
NeurIPS 2020
code url (official tf) : https://github.com/yitu-opensource/ConvBert
背景
本文是国内的依图科技发表在NeurlPS 2020 上的一篇论文,今年的NeurlPS 2020 将在12月份温哥华举办,全球仅接受了1900篇论文,所以接受的论文很值得去阅读了。
本文是从模型基本的attention结构入手去改进BERT模型
本文的Abstract如下:

问题
BERT-family模型现在不断刷新NLP领域,但是BERT模型的基础attention块也严重依赖全局的自我注意力块,并且消耗大量的memory以及计算资源。
降低BERT对于计算资源的利用是目前研究的问题
解决
有很多工作从改进预训练任务或者利用知识蒸馏的方法优化模型的训练,但是少有改进attention模型结构(backbone architecture)的工作。
依图发现一些注意力头虽然是全局视角,但是只能关注到局部依赖,这样就存在一些计算冗余。
依图研发团队从这种模型结构本身的冗余出发,提出了一种基于跨度的动态卷积(span-based dynamic convolution)去代替一部分原有的attention去直接建模局部依赖。 (注意是一部分,而不是全部)
通过这种span-based dynamic convolution 和剩余的 self-attention heads 一起使得全局和局部学习更高效。
也就是将卷积整合到self-attention中去形成一个mixed attention mechanism ,以此来结合这二者的优势
贡献
提出了ConvBERT,通过全新的注意力模块,仅用 1/10 的训练时间和 1/6 的参数就获得了跟 BERT模型一样的精度。
具体如下:

模型
Self-attention & Dynamic convolution & Span-based dynamic convolution 的不同
其中可以认为attention weight = convolution kernel (都是代表的关联度的强弱)
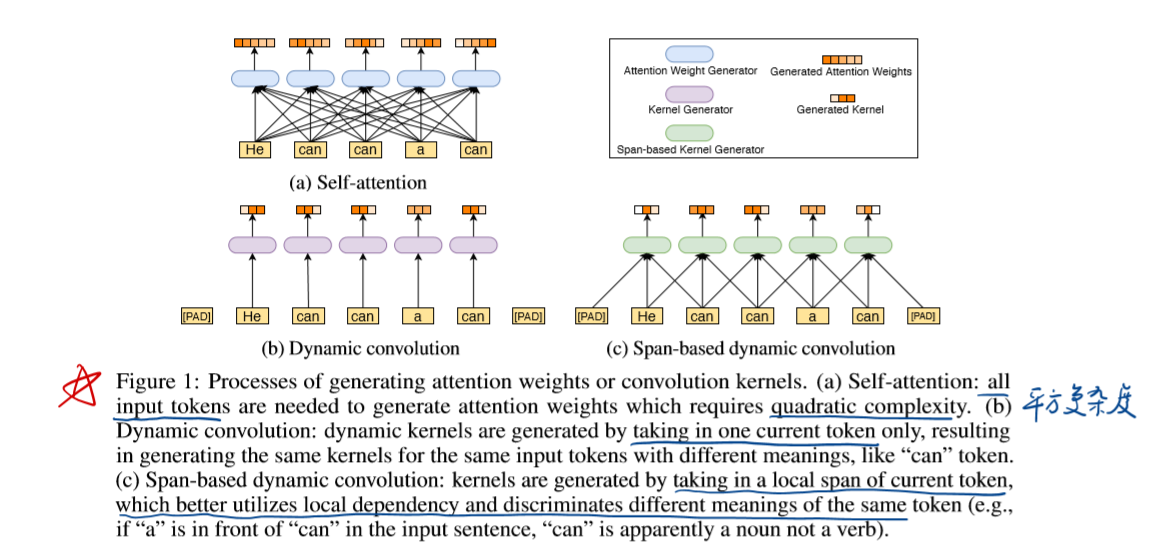
在前人的Dynamic convolution基础上,基于span改进得到了span-based dynamic convolution。不只是接受单一的token,而是接受一段token的span来产生更多的自适应的卷积核,这样可以解决Dynamic convolution存在的问题,可以达到使得不同上下文的同一个token能够产生不同的卷积核。具体如下:

bottleneck structure & grouped linear
除了对于最基本的attention结构进行改动之外,本文还在另外两处对BERT进行了修改,即bottleneck structure & grouped linear
bottleneck structure : 通过将输入token嵌入到低维空间中来减少不必要的head的数量 (降维来减少head),以此来减少冗余并且提高效率
grouped linear : 因为一般的前馈网络层(FFN)的维度会是输入输出维度的4倍,维度较高,这样就消耗了很多计算量,于是采用了groupedlinear operator 操作,在降低参数的同时也没有降低表示能力。
具体如下:

注:
感觉grouped linear 和reformer模型中的FFN层的分块类似
BERT和ConvBERT模型的attention map(attention map 可以理解成词与词之间的关系)的不同如下图所示。大多注意力主要集中在对角线,即主要学习到的是局部的注意力。这就意味着其中存在着冗余,也就是说很多 attention map 中远距离关系值是没有必要计算的。
ConvBERT的attention map不再过多关注局部的关系,这正是卷积模块减少冗余的作用体现

很多head是不必要存在的,于是采用卷积操作来捕获局部依赖。原文如下:

Light-weight & dynamic convolution
这两个模型都是Facebook AI Research发表在ICLR 2019上的论文中提出的,原文地址

模型基本如下:
先是引出了Light-weight convolution的运算操作:
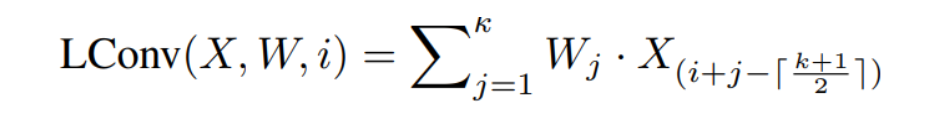
其中X∈R^n×d 为输入的特征,而W∈R^k 则是卷积核(相当于是加权),k 为卷积核的大小。轻量卷积的作用是将输入的每个词对应的特征附近的 k 个特征加权平均生成输出。
在此基础上,动态卷积(dynamic convolution )可以写作
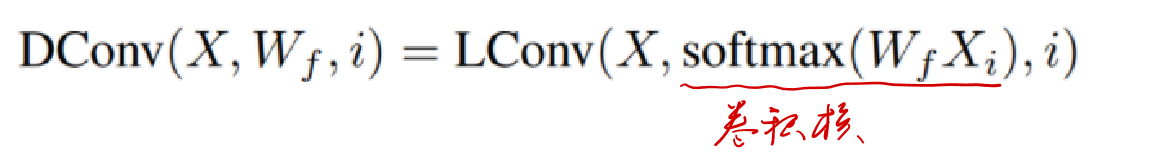
此处卷积核是由对应的词的特征经过线性变换和 softmax 之后产生的。
Span-based dynamic convolution
相比于动态卷积,Span-based dynamic convolution 依赖的不是单一的token,而是local context
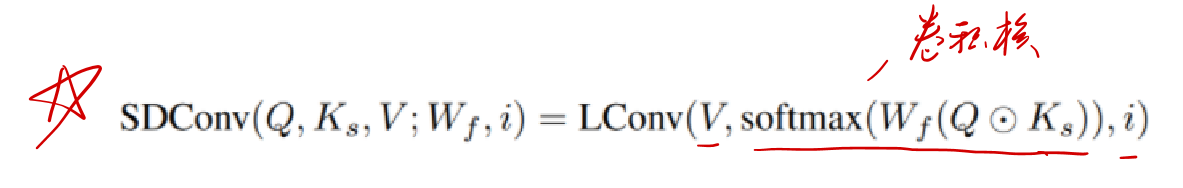
输入 X 先经过线性变换生成Q和V,同时经过卷积生成基于跨度的K_s,由Q⊙K_s经过线性变换以及softmax来产生卷积核与V进一步做轻量卷积,从而得到终的输出。
具体如下:

三者的不不同如下图
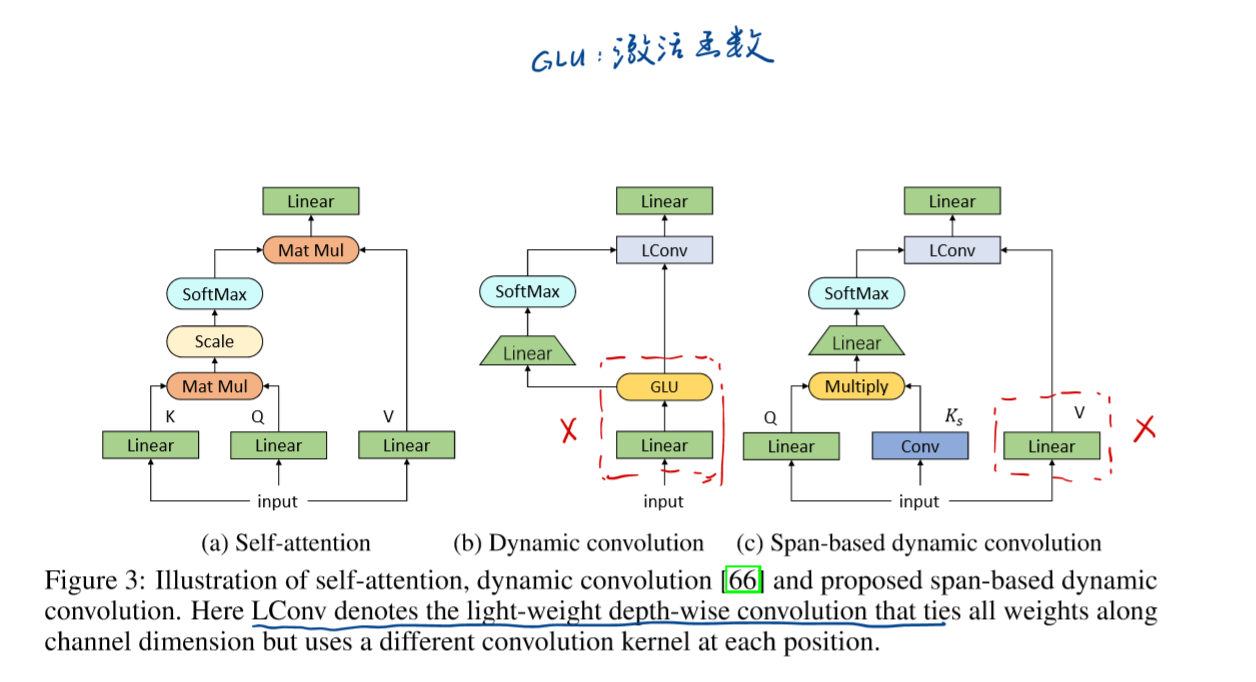
ConvBERT模型的总体架构
粉色背景的是span-based dynamic convolution。卷积和attention共享query但是有不同k,去分别生成attention map 和 convolution kernel (都是在softmax之后得到的),以此来关注局部和全局的依赖。
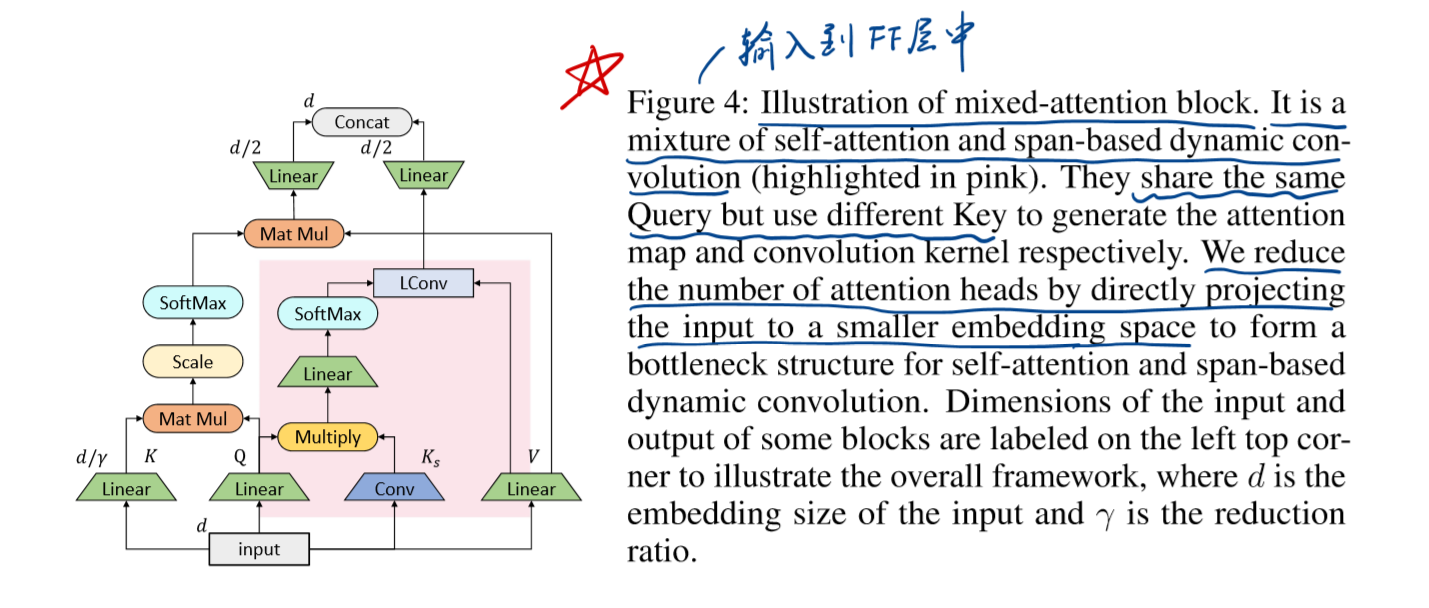
总体表示如下:

实验
本文做了挺多的实验,并且达到了SOTA水平
预训练数据集:OpenWebText
测试数据集: GLUE & SQuAD
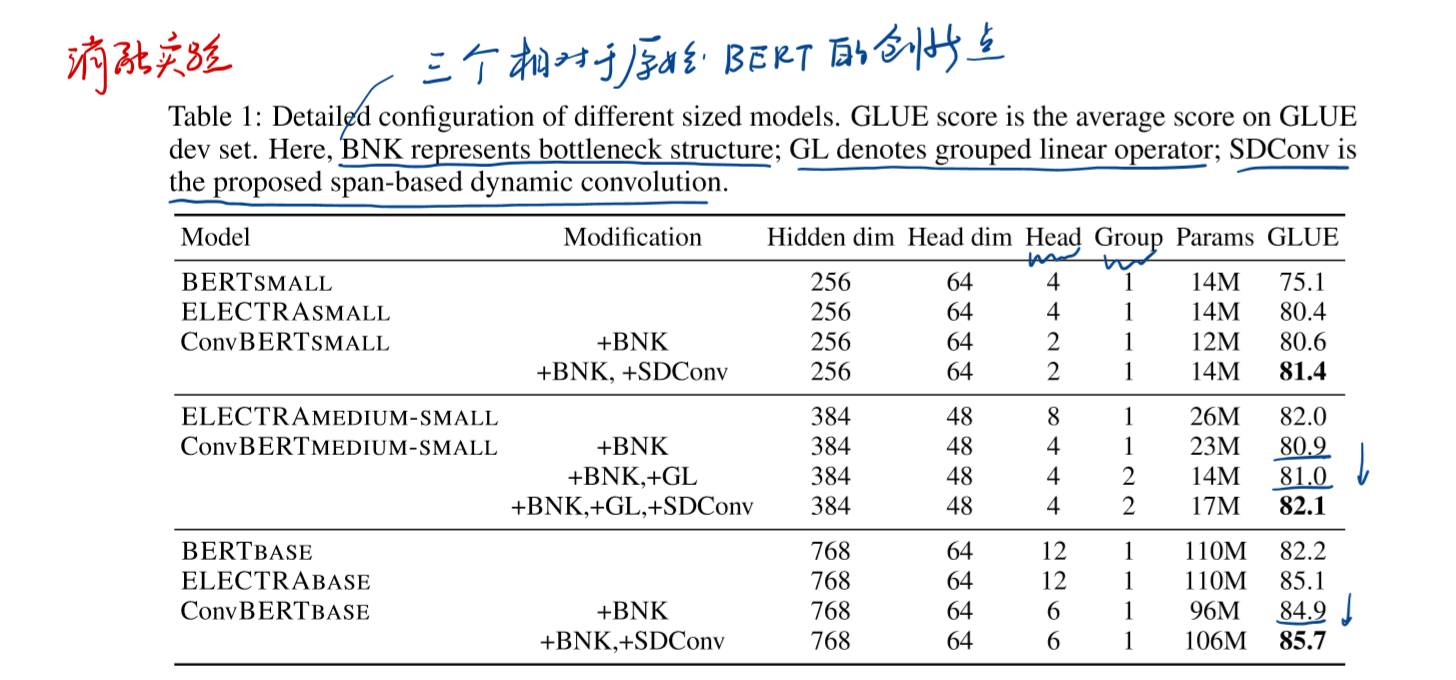
消融实验
- 本文对于attention的三个创新点进行消融,具体实验结果如下:
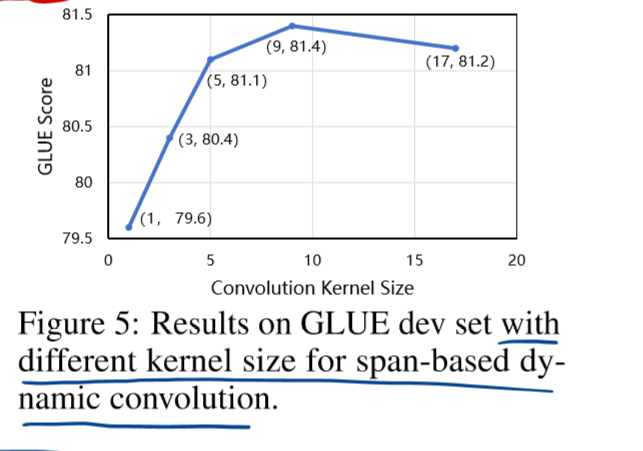
- 除此之外,本文还研究了核的大小对GLUE score的影响,当核大小=9时效果最好,本文的模型也采用了这种设计
本文将提出的Span-based Dynamic 与 经典的卷积进行对比实验,结果如下:
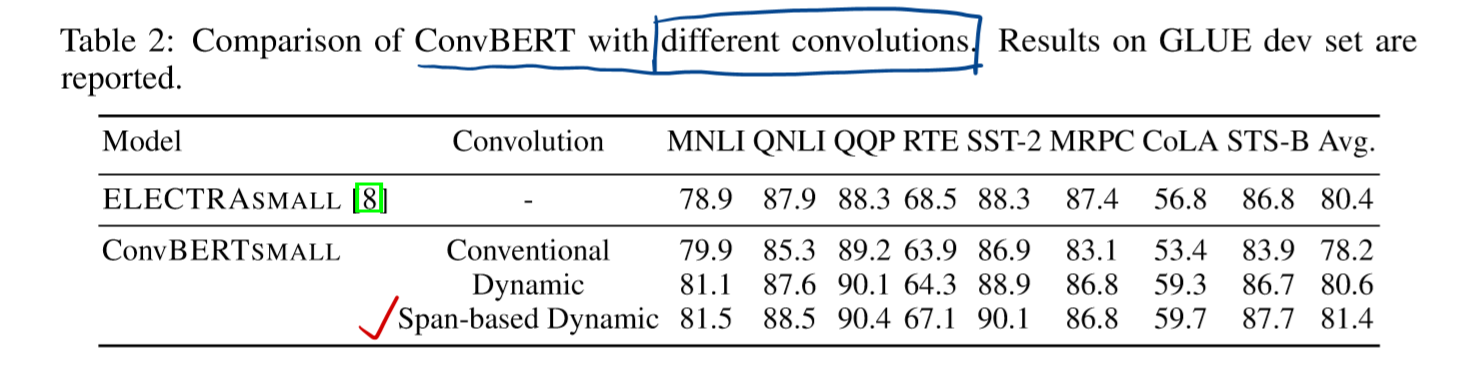
综合实验
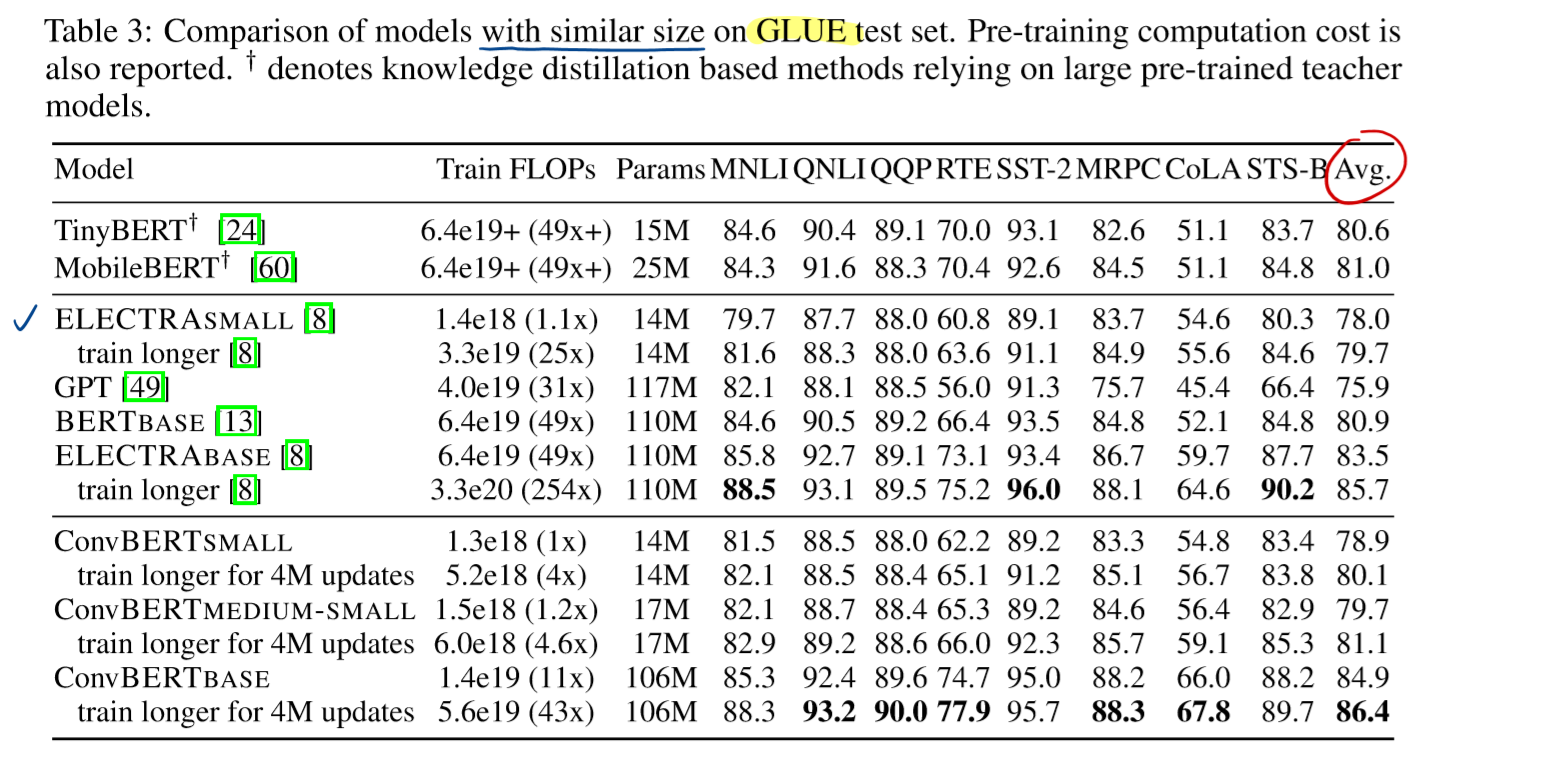
将ConvBERT和BERT还有ELECTRA在相似大小的情况下进行比较
在GLUE测试集上比较
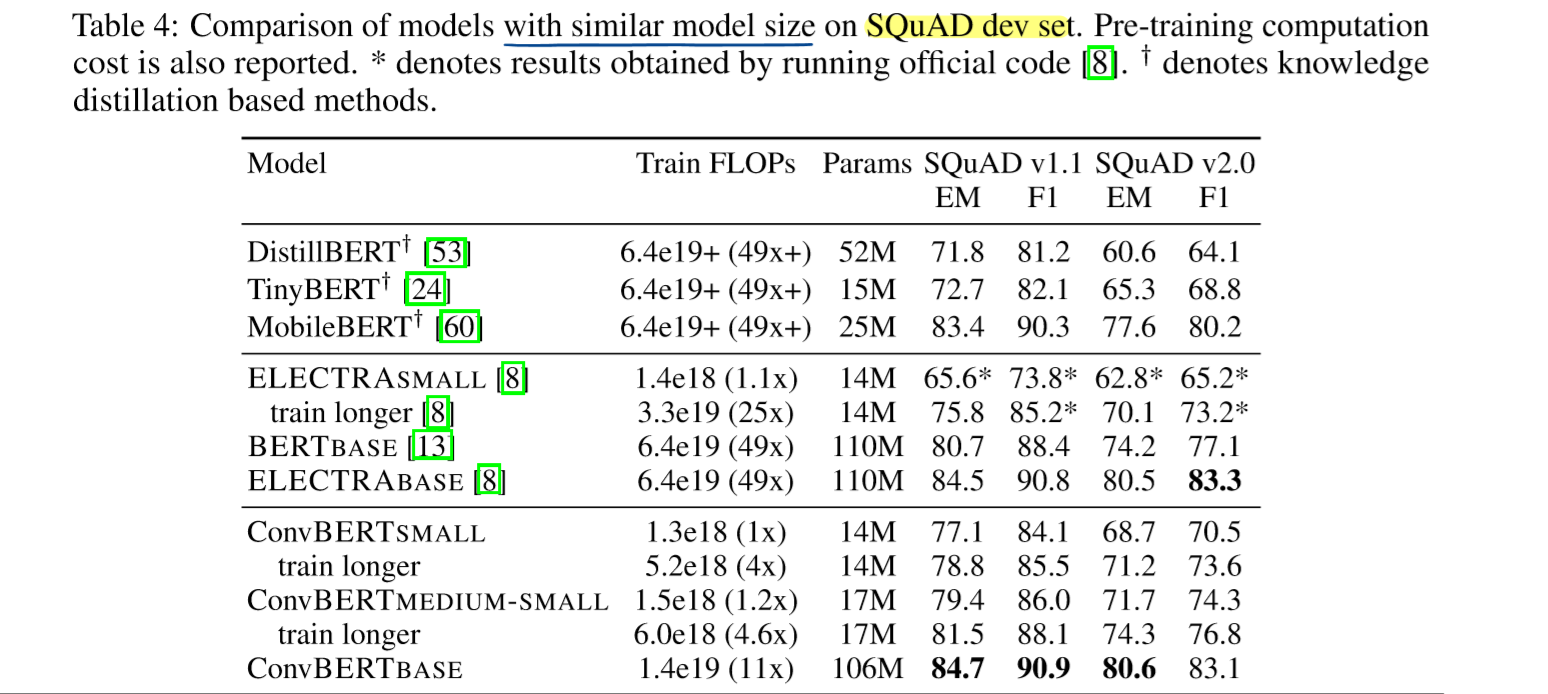
在SQuAD测试集上比较
总结
之前看过韩松实验室的Lite transformer模型,主要是对transformer模型的压缩。Lite transformer也是观察到transformer模型中的attention存在着冗余,于是也是提出了CNN结构结合self-attenion来一起学习全局和局部依赖。只是与本文不同的是,Lite transformer是通过将输入进行分流,一部分流入CNN块,来建模输入序列中的局部关系依赖,一部分流入self-attention块来迫使self-attention建模全局关系,以此减少了self-attention中的O(n2)复杂度,从而达到压缩的目的。
而本文是span-based dynamic convolution和self-attention的融合来改进attention机制,感觉是从根本上解决attention的固有缺点,并且效果也达到了SOTA水平,本文更优质一些
不过现在paper with code中除了官方给出的code,没有其他人贡献code,随着这篇论文被更多科研人员知道并使用改进,也会贡献更多的code吧,更希望hugging face 能够将本模型融入到github中,为NLP做出更多贡献
参考
自面世以来,Transformer 模型已经在多个领域取得了 SOTA 结果,包括自然语言处理、图像处理甚至是音乐处理。众所周知,Transformer 架构的核心是注意力模块,它计算输入序列中所有位置对的相似度得分。然而,随着输入序列长度的增加,注意力机制本身的问题也越来越突出,因为它需要二次方的计算时间来产生所有的相似度得分,用来存储这些得分的内存大小也是如此。
针对那些需要长距离注意力的应用,部分研究者已经提出了一些速度快、空间利用率高的方法,其中比较普遍的方法是稀疏注意力。
 标准的稀疏化技术。
标准的稀疏化技术。
然而,稀疏注意力方法也有一些局限。首先,它们需要高效的稀疏矩阵乘法运算,但这并不是所有加速器都能做到的;其次,它们通常不能为自己的表示能力提供严格的理论保证;再者,它们主要针对 Transformer 模型和生成预训练进行优化;最后,它们通常会堆更多的注意力层来补偿稀疏表示,这使其很难与其他预训练好的模型一起使用,需要重新训练,消耗大量能源。
此外,稀疏注意力机制通常不足以解决常规注意力方法应用时所面临的所有问题,如指针网络。还有一些运算是无法稀疏化的,比如常用的 softmax 运算。
为了解决这些问题,来自谷歌、剑桥大学、DeepMind、阿兰 · 图灵研究所的研究者提出了一种新的 Transformer 架构——Performer。它的注意力机制能够线性扩展,因此能够在处理长序列的同时缩短训练时间。这点在 ImageNet64 等图像数据集和 PG-19 文本数据集等序列的处理过程中都非常有用。

论文链接:https://arxiv.org/pdf/2009.14794.pdf
Performer 使用一个高效的(线性)广义注意力框架(generalized attention framework),允许基于不同相似性度量(核)的一类广泛的注意力机制。该框架通过谷歌的新算法 FAVOR+( Fast Attention Via Positive Orthogonal Random Features)来实现,后者能够提供注意力机制的可扩展低方差、无偏估计,这可以通过随机特征图分解(常规 softmax-attention)来表达。该方法在保持线性空间和时间复杂度的同时准确率也很有保证,也可以应用到独立的 softmax 运算。此外,该方法还可以和可逆层等其他技术进行互操作。
研究者表示,他们相信该研究为注意力、Transformer 架构和核方法提供了一种新的思维方式。
代码地址:https://github.com/google-research/google-research/tree/master/performer
论文公布之后,Youtube 知名深度学习频道 Yannic Kilcher 对该文章进行了解读。
广义的注意力机制
在以往的注意力机制中,分别对应矩阵行与列的 query 和 key 输入相乘,通过 softmax 计算形成一个注意力矩阵,以存储相似度系数。值得注意的是,这种方法不能将 query-key 生成结果传递给非线性 softmax 计算之后再将其分解为原始的 query 和 key。然而,将注意力矩阵分解为原始 query 和 key 的随机非线性函数的乘积是可以的,即所谓的随机特征(random feature),这样就可以更加高效地对相似度信息进行编码。

标准注意力矩阵包括每一对 entry 的相似度系数,由 query 和 key 上的 softmax 计算组成,表示为 q 和 k。
常规的 softmax 注意力可以看作是由指数函数和高斯投影定义的非线性函数的一个特例。在这里我们也可以反向推理,首先实现一些更广义的非线性函数,隐式定义 query-key 结果中其他类型的相似性度量或核函数。研究者基于早期的核方法(kernel method),将其定义为广义注意力(generalized attention)。尽管对于大多核函数来说,闭式解并不存在,但这一机制仍然可以应用,因为它并不依赖于闭式解。
该研究首次证明了,任意注意力矩阵都可以通过随机特征在下游 Transformer 应用中实现有效地近似。实现这一点的的新机制是使用正随机特征,即原始 query 和 key 的正直非线性函数,这对于避免训练过程中的不稳定性至关重要,并实现了对常规 softmax 注意力的更准确近似。
新算法 FAVOR+:通过矩阵相关性实现快速注意力
上文描述的分解允许我们以线性而非二次内存复杂度的方式存储隐式注意力矩阵。我们还可以通过分解获得一个线性时间注意力机制。虽然在分解注意力矩阵之后,原始注意力机制与具有值输入的存储注意力矩阵相乘以获得最终结果,我们可以重新排列矩阵乘法以近似常规注意力机制的结果,并且不需要显式地构建二次方大小的注意力矩阵。最终生成了新算法 FAVOR+。

左:标准注意力模块计算,其中通过执行带有矩阵 A 和值张量 V 的矩阵乘法来计算最终的预期结果;右:通过解耦低秩分解 A 中使用的矩阵 Q′和 K′以及按照虚线框中指示的顺序执行矩阵乘法,研究者获得了一个线性注意力矩阵,同时不用显式地构建 A 或其近似。
上述分析与双向注意力(即非因果注意力)相关,其中没有 past 和 future 的概念。对于输入序列中没有注意前后 token 的单向(即因果)注意力而言,研究者稍微修改方法以使用前缀和计算(prefix-sum computation),它们只存储矩阵计算的运行总数,而不存储显式的下三角常规注意力矩阵。
左:标准单向注意力需要 mask 注意力矩阵以获得其下三角部分;右:LHS 上的无偏近似可以通过前缀和获得,其中用于 key 和值向量的随机特征图的外积(outer-product)前缀和实现动态构建,并通过 query 随机特征向量进行左乘计算,以在最终矩阵中获得新行(new row)。
性能
研究者首先对 Performer 的空间和时间复杂度进行基准测试,结果表明,注意力的加速比和内存减少在实证的角度上近乎最优,也就是说,这非常接近在模型中根本不使用注意力机制的情况。

在以时间(T)和长度(L)为度量的双对数坐标轴中,常规 Transformer 模型的双向 timing。
研究者进一步证明,使用无偏 softmax 近似,该 Performer 模型在稍微进行微调之后可以向后兼容预训练 Transformer 模型,从而在提升推理速度的同时降低能耗,并且不需要从头训练预先存在的模型。

在 One Billion Word Benchmark (LM1B) 数据集上,研究者将原始预训练 Transformer 的权重迁移至 Performer 模型,使得初始非零准确度为 0.07(橙色虚线)。但在微调之后,Performer 的准确度在很少的梯度步数之后迅速恢复。
应用示例:蛋白质建模
蛋白质具有复杂的 3D 结构,是生命必不可少的拥有特定功能的大分子。和单词一样,蛋白质可以被看做线性序列,每个字符代表一种氨基酸。将 Transformers 应用于大型未标记的蛋白质序列语料库,生成的模型可用于精确预测折叠功能大分子。正如该研究理论结果所预测的那样,Performer-ReLU 在蛋白质序列数据建模方面表现良好,而 Performer-Softmax 与 Transformer 性能相媲美。

Performer 在蛋白质序列建模时的性能。
下面可视化一个蛋白质 Performer 模型,该模型使用基于 ReLU 的近似注意力机制进行训练。研究者发现,Performer 的密集注意力近似有可能捕捉到跨多个蛋白质序列的全局相互作用。作为概念的证明,研究者在串联蛋白长序列上训练模型,这使得常规的 Transformer 模型内存过载。但由于具有良好的空间利用效率,Performer 不会出现这一问题。

左:从注意力权重估计氨基酸相似性矩阵。该模型可以识别高度相似的氨基酸对,例如 (D,E) 和 (F,Y)。

Performer 和 Transformer 在长度为 8192 的蛋白质序列上的性能。
随着 Transformer 的频繁跨界,越来越多的研究者开始关注其内存占用和计算效率的问题,比如机器之心前段时间介绍的《抛弃注意力,比 EfficientNet 快 3.5 倍,类 Transformer 新模型跨界视觉任务实现新 SOTA》。在那篇文章中,研究者提出了一种名为「lambda」的层,这些层提供了一种捕获输入和一组结构化上下文元素之间长程交互的通用框架。类似的改进还在不断涌现,我们也将持续关注。
