虚拟环境配置
笔记本
| 名称 | 配置 | 用处 |
|---|---|---|
| sijian36 | tf 1.9.0 | 普通跑实验 |
| python714 | tf 1.14.0 | RKN |
| ronghe | tf 1.14.0 | transformer和RKN |
R740服务器
cuda-10.2
| 名称 | 配置 | 用处 |
|---|---|---|
| sijian1 | tf 1.13.0 | 一般实验 |
| pytorth030 | torch 0.3 | 哈佛torch版transformer |
| lsjRKN | tf 1.14.0 | RKN |
| ronghe | tf 1.14.0 | transformer和RKN |
| ronghe6 | tf-gpu1.14.0 | gpu加速融合 |
🚀日志
2020-09-06
主要内容
笔记本的RKN实验
跑通是在RKNmaster文件跑
哈佛torch版transformer实验
R740中 LSJ/annotated-transformer1/main5.py(pytorch030)
是之前上传到R740跑的实验
LSJ/annotated-transformer是前一阵为了将函数改成直通型流程而从笔记本上上传的
出现问题
在R740跑RKN实验
attributeerror: module 'tensorflow.keras.initializers' has no attribute 'normal' 解决
将RKN.py 77行 normal 改为 RandomNormal 还是出错
再次出错 keep.dim出错
修改 将keep.dim=True参数去掉 再运行
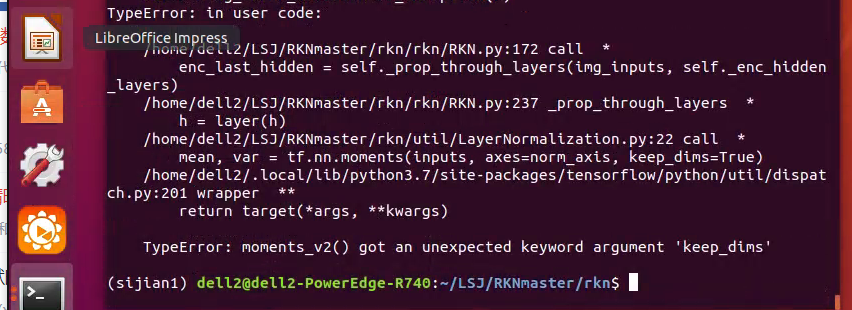
- 运行结果是没有tf.matrix_band_part 这个参数,于是百度发现,
- 新版本:tf.matrix_band_part变成tf.linalg.band_part 于是修改再运行
运行结果显示
于是百度,原因是
The image from your input pipeline is of type 'uint8', you need to type cast it to 'float32', You can do this after the image jpeg decoder:
以下更改,在RKN.py中插入h = tf.cast(h, tf.float32)
1 |
|
还是报错
放弃使用sijian1 以及刚刚对RKNmaser的修改
将笔记本中的RKNmaster 复制为rknmas上传到R740 名字为rknmas
参考了笔记本中的虚拟环境,在R740新建lsjRKN的虚拟环境,tf版本为1.14 python:3.6
可以跑通实验
实验可以在R740跑起来,但是为什么论文作者的github代码上tensorflow版本是1.13 不好使,但是在tensorflow1.14就可以跑起来????
在笔记本上跑的 设置epoch=5
2020-09-07
主要内容
配置transformer和RKN融合的实验虚拟环境 测试代码
下载的是Kyubyong/transformer 代码,准备融合RKN
具体的配置如下:
Requirements
- python==3.x (Let's move on to python 3 if you still use python 2)
- tensorflow==1.12.0
- numpy>=1.15.4
- sentencepiece==0.1.8
- tqdm>=4.28.1 #显示进度条的包
github下载代码,放到C:\Users\Administrator\PycharmProjects目录下,文件名为 transformer-master
python714是可以运行RKN的,在笔记本上,根据python714 clone了ronghe ,并添加所需要的包
1 | conda install tqdm |
出现问题
此代码不是官方代码,虽然可以实现transformer,但是使用的数据集是小型的IWSLT 2016 de-en,而不是transformer论文中使用的大型数据集WMT,但是官方代码又很难读,而且有很多用不到的接口
在纠结,要用目前的代码进行融合,还是用官方的代码呢?
问过师兄,现在还是不用官方的transformer代码,就用目前的代码,只是验证,不用管实验数据集,先将现在的代码结合RKN再说
2020-09-08
主要内容
阅读整理RKN的代码
将昨天的transformer数据集无法读取的问题解决
将RKN在R740上跑,并保存在test1.txt文件中,可以用less 查看
遇到问题
RKN代码读的一脸懵
transformer代码bug还未修复 😭
2020-09-09
主要内容
在R740新建环境ronghe,根据虚拟环境lsjRKN来建的
第三方包也安装成功
遇到问题
- 添加上encoding='ascii',error='ignore'就可以解决

注
在解决完之后,一定要看报错的位置,可能这个已解决,但是其它相同的问题不同位置也会报错,同样解决就可以了
- 在笔记本上跑此实验,发现内存不够,超出内容超过10%
Allocation of 1196032000 exceeds 10% of system memory
解决
减少banch_size , 但是还是超出,但是应该是在现有环境下实验可以跑通的,于是想着在R740上跑
在R740跑prepro.py实验,如下输出,并INFO:done (表示完成)
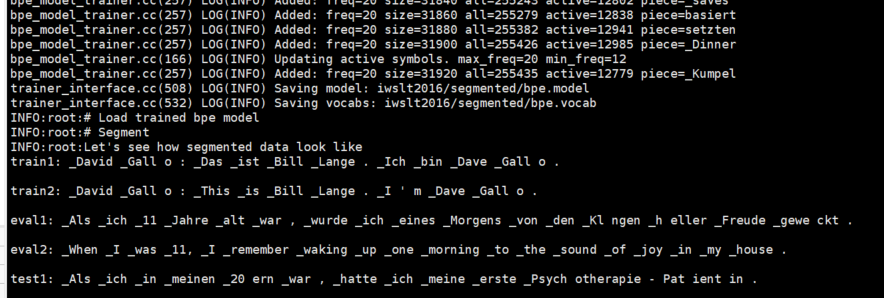
开始跑train.py 并将输出保存在train99.txt中(9月9日)
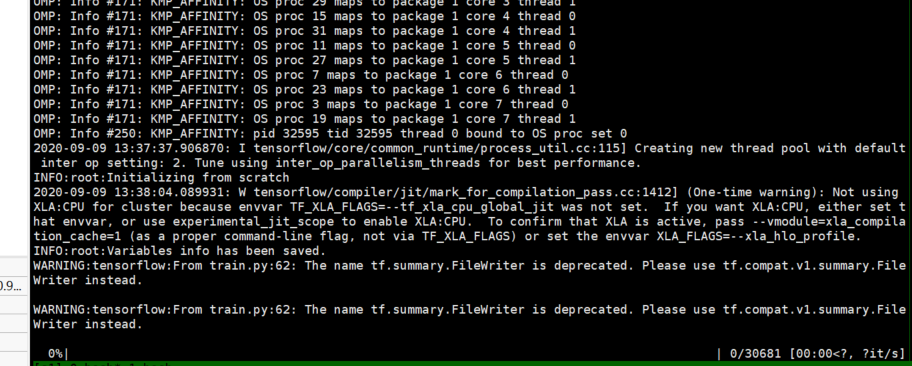
这个WARNING是什么意思呢?
猜想:源代码需要的是tf1.12版本 我配置的是tf 1.14版本,不知道是不是这个原因 。晚上回寝百度一下
- 在740中跑的太慢了,不知道具体原因。在看源代码进行修改
2020-09-10
主要内容
更改虚拟环境,可以使用GPU对实验进行加速
阅读transformer的代码,明天融合
对跑实验的一些warning都已经修改了,复制项目名字为transformer-mas
上传到R740中,命名transformer-mas
遇到问题

新建ronghe3虚拟环境
1 | conda install python==3.6.10 #这样可以 ,但是为什么 python==3.6.1 和 python==3.6.0 是不可以的呢?? |
在已经安装了tensorflow-gpu的ronghe3基础上,克隆了ronghe4,进行接下来的操作
注
如果执行conda install tensorflow==1.13.1
安装错误 ,导入不了tensorflow-gpu,应该是和CUDA版本不匹配
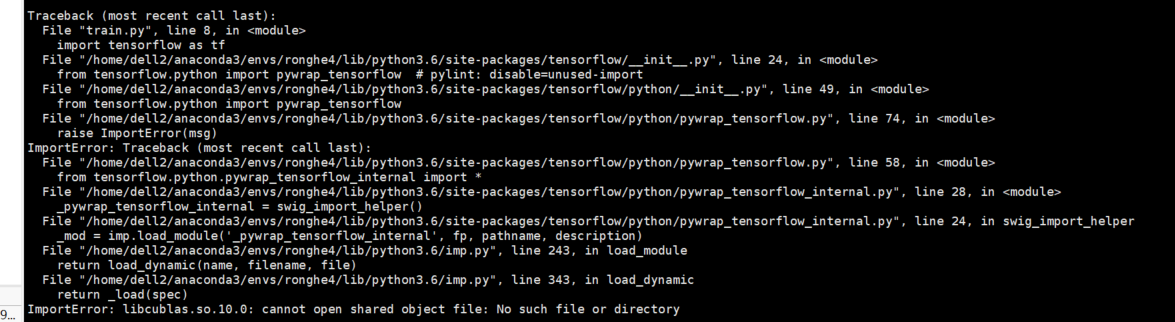
参考
ronghe5
pip install tensorflow-gpu==1.12.0
还是跑不通
ronghe6
1 | conda install python==3.6.10 #这样可以 ,但是为什么 python==3.6.1 和 python==3.6.0 是不可以的呢?? |
终于可以跑通了,不会报错了!!!
测试安装的tensorflow是否可用GPU,可以使用。测试如下:
1 | pyhton #进入python操作环境 |
RKN实验跑完了,保存在test2.txt中
tensorflow-gpu 1.5版本及以上要求CUDA版本为9.0
tensorflow-gpu 1.3及以上版本要求cudnn版本为V6及以上
2020-09-11
主要内容
解决在linux显示图形的问题
解决transformer实验报错
遇到问题
- 用xshell在服务器linux端只能显示控制台输出,如果想要显示图像,比如
matplotlib包,则要下载xmanage
由于需要收费,没有下载
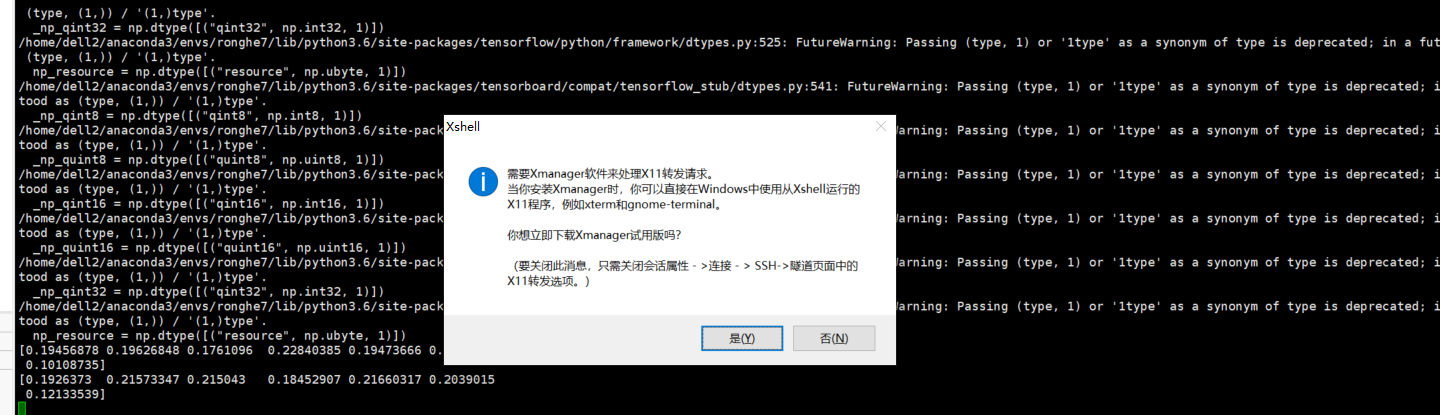
解决方法: 可以用plt.savafig保存到服务器,再保存在本地笔记本
1 | import matplotlib |
报错_tkinter.TclError: couldn't connect to display "localhost:32.0"
原因: 问题在于,您使用的是一个交互式后端,它试图为您创建图形窗口,但由于您断开了启动模拟时可用的x服务器,所以失败了。
解决方法:使用非交互式后端(请参见后端?)比如:Agg(用于Png格式,PDF, SVG或PS。在生成图形的脚本中,只需在import matplotlib.pyplot as plt之前调用matplotlib.use()即可
比如matplotlib.use('Agg')
在transformer实验中,才开始没注意,今天才发现有一个错误,如下:
1
AssertionError: Bad argument number for Name: 3, expecting 4
解决方法:因为对结果的影响不可观,所以就没去在意 ,后面发现用其他docker并没有多少问题,而且每次都出现一堆warning很影响美观性,于是百度准备解决这个问题
后来发现是有个gast的库版本太高,导致不兼容的问题,降级gast即可解决
使用pip进行降级
1 | pip install --user gast==0.2.2 |
待解决:
tensorflow的兼容性问题 cuda的兼容性问题 ??
一般如果要对服务器上的实验进行更改的话,怎能会简单一些??
2020-09-13
主要内容
解决transformer报错的问题
解决tensorflow目前不支持CUDA10.1的问题
修改:
将batch 由 128 改为 32
将maxlen1 和maxlen2 由100改为101
遇到问题
在运行transformer代码的时候,程序报错如下(部分内容,具体参考
train911.txt):1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27Traceback (most recent call last):
File "train.py", line 81, in <module>
hypotheses = get_hypotheses(num_eval_batches, num_eval_samples, sess, y_hat, m.idx2token)
File "/home/dell2/LSJ/transformer-master/utils.py", line 144, in get_hypotheses
h = sess.run(tensor)
File "/home/dell2/anaconda3/envs/ronghe6/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 950, in run
run_metadata_ptr)
File "/home/dell2/anaconda3/envs/ronghe6/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1173, in _run
feed_dict_tensor, options, run_metadata)
File "/home/dell2/anaconda3/envs/ronghe6/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1350, in _do_run
run_metadata)
File "/home/dell2/anaconda3/envs/ronghe6/lib/python3.6/site-packages/tensorflow/python/client/session.py", line 1370, in _do_call
raise type(e)(node_def, op, message)
tensorflow.python.framework.errors_impl.InvalidArgumentError: indices[111,100] = 100 is not in [0, 100)
[[node encoder_1/positional_encoding/embedding_lookup (defined at /home/dell2/LSJ/transformer-master/modules.py:290) ]]
Original stack trace for 'encoder_1/positional_encoding/embedding_lookup':
File "train.py", line 48, in <module>
y_hat, eval_summaries = m.eval(xs, ys)
File "/home/dell2/LSJ/transformer-master/model.py", line 176, in eval
memory, sents1, src_masks = self.encode(xs, False)
File "/home/dell2/LSJ/transformer-master/model.py", line 53, in encode
enc += positional_encoding(enc, self.hp.maxlen1)
File "/home/dell2/LSJ/transformer-master/modules.py", line 290, in positional_encoding
outputs = tf.nn.embedding_lookup(position_enc, position_ind)可以追溯到位置编码部分,出现了
InvalidArgumentError: indices[111,100] = 100 is not in [0, 100)的错误于是在我将超参数maxlen由100改为101,可以正常运行
参考
在rognhe6中安装的tensorflow-gpu:1.14是不支持CUDA10.1版本的,只支持到CUDA10.0版本。
1
2import tensorflow as tf
tf.test.is_gpu_available()输出如下:
1
2
3
4
5pciBusID: 0000:db:00.0
2020-09-13 09:32:43.541828: Could not dlopen library 'libcudart.so.10.0';
dlerror: libcudart.so.10.0: cannot open shared object file: No such file or directory;
False
可见是不支持目前ubuntu中的CUDA环境,参考了博客,修改如下:
将cudatoolkit=10.0安装到当前环境下
1 | conda install cudatoolkit=10.0 |
问题解决
参考
- 可以继续跑实验,可以用GPU,但是还是出现了一些问题
1 | Resource exhausted: OOM when allocating tensor with shape[1024,98,64] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc |
显示内存不够,于是我将batch_size从128改为32 ,可以正常运行了
或者可以考虑使用多个GPU呢?
参考
2020-09-13
transformer-mas训练部分已经跑了8个epoch,只用了一个GPU,跑的有点慢,于是暂停,以后再跑。
开始跑test.py文件,但是在跑的时候,TypeError: stat: path should be string, bytes, os.PathLike or integer, > not NoneType
路径写的不对,在ckpt中添加路径即可
2020-09-29
利用最新的ckpt进行测试,显示的是
想着可能最新的epoch的图和数据没有完全写入文件中,所以我在log/1文件夹中将最新的ckpt删除了,让次新的ckpt来进行测试。
发现结果还是unk ,不知道为什么? 是不是因为我一个epoch保存了多个ckpt
2020-09-30
今天的实验终于解决了,可以有好的结果了。这段时间真的太煎熬了。不过还是学到了不少东西。
之前修改的其它地方是没有问题的,不需要再变,是在epoch
计划以及疑问:
如何锁死进程, 多个的话,会显示显存不足
为什么必须要跑完才能显示结果呢? 在哪体现的呢
平时想要快速测试代码是否好用? 有什么办法
哪些人tensorflow用的好,以后经常请教
模型验证的作用是啥? 在代码中没有体现出来啊
总结遇到的困难以及学到的知识
解决onetab保存的标签
2020-11-20 OPTIMUS
这个模型的github上的代码让我很陌生,我之前没有接触过的东西,包括写的代码,主要是下面几点:
- 作者没有直接给出代码运行的配置环境,而是给出了运行环境所在的docker的镜像,需要下载镜像才能在镜像里才能运行环境,而且没法查看镜像中的具体环境配置 (为啥要这样 ?)
数据集有点大,11G的数据集,在电脑上很难下载,断网会断掉;在服务器上断点续传也会莫名其妙报错,最后直接花钱找人下载,保存到百度网盘后下载到电脑,再上传到服务器(挺快,2.5h左右)
- 代码中对于配置环境以及数据分词预处理涉及一些script脚本文件。虽然显得很规范,但是没必要。
代码很庞大,是我没有见过的庞大,所有的对比模型也在代码里。虽然是pytorch的,但是阅读起来还是有点困难,自己再边跑实验边理解吧。
操作过程:
下载docker镜像
想要使用docker,需要在服务器上安装docker 以及 docker-GPU,网上很多教程。安装成功之后,可以docker pull chunyl/pytorch-transformers:v2 。来下载到本地服务器中,然后就可以使用了。
注:
在执行docker时,如果报错显示命令被denied ,那么就在命令前加上
sudo来提高本次命令的操作权限。如果有多个命令都需要权限,那么输入命令
su,使得变成root用户,最高权限
运行镜像
下载完之后, 就可以运行了。一般直接 docker run image-name即可,但是本github上给出了一个脚本,切到目标文件夹,按照脚本来运行就可以了
1 | su #提高权限,提示符由$变成# |
具体操作如下:

接下来就可以进行数据预处理了,按照github上的操作即可(需在docker镜像下运行,不然会报错)
镜像运行之后,就相当于是在这个虚拟环境下进行操作了。
- 通过 docker inspect chunyl/pytorch-transformers:v2 , 可以在
ENV部分看到如下

那么就可以cd /miniconda/envs/py37 看具体的文件目录,和普通的anaconda目录没啥区别
- 如果想看具体安装了哪些包,那么就可以直接
conda list即可,和普通的操作没区别
具体安装环境的操作github中有介绍
https://github.com/ChunyuanLI/Optimus/blob/master/doc/env.md

数据预处理github:
https://github.com/ChunyuanLI/Optimus/blob/master/download_datasets.md
运行的是下面的脚本,实际上是初始化一些参数后调用python examples/big_ae/run_data_filtering.py
1 | sh scripts/scripts_local/run_data_filtering_wiki.sh |
因为数据集较大,数据处理的时间较长。
另:
其实在论文公开的github上操作写的很详细,但是因为之前没有过类似操作, 所以会忽略一些东西。
以后相关文档要好好认真看,避免出错!
是否可以暂时不用在这么大的数据集上跑模型,而是在一个小数据集上检验模型,这样在融合的时候也容易调试?

2020-12-22-TCVAE
调用gensim模块错误:cannot import name 'open' from 'smart-open'
原因: smart-open的版本不对,考虑升级版本
问题本质原因是因为smart_open模块版本不对,我出现该问题时smart_open=1.8.0,之后升级到1.9.0即可 看下自己的版本号
1 | conda list smart #版本1.8.0 |
完成升级,可以正常运行了
🚀讨论
2020.10.16
1.transformer和图神经网络/图卷积网络的联系 2.传统方法处理小样本学习 论文 + 代码 3.目标检测和小样本学习的联系 论文+ 代码 4.根据读的上述论文,多跑小样本实验,了解基本思路框架逻辑 v
5.根据已经读过的论文,改进的transformer应用到图像处理中(transformer可以处理目标检测,那么也可以解决小样本学习),验证 6.将图像处理中flatten变换为1*1卷积 ,验证 7.transformer做时间序列聚类 ,验证
2020.10.23
任务(做完讨论): 1.阅读BERT论文+跑代码
- nlp领域的小样本学习研究情况
研究方向: 1.参考BERT,将transformer-XL 改为双向模型,结合小样本学习的思想,用于nlp任务
2.在transformer处理图像的DETR模型中,加入小样本框架(MAML等),用于目标检测。 参考论文《Frustratingly Simple Few-Shot Object Detection》
3.可以用transformer来替换传统小样本学习模型框架中的特征提取器 (relation network、Adaptive Subspace等模型)
其它:
- 将论文《Adaptive Subspaces for Few-Shot Learning》发给翟滨
2020.10.28
任务: 1. NLP + 小样本学习的论文详细阅读 ★ 2. 将BERT思想融合到transformer-XL代码中 ,处理transformer-XL模型的任务;熟练掌握这两个模型 ★
- 看GPT系列模型论文,要对transformer系列有清晰的认识
- 查找文本处理方面transformer系列最新的模型
- 查找基于对抗的文本处理模型
2020.11.6
任务: 1.将T-CVAE代码由tf改为torch版本,用于融合模型 ★ 2.看BERT模型和GPT系列模型的论文,数据流向以及最后的输出逻辑搞明白 ★ 3.GPT系列的模型是否可以去处理句子级别的自回归,关注相关论文 4.查找一些GAN处理文本生成任务的论文,参考思路,尝试融合BERT和GPT 5.查找GPT的压缩模型 6.继续看最新的论文,了解研究近况
方向: 1.将T-CVAE模型的思想融入到OPTIMUS模型中,在小样本框架下处理NLP任务 ★ 2.在GAN框架下,将BERT作为判别器,将GPT作为生成器来处理文本生成任务
其它: 每周二下午和周俊阳一起开会讨论
2020.11.10
任务: 1.将BERT小样本论文看完 ,之后讲 2.查找一些GAN处理文本生成任务的论文(对抗文本生成),参考思路,尝试融合BERT和GPT 3.将T-CVAE代码由tf改为torch版本,用于融合模型 ★ 4.继续看最新的论文,了解研究近况
方向: 1.将T-CVAE模型的思想融入到OPTIMUS模型中,在小样本框架下处理NLP任务 ★ 2.在GAN框架下,将BERT作为判别器,将GPT作为生成器来处理文本生成任务 3. 参考Litte transformer, 模型 Lite BERT 在小样本框架下处理图像检测问题
其它: 将transformer论文以及笔记发给周俊阳 下周暂停一周讨论
2020.12.1
任务: 多读论文!
1.查找目标检测在小样本框架下应用的论文发到群里。需要有pytorch代码,不在意方法,只是去参考如何将模型融入到小样本中 2.检索对抗目标检测关键词,查找筛选相关论文发到群里
3.T-CVAE论文发群里
4.将Efficient transformer综述发到群里 5.OPTIMUS代码阅读,周五讨论 6.查找GAN做语言处理的论文并阅读 7.多看自然语言处理的综述,大面积阅读transformer和BERT的论文2020年的论文,定期并向师兄汇报!!!
方向: 1.参考T-CVAE ,将VAE融入到DETR模型中, 再放到元学习框架中进行训练 2.OPTIMUS代码阅读后,融入到对抗框架中 3.对transformer-XL模型进行改进,但是不是简单的a+b形式。通过大量阅读论文来找到改进思路和方法 (备选) 4.将BERT作为GAN的判别器,将GPT-2作为GAN的生成器,构建模型 (备选)
2020.12.11
任务以及探索方向: 1.将scheduled sampling 策略应用到transformer中,解决自回归的问题(参考之前读过的论文) 2.秋哥的分布式强化学习的论文结合seqGAN,应用到文本处理中 3.DETR中的decoder建模成RL问题,生成长序列标注 4.GAN结合BERT和GPT模型 5.SENet的思想应用到transformer的multihead中 6.强化学习结合RNN如下图
2020.12.13
将论文《Fast Transformers with Clustered Attention》的聚类思想应用到lite transformer的CNN中
