transformer和GNN的关系
Transformer和GNN有什么关系?一开始可能并不明显。但是通过这篇文章,你会从GNN的角度看待Transformer的架构,对于原理有更清楚的认知。
通过这篇博文,现为南洋理工大学助理研究员Chaitanya Joshi 将为读者介绍图神经网络和 Transformer 之间的内在联系。具体而言,作者首先介绍 NLP 和 GNN 中模型架构的基本原理,使用公式和图片来加以联系,然后讨论怎样能够推动这方面的进步。
transformer是GNN的一种特例
NLP 中的表示学习
从一个很高的角度来看,所有的神经网络架构都是对输入数据构建表示(representations)——以向量或嵌入矩阵的形式。这种方法将有用的统计或语义信息进行编码。
这些隐表示(latent or hidden representations)可以被用来进行一些有用的任务,如图像分类或句子翻译。神经网络通过反馈(即损失函数)来构建更好的表示。
对于 NLP 来说,传统上,RNN 对每个词都会建立一个表示——使用序列的方式。例如,每个时间步一个词。从直观上来说,我们可以想象,一个 RNN 层是一个传送带。词汇以自回归(autoregressively)的方式从左到右被处理。在结束的时候,我们可以得到每个词在句子中的隐藏特征,然后将这些特征输入到下一个 RNN 层中,或者用到任务中去。
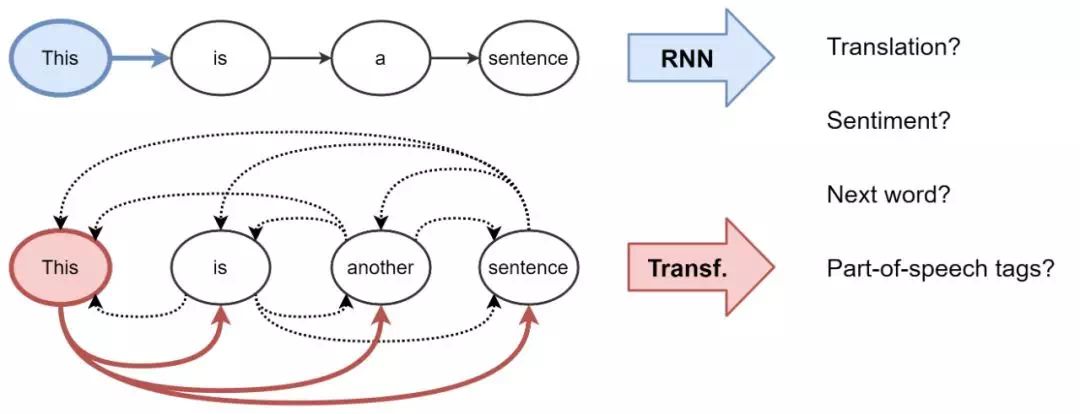
从机器翻译开始,Transformer 就逐渐开始取代 RNN。这一模型有着新的表示学习策略。它不再使用递归,而是使用注意力机制对每个词构建表示——即每个词语在句子中的重要程度。知道了这一点,词的特征更新则是所有词的线性变换之和——通过其重要性进行加权。
解析Transformer
通过将前一段翻译成数学符号以及向量的方式去创建对整个体系结构的认知。将长句 S 中的第 i 个单词的隐藏特征 h 从 ℓ 层更新至ℓ+1 层:
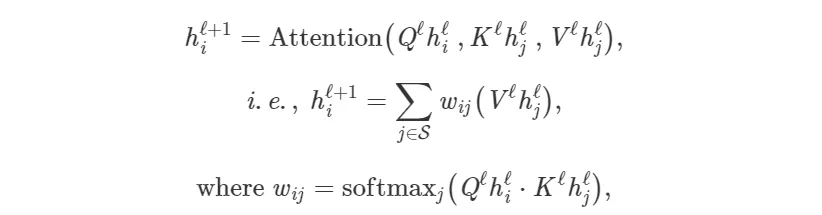
其中 j∈S 为句子中单词的集合,Qℓ、Kℓ、V^ℓ为可学习的线性权重(分别表示注意力计算的 Query、Key 以及 Value)。针对句子中每个单词的并行执行注意力机制,从而在 one shot 中(在 RNNs 转换器上的另外一点,逐字地更新特征)获取它们的更新特征。
我们可通过以下途径更好地理解注意力机制:
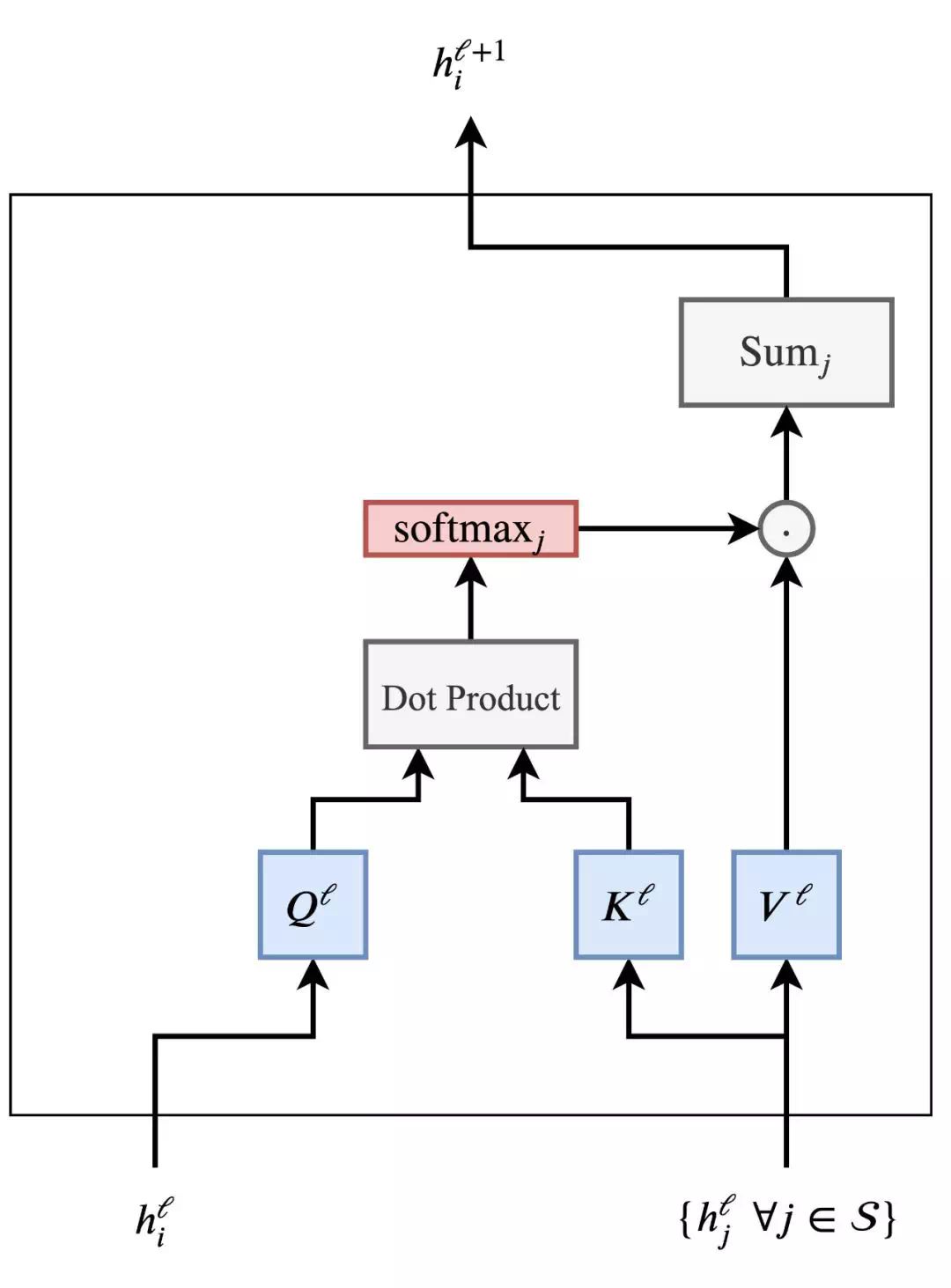
考虑到 h_j^l; ∀j∈S 句中 h_i^l 和其他词的特征,通过点积计算每对(i,j)的注意力权重,然后在所有 j 上计算出 softmax。最后通过所有 h_j^l 的权重进行相应的加权,得到更新后的单词特征 h_i^l+1。
多头注意力机制
让点积注意力机制发挥作用是被证明较为棘手:糟糕的随机初始化可能会破坏学习过程的稳定性,此情况可以通过并行执行多头注意力将结果连接起来,从而克服这个问题(而每个「head」都有单独的可学习权重):
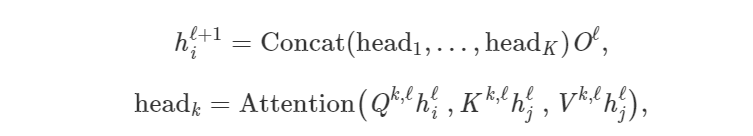
其中 Qk,ℓ、Kk,ℓ、V^k,ℓ是第 K 个注意力 head 的可学习权重,O^ℓ 是向下的投影,用以匹配 h_i^l+1 和 h_i^l 跨层的维度。
通过观察上一层中隐藏特征的不同的变换过程以及方面,多头机制允许注意力机制从本质上“规避风险”。关于这点,我们将在后面详细讨论。
尺度问题和前向传播子层
促使形成最终形态的Transformer结构的关键问题点是,注意机制之后的词的特征可能在不同的尺度或重要性上:1)这可能是由于某些词在将其他词的特征累加时具有非常集中或非常分散的注意力权重 w_ij;(2)在单个特征/向量输入级别,跨多个注意力头(每个可能会以不同的比例输出值)进行级联可以导致最终向量 h_i^ℓ+1的输入具有一个大范围的值。遵循传统的机器学习思路,在上述流程中增加一个归一化层似乎是一个合理的选择。

Transformers使用LayerNorm克服了问题(2),LayerNorm在特征层级上进行归一化并学习一种仿射变换。此外,通过求特征维度的平方根来缩放点积注意力有助于抵消问题(1)。
最后,作者提出了控制尺度问题的另一个“技巧”:具有特殊结构的考虑位置的双层MLP。在多头注意力之后,他们通过一个可学习的权重 h_i^ℓ+1 将投影到一个更高的维度,在该维度中, h_i^ℓ+1 经过ReLU非线性变换,然后投影回其原始维度,然后再进行另一个归一化操作:
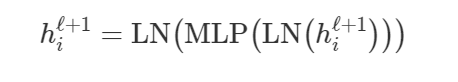
说实话,我不确定超参数化前馈子层背后的确切理由是什么,似乎也没有人对此提出疑问!我认为LayerNorm和缩放的点积不能完全解决突出的问题,因此大型MLP是一种可以相互独立地重新缩放特征向量的手段。
Transformer层的最终形态如下所示:
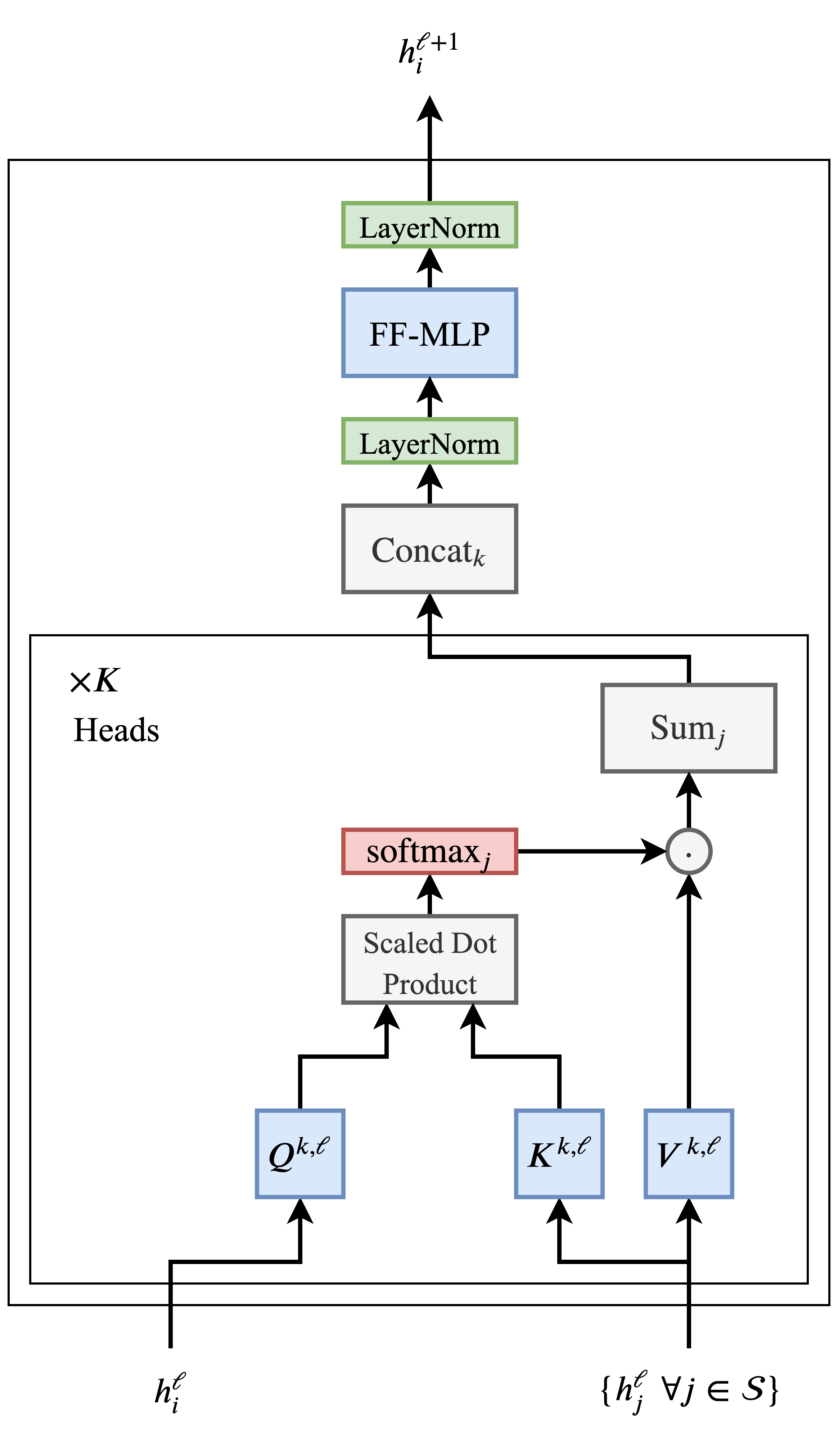
Transformer架构也非常适合非常深的网络,使NLP界能够在模型参数和扩展数据这两方面进行延伸。
每个多头注意力子层和前馈子层的输入和输出之间的残差连接是堆叠Transformer层的关键(但为了清楚起见,在上图中省略了)。
GNNs构建图的表示
图卷积网络是图神经网络的一个分类
图神经网络(GNNs)或图卷积网络(GCNs)在图数据中建立节点和边的表示(representations)。它们是通过邻域聚合(或消息传递)(neighbourhood aggregation or message passing)来实现的,在邻域聚合中,每个节点从其邻域收集特征,以更新其周围的局部图结构表示。通过堆叠多个GNN层使得该模型可以将每个节点的特征传播到整个图中,从其邻居传播到邻居的邻居,依此类推。
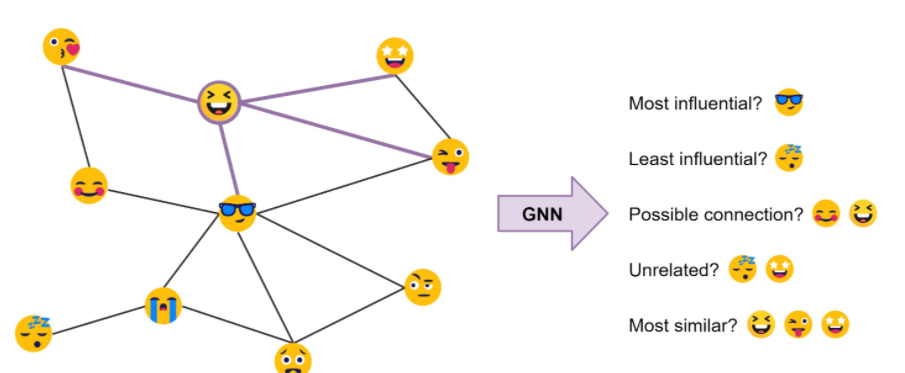
以这个表情符号社交网络为例:由GNN产生的节点特征可用于预测性任务,例如识别最有影响力的成员或提出潜在的联系。
在他们最基本的形式中,GNNs通过以下方法来更新节点i在ℓ层的隐藏层特征h(例如,😆),也就是先将节点自身的特征 h_i^l 和每个邻居节点 j∈N(i) 特征 h_j^l 的聚合相累加,然后再整体做一个非线性变换,如下:
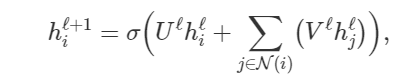
其中Ul,Vl是GNN层的可学习的权重矩阵,而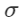 是一个非线性变换,例如ReLU。
是一个非线性变换,例如ReLU。
在上述例子中,N (😆) ={ 😘, 😎, 😜, 🤩 }。
邻域节点 j∈N(i) 上的求和可以被其他输入大小不变的聚合函数代替,例如简单的均值/最大值函数或其他更强大的函数(如通过注意机制的加权和)。
这听起来熟悉吗?
也许这样一条流程可以帮助建立连接:
如果我们要执行多个并行的邻域聚合头,并且用注意力机制(即加权和)替换领域上的求和 ,我们将获得图注意力网络(GAT)。加上归一化和前馈MLP,瞧,我们就有了Graph Transformer!
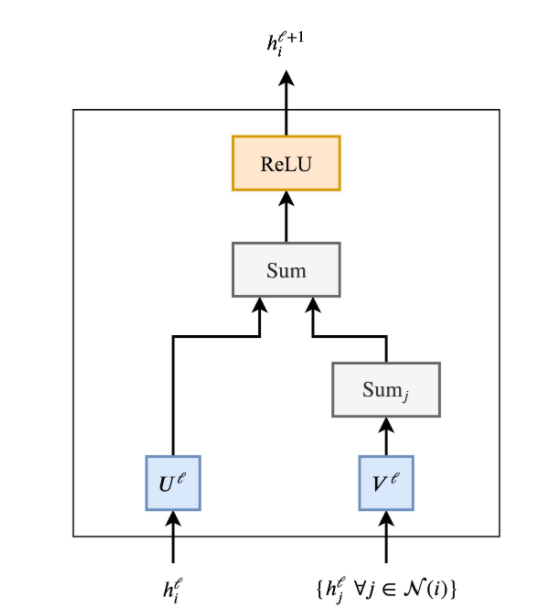
句子就是由词全连接而成的图
Sentences are fully-connected word graphs
为了使连接更加清晰,可以将一个句子看作一个完全连接的图,其中每个单词都连接到其他每个单词。现在,我们可以使用GNN来为图(句子)中的每个节点(单词)构建特征,然后我们可以使用它来执行NLP任务。
广义上来讲,这就是Transformers正在做的事情:Transformers是以多头注意力作为邻居聚合函数的GNNs(GNNs with multi-head attention as the neighbourhood aggregation function )。标准GNNs从其局部邻域节点j∈N(i) 聚合特征,而NLP的Transformers将整个句子视为局部邻域,在每个层聚合来自每个单词j∈S的特征。
重要的是,各种特定于问题的技巧(如位置编码、因果/掩码聚合、学习率表和大量的预训练)对于Transformers的成功至关重要,但在GNN界中却很少出现。同时,从GNN的角度看Transformers可以启发我们摆脱模型结构中的许多花哨的玩意。
可以从Transformers和GNN中学到什么?
现在我们已经在Transformers和GNN之间建立了联系,接着让我们来探讨一些新的问题...
全连接图是NLP的最佳输入格式吗?
在统计NLP和ML之前,Noam Chomsky等语言学家致力于发展语言结构的最新理论,如语法树/图。Tree LSTMs已经尝试过这一点,但是也许Transformers/GNNs是可以让语言理论和统计NLP的领域结合得更加紧密的更好的架构?
如何学习到长期依赖?
完全连通图使得学习词与词之间的非常长期的依赖关系变得非常困难,这是完全连通图的另一个问题。这仅仅是因为图中的边数与节点数成二次平方关系,即在n个单词的句子中,Transformer/GNN将在n^2对单词上进行计算。如果n很大,那将会是一个非常棘手的问题。
NLP界对长序列和依赖性问题的看法很有意思:例如,使注意力机制在输入大小方面稀疏或自适应,在每一层中添加递归或压缩,以及使用对局部性敏感的哈希法进行有效的注意,这些都是优化Transformers有希望的新想法。
有趣的是,还可以看到一些GNN界的想法被混入其中,例如,用于句子图稀疏化的二进制分区似乎是另一种令人兴奋的方法。
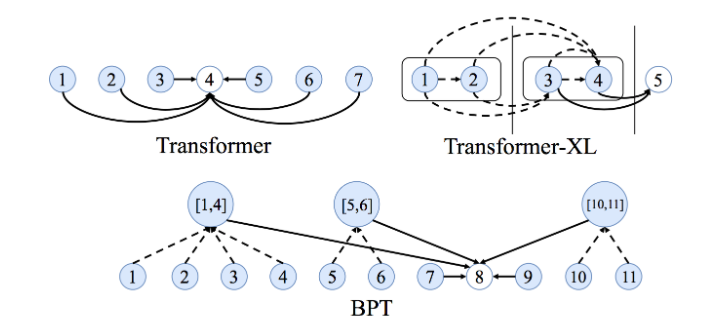
Transformers在学习神经网络的句法吗?
NLP界有几篇关于Transformers可能学到什么的有趣论文。其基本前提是,对句子中的所有词对使用注意力机制(目的是确定哪些词对最有趣),可以让Transformers学习特定任务句法之类的东西。
多头注意力中的不同头也可能“关注”不同的句法属性。
从图的角度来看,通过在完全图上使用GNN,我们能否从GNN在每一层执行邻域聚合的方法中恢复最重要的边线及其可能带来的影响?我还不太相信这种观点。
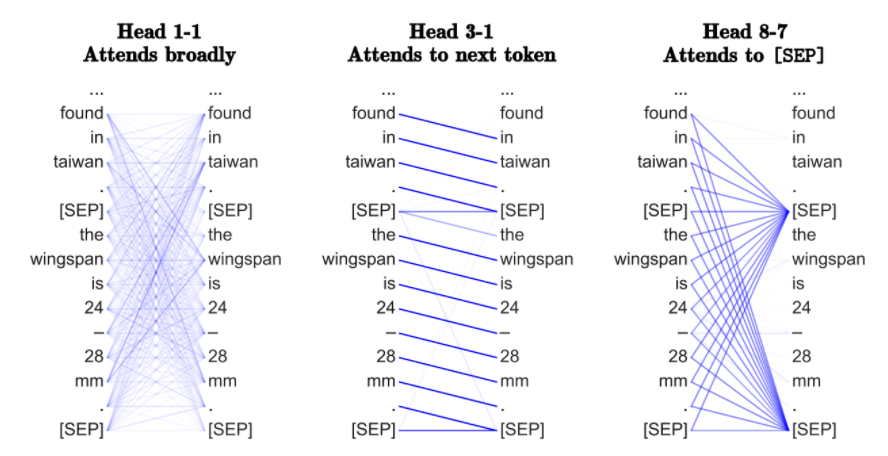
为什么要用多头注意力?为什么要用注意力机制?
我更赞同多头机制的优化观点——拥有多个注意力可以改进学习,克服不好的随机初始化。例如,这些论文表明,Transformers头可以在训练后“修剪”或“删除”,并且不会产生重大的性能影响。
多头邻聚合机制在GNNs中也被证明是有效的,例如在GAT使用相同的多头注意力,MoNet使用多个高斯核来聚合特征。虽然多头技巧是为了稳定注意力机制而发明的,但它能否成为提炼出额外模型性能的标准?
相反,具有简单聚合函数(如sum或max)的GNNs不需要多个聚合头来维持稳定的训练。如果我们不需要计算句子中每个词对之间的成对兼容性,对Transformers来说不是很好吗?
Transformers能从抛弃注意力中获益吗?Yann Dauphin和合作者最近的工作提出了另一种ConvNet架构。Transformers也可能最终会做一些类似于ConvNets的事情。
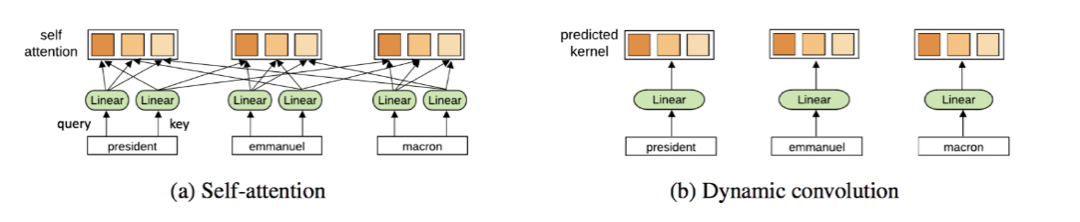
为什么Transformers这么难训练?
阅读新的Transformer论文让我觉得,在确定最佳学习率表、预热策略和衰减设置时,训练这些模型需要一些类似于黑魔法的东西。这可能仅仅是因为模型太大,而且所研究的NLP任务非常具有挑战性。
但是最近的结果表明,这也可能是由于结构中归一化和残差连接的特定组合导致的。
在这一点上我很在意,但是也让我感到怀疑:我们真的需要代价昂贵的成对的多头注意力结构,超参数化的MLP子层以及复杂的学习计划吗?
我们真的需要具有大量碳足迹的(译者注:有人提出现在训练一个模型相当于5辆汽车一天的排碳量)大规模模型吗?
具有良好归纳偏差的架构难道不容易训练吗?
参考
https://graphdeeplearning.github.io/post/transformers-are-gnns/
https://blog.csdn.net/dQCFKyQDXYm3F8rB0/article/details/104666156
总结如下
句子就是由词全连接而成的图
如果我们要执行多个并行的邻域聚合头,并且用注意力机制(即加权和)替换领域上的求和 ,我们将获得图注意力网络(GAT)。加上归一化和前馈MLP,瞧,我们就有了Graph Transformer!
Transformers是以多头注意力作为邻居聚合函数的GNNs(GNNs with multi-head attention as the neighbourhood aggregation function )。标准GNNs从其局部邻域节点j∈N(i) 聚合特征,而NLP的Transformers将整个句子视为局部邻域,在每个层聚合来自每个单词j∈S的特征。
