相乘,然后2个结果做连接操作,作为参数传入神经网络,得到更新之后的节点特征,这个时候的节点特征就是包含了相应的边的语意信息了。信息更加饱满。
可以看到图中就是先进行算法,然后连接操作,然后进入一个多层感知机,最后得到更新之后的节点信息。 其中:eijd是做了归一化操作,f是点转移网络(transformation network)
第五步是更新边 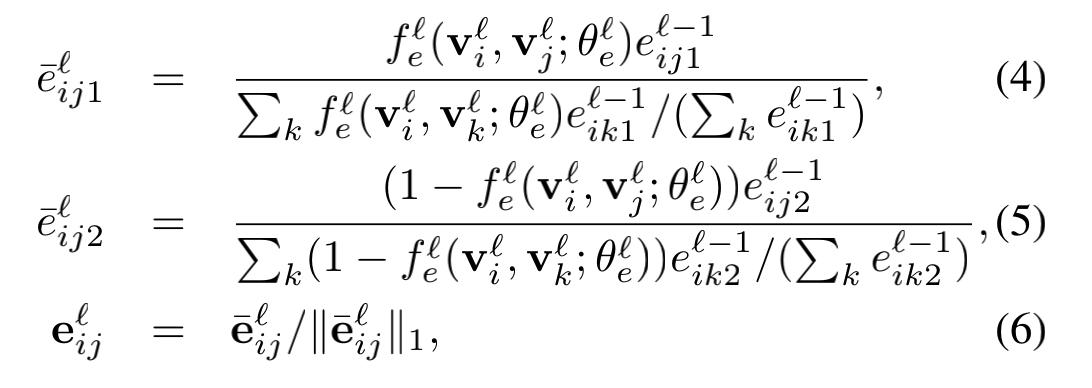
然后不断进行第四五步的循环L次,结束后计算出我们要测试的数据所属于的类的概率。
最终的边标签预测结果就是最后的边特征

损失函数
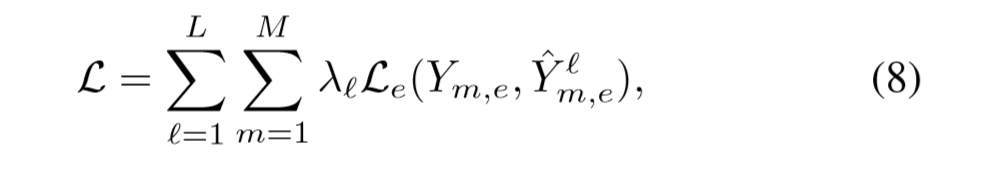

L代表第L层,M代表M个任务,这个是episodic training可以理解为多任务。
λ是学习率,L是二元交叉滴损失,Y是真实的标签,Yˆ是预测的标签。就是说损失函数是所有M个任务L层的所有损失的和。
小样本的预训练
预训练是(Pre-training)大家都熟悉且非常有效的获取先验知识的方法。具体就是在大型数据集上,学习一个强大的神经网络作为特征提取器,例如CV里面常见的在ImageNet上预训练的ResNet网络,或是NLP里面在Wikipedia上训练的BERT,都代表一种特征表达的先验知识。
在预训练基础上,我们只需在样本数量少的目标任务中,微调部分(例如只训练最后一层fc分类器)或者全部网络的参数,便得到了一个可以解决小样本学习问题的模型。
预训练相当于给了小样本学习一个好的起点,就像一个人在上课前预习了大量的知识点。不过想要更上一层楼,还需要有效的学习方法。元学习(meta learning)的目的就是找到这种方法。具体来说,我们可以从预训练集中,每次采样出来一个“沙盒”版小样本任务,例如选5个类,每个类选5张图片作为训练集(support set),再选15张作为测试集(query set),然后我们要求模型在support set训练的结果,能够在query set上面取得好的表现。其实这种学习策略在我们身边随处可见,例如准备考试的时候,我们会提前做一些模拟测试,了解题型,规划答题节奏等等,这就是一种元学习。在小样本学习的实际操作中,我们可以使用元学习训练一个模型的初始化参数(MAML),或是一个分类器参数的生成网络(LEO)等等。通过元学习得到的知识,就构成了一种学习方法的先验知识,在预训练的网络之上,进一步提升小样本学习的表现。
预训练是小样本学习中一个核心的环节,无论是基于微调的,还是基于元学习的方法,都以预训练为开始。那么从常理来说,更强的预训练,应该会带来更好的小样本学习的表现,例如在现有文献中,使用更深层的神经网络架构WRN-28-10的微调结果,往往会比相对较浅的ResNet-10表现好很多。
利用其它的网络进行预训练,然后再进行元学习+微调,或者直接微调操作
小样本学习的解决思路,可以用下面这张图来概括:我们先在一个大的数据集 D 上面预训练一个特征提取网络Ω ,之后我们既可以直接使用 Ω在每一个小样本任务中微调(红色方块的Fine-Tuning);
也可以进一步使用元学习(Meta-Learning),将D 拆成一个个由support set S和query set Q 组成的沙盒任务(Si,Qi) ,训练高效的学习方法;元学习结束以后,我们就可以用这种高效的学习方法,在小样本学习的任务中进行微调(绿色方块的Fine-Tuning)。
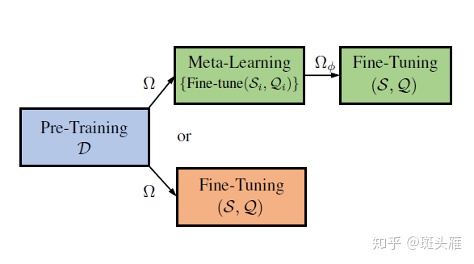 小样本学习的两种解决思路。
小样本学习的两种解决思路。
小样本的演变
小样本学习一般会简化为N-way K-shot问题,如图[1]。其中N代表类别数量,K代表每一类中(支持集)的样本量;
![图[1] N-way K-shot](https://i.loli.net/2020/10/20/9lRfqxs1U8uP6Fo.jpg)
解决分类问题,人们最先想到的是采用传统监督学习的方式,直接在训练集上进行训练,在测试集上进行测试,如图[2],但神经网络需要优化的参数量是巨大的,在少样本条件下,几乎都会发生过拟合;
![图[2] 传统监督学习](https://i.loli.net/2020/10/20/xrJlIDiOtwfLoj8.jpg)
为了解决上述问题,人们首先想到的是通过使用迁移学习+Fine-tune的方式,利用Base-classes中的大量数据进行网络训练,得到的Pre-trained模型迁移到Novel-classes进行Fine-tune,如图[3]。虽然是Pre-trained网络+Fine-tune微调可以避免部分情况的过拟合问题,但是当数据量很少的时候,仍然存在较大过拟合的风险。
![图[3] Pre-trained网络+Fine-tune微调](https://i.loli.net/2020/10/20/H84WS5KRIuoQ2bs.jpg)
接下来讲的就是小样本学习中极具分量的Meta-learning方法,现阶段绝大部分的小样本学习都使用的是Meta-learning方法。Meta-learning,即learn to learn,翻译成中文是元学习。Meta-learning共分为Training和Testing两个阶段,Training阶段的思路如图[4]。简单描述下流程:
1:将训练集采样成Support set和Query set两部分;
2:基于Support set生成一个分类模型;
3:利用模型对Query set进行分类预测生成predict labels;
4:通过query labels和predict labels进行Loss(e.g., cross entropy loss )计算,从而对分类模型中的参数θ进行优化。
![图[4] Meta-learning Training阶段思路](https://i.loli.net/2020/10/20/yGt6YfLuJADW5rx.jpg)
Testing阶段的思路如图[5],利用Training阶段学来的分类模型在Novel class的Support set上进行进一步学习,学到的模型对Novel class的Query set进行预测。
![图[5] Meta-learning Testing阶段思路](https://i.loli.net/2020/10/20/oE2RtPAfVxOrI9L.jpg)
介绍到这里,Meta-learning的整体流程的流程就介绍完了,如图[6];
现在反过来看,Meta-learning核心点之一是如何通过少量样本来学习这个分类模型,即图[6]中的keyu部分。
![图[6] Meta-learning整体流程以及key point](https://i.loli.net/2020/10/20/FNi5PM4fruDKWaH.jpg)
⭐ 预训练与微调
假设我们想从图像中识别出不同种类的椅子,然后将购买链接推荐给用户。一种可能的方法是先找出100种常见的椅子,为每种椅子拍摄1,000张不同角度的图像,然后在收集到的图像数据集上训练一个分类模型。这个椅子数据集虽然可能比Fashion-MNIST数据集要庞大,但样本数仍然不及ImageNet数据集中样本数的十分之一。这可能会导致适用于ImageNet数据集的复杂模型在这个椅子数据集上过拟合。同时,因为数据量有限,最终训练得到的模型的精度也可能达不到实用的要求。
为了应对上述问题,一个显而易见的解决办法是收集更多的数据。然而,收集和标注数据会花费大量的时间和资金。例如,为了收集ImageNet数据集,研究人员花费了数百万美元的研究经费。虽然目前的数据采集成本已降低了不少,但其成本仍然不可忽略。
另外一种解决办法是应用迁移学习(transfer learning),将从源数据集学到的知识迁移到目标数据集上。例如,虽然ImageNet数据集的图像大多跟椅子无关,但在该数据集上训练的模型可以抽取较通用的图像特征,从而能够帮助识别边缘、纹理、形状和物体组成等。这些类似的特征对于识别椅子也可能同样有效。
本节我们介绍迁移学习中的一种常用技术:微调(fine tuning)。如图所示,微调由以下4步构成。
在源数据集(如ImageNet数据集)上预训练一个神经网络模型,即源模型。
创建一个新的神经网络模型,即目标模型。它复制了源模型上除了输出层外的所有模型设计及其参数。我们假设这些模型参数包含了源数据集上学习到的知识,且这些知识同样适用于目标数据集。我们还假设源模型的输出层与源数据集的标签紧密相关,因此在目标模型中不予采用。
为目标模型添加一个输出大小为目标数据集类别个数的输出层,并随机初始化该层的模型参数。
在目标数据集(如椅子数据集)上训练目标模型。我们将从头训练输出层,而其余层的参数都是基于源模型的参数微调得到的。
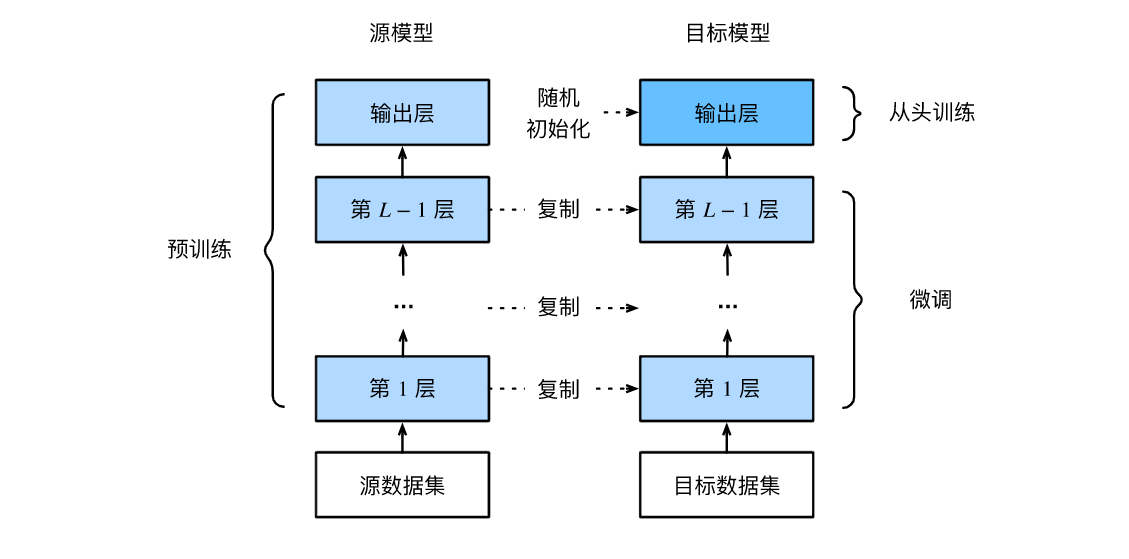
当目标数据集远小于源数据集时,微调有助于提升模型的泛化能力。
小结
- 迁移学习将从源数据集学到的知识迁移到目标数据集上。微调是迁移学习的一种常用技术。
- 目标模型复制了源模型上除了输出层外的所有模型设计及其参数,并基于目标数据集微调这些参数。而目标模型的输出层需要从头训练。
- 一般来说,微调参数会使用较小的学习率,而从头训练输出层可以使用较大的学习率。
⭐ 具体实例可以参考下面的链接
