前言
End-to-End Object Detection with Transformers
CVPR 2020
code url : https://github.com/facebookresearch/detr
简易 code:
https://colab.research.google.com/github/facebookresearch/detr/blob/colab/notebooks/detr_demo.ipynb
Abstract
我们把目标检测看做是一种set prediction的问题,我们的方法也直接移除了一些人工设计的组件,例如NMS和anchor的生成。
我们的框架DETR,由两个部分构成,一是set-based的全局loss,使用bipartite matching (二分匹配)生成唯一的预测,二是transformer的encoder-decoder 结构。
只需提供固定大小学习到的目标查询集合,DETR推理出目标与全局图像上下文,直接并行地预测出结果。新的模型非常简单,不需要特定的库来支持。DETR在coco数据集上有着可以和faster-rcnn媲美的准确率与效率。而且它也能完成全景分割的任务。
问题
目标检测的目标是预测一个bbox的集合和各个bbox的标签。目前的检测器不是直接预测一个目标的集合,而是使用替代的回归和分类去处理大量的propoasls、anchors或者window centers。
模型的效果会受到一系列问题的影响:后处理去消除大量重叠的预测、anchors的设计、怎么把target box与anchor关联起来。为了简化流程,我们提出一种直接set prediction的方式来消除这些替代的方法。
解决
将目标检测看做是一种set prediction(序列预测)的问题,我们的方法也直接移除了一些人工设计的组件,例如NMS和anchor的生成。
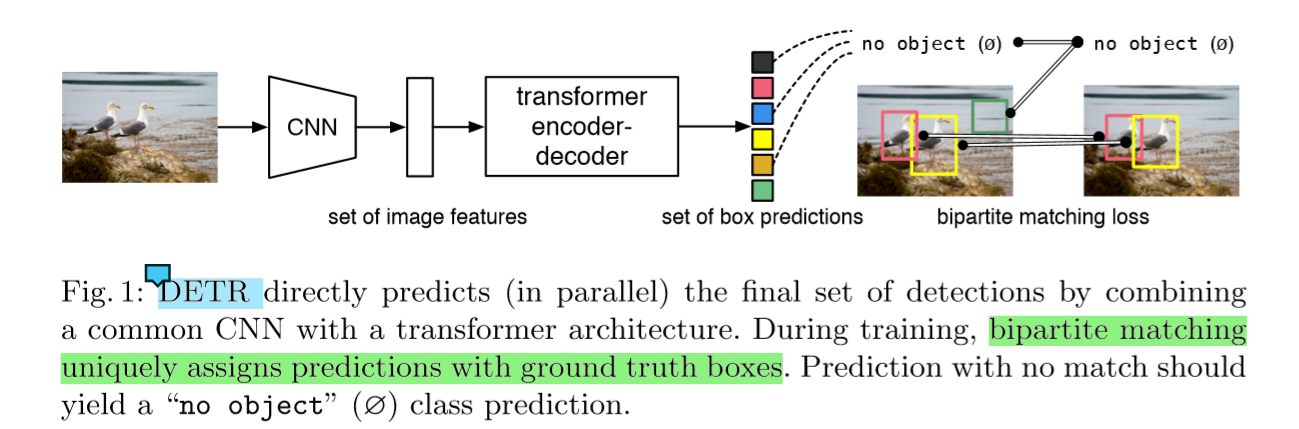
DETR模型的大体结构
DETR可一次预测所有对象,并通过设置损失函数进行端到端训练,该函数执行预测对象与真实对象之间的二分匹配。
与大多数现有的检测方法不同,DETR不需要任何自定义层,因此可以在任何包含标准CNN和transformer类的框架中轻松重现。
两大核心思想
1、transformer保证了attention,确保对一个实例的识别,是在整幅图的知识下进行的。
2、二分最大匹配,确保了一一对应的关系。
局限性
DETR在大型物体上表现出明显更好的性能,这可能是由于transformer的非局部计算所致。然而在小型物体上就表现出一般的性能
模型
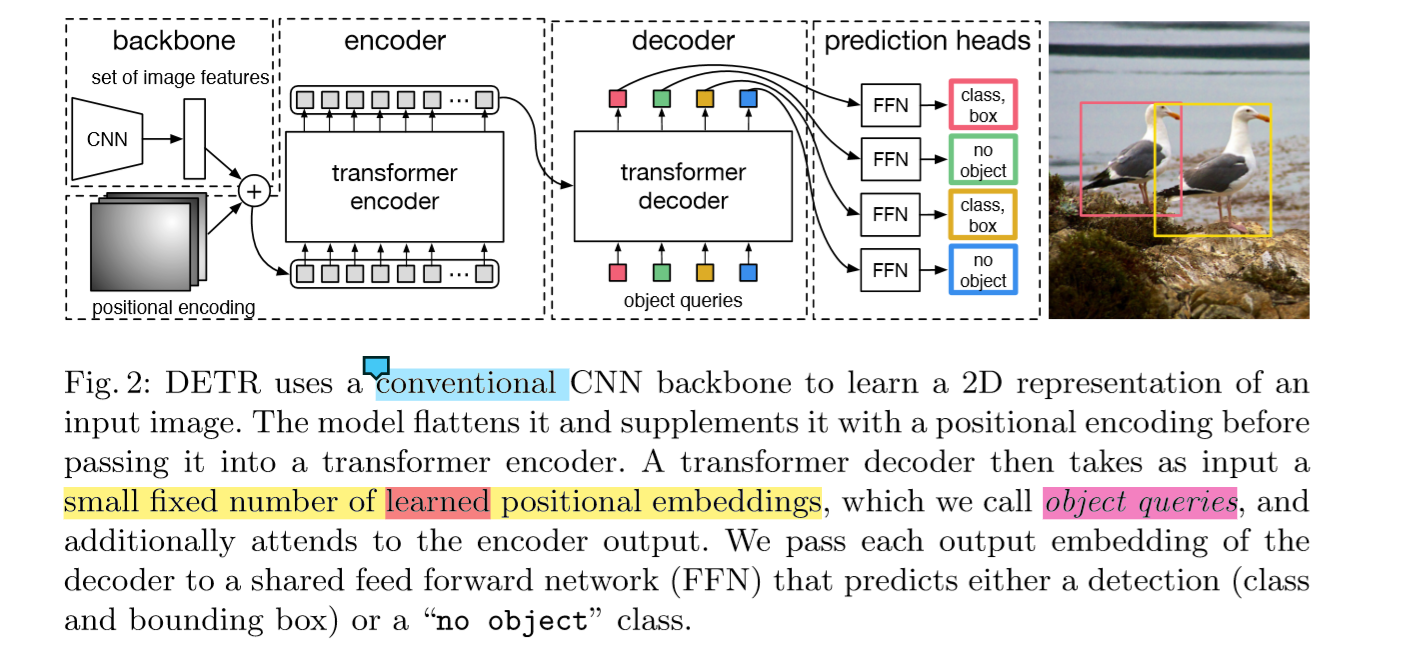
DETR的整体结构Transformer类似:Backbone得到的特征铺平,加上Position信息之后送到一Encoder里,得到上下文信息。这100个candidates是被Decoder并行解码的(显存就很大,但实现的时候可写成不并行的),以得到最后的检测框。
DETR Encoder
网络一开始是使用Backbone(比如ResNet)提取一些feature,然后降维到d×HW。

Feature降维之后与Spatial Positional Encoding相加,然后被送到Encoder里。
为了体现图像在x和y维度上的信息,作者的代码里分别计算了两个维度的Positional Encoding,然后Cat到一起。
1 | pos_x = torch.stack((pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4).flatten(3) |
FFN、LN等操作也与Transformer类似。Encoder最后得到的结果是对N个物体编码后的特征。
DETR Decoder
DETR Decoder的结构也与Transformer类似,区别在于Decoder并行解码N个object。
每个Decoder有两个输入:一路是Object Query(或者是上一个Decoder的输出),另一路是Encoder的结果。
We add prediction FFNs and Hungarian loss after each decoder layer. All predictions FFNs share their parameters。
在每一个decode层都会添加FFN和Hungarian loss,并行计算出N个object , FFN是共享参数的
object queries会输入到每一层中,我一开始不明白Object Query是怎样得到的。后来从代码看,Object Query是一组nn.Embedding的weight(就是一组学到的参数)。
最后一个Decoder后面接了两个FFN,分别预测检测框及其类别。
仔细看论文和代码,才发现它的输出是定长的(N):100个检测框和类别,这种操作可能跟COCO评测的时候取top 100的框有关。100比一个图像中普遍的目标数量都要多。
损失函数 - Bipartite Matching
一个难点就是如何去评价预测目标和真实目标(class 、边框大小位置)
由于输出物体的顺序不一定与ground truth的序列相同,作者使用二元匹配将GT框与预测框进行匹配。其匹配策略如下:
(y和y^都是N大小,用no object填充)

但是Lmatch中yi和y^的最佳分配需要用到匈牙利算法(Hungarian algorithm),参考的是前人的做法
匈牙利算法
寻找二分图的最大匹配
最后的损失函数:
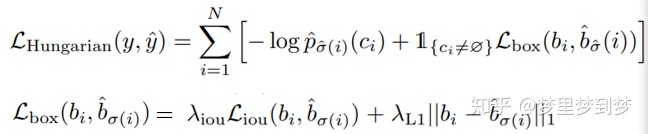
所谓二分的最大匹配,即保证预测值与真值实现最大的匹配,保证预测的N的实例(包括∅)按照位置与真值对应起来。实现一一对应之后,便能够利用分类Loss以及boundingbox Loss进行优化。这种一一对应的关系,同时也另一个好处是,不会多个预测值对应到同一个真实值上,然后再通过NMS进行后处理。

个人觉得最直白的理解方式就是用positional embedding替代了原本的anchor。
第一步用CNN提feature,然后展开成一维之后加上位置信息进入encoder加工。之后decoder里的object queries,实际上是另一组可学习的positional embedding,其功能类似于anchor。之后每个query进过decoder后算一个bbox和class prob。
网络的结构是非常简单的,先是CNN提取特征,然后将CNN提取的特征送入到transformer中,而由于transformer是位置无关,所以为了保持位置信息,需要送入CNN特征的同时,送入位置的编码信息,确保整个链路中位置信息不丢失。在transformer中编码之后,送入到解码器,同时送入到解码器的还包括object queries(即文中说的N个查询对象),N个对象以及编码器的输入在解码器的综合作用下,获取N个输出,这N个输出在FFN的作用下,产生N个位置以及每个位置对应的类别。
至此,网络的便具备物体检测的能力。与原始的transformer不同的地方在于decoder每一层都输出结果,计算loss。这种思想还是相对简单并且work的,EV-FlowNet以及龙明盛迁移学习的某一个版本中均有类似的操作。如果仔细探究的话,我想一定会有一种更合计的叠加方式,而不是这种简单的加在一起,毕竟每一层理论上的物理意义都不同,这种叠加loss的方法,限制了decoder只有第一层完成了大部分任务,更多的层只是一个上采样和细化的过程。
概括而言,文章的两大核心思想为:
1、transformer保证了attention,确保对一个实例的识别,是在整幅图的知识下进行的。注意力机制本质是在跑message passing去对提取的特征进行一种滤波,这里面在很大程度上就是实现了其他分析中的去提取不同位置不同物体之间的相互关系这个功能,通过发掘这个约束提高了对物体识别的可靠性。
2、二分最大匹配,确保了一一对应的关系。
二分图最大匹配问题与匈牙利算法的核心思想
https://liam.page/2016/04/03/Hungarian-algorithm-in-the-maximum-matching-problem-of-bigraph/
图上的object queries实际上是N个emebding,更具体得说应该是N个实例query的embedding(我理解是这样),退一步不准确一点可以简单理解成位置。N是固定值但是emebding完之后N个quries都不太一样。所以差不多的意思就是告诉模型要100个实例,然后decoder根据encoder得到特征的位置和显著性decoder出100个抽象点代表instance,其中部分是前景instance,部分是背景instance,前景的就class+box loss,背景的就当背景。这就是训练过程。推理过程也就很简单了,前景的就直接用,背景的就丢掉。
Transformer encoder: 注意力机制本质是在跑message passing去对提取的特征进行一种滤波,这里面在很大程度上就是实现了其他分析中的去提取不同位置不同物体之间的相互关系这个功能,通过发掘这个约束提高了对物体识别的可靠性。
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
ICLR 2021 under review
code url (非官方) : https://github.com/lucidrains/vit-pytorch
Abstract
patch: 图像块
尽管Transformer体系结构已成为自然语言处理任务的实际标准,但其在计算机视觉中的应用仍然受到限制。 在视觉领域,注意力要么与卷积网络一起应用,要么用于替换卷积网络的某些组件,同时将其整体结构保持在适当的位置。 我们表明,这种对CNN的依赖不是必需的,并且当直接应用于图像块序列时,纯transformer可以很好地执行图像分类任务。 当对大量数据进行预训练并转移到多个识别基准(ImageNet,CIFAR-100,VTAB等)时,与最先进的卷积网络相比,Vision Transformer可获得出色的结果,而在训练中所需更少的计算资源。
问题
在视觉领域中,transformer模型存在着对CNN的依赖,无法做到纯transformer模型。
解决
当直接应用于图像块(patch)序列时,纯transformer可以很好地执行图像分类任务。 对transformer进行尽可能少的修改,这样有利于以后模型的拓展。为此,我们将图像拆分为小块,并提供这些小块的线性嵌入序列作为transformer的输入。图像块与NLP中的token(单词)的处理方式相同,应用在图像分类中。
性能

在一些 mid-sized datasets 数据集(中型数据集)上表现一般,可能是transformer缺少CNN的归纳偏置特性。
然而在大型数据集中表现超过了CNN的归纳偏置。
模型
整体架构
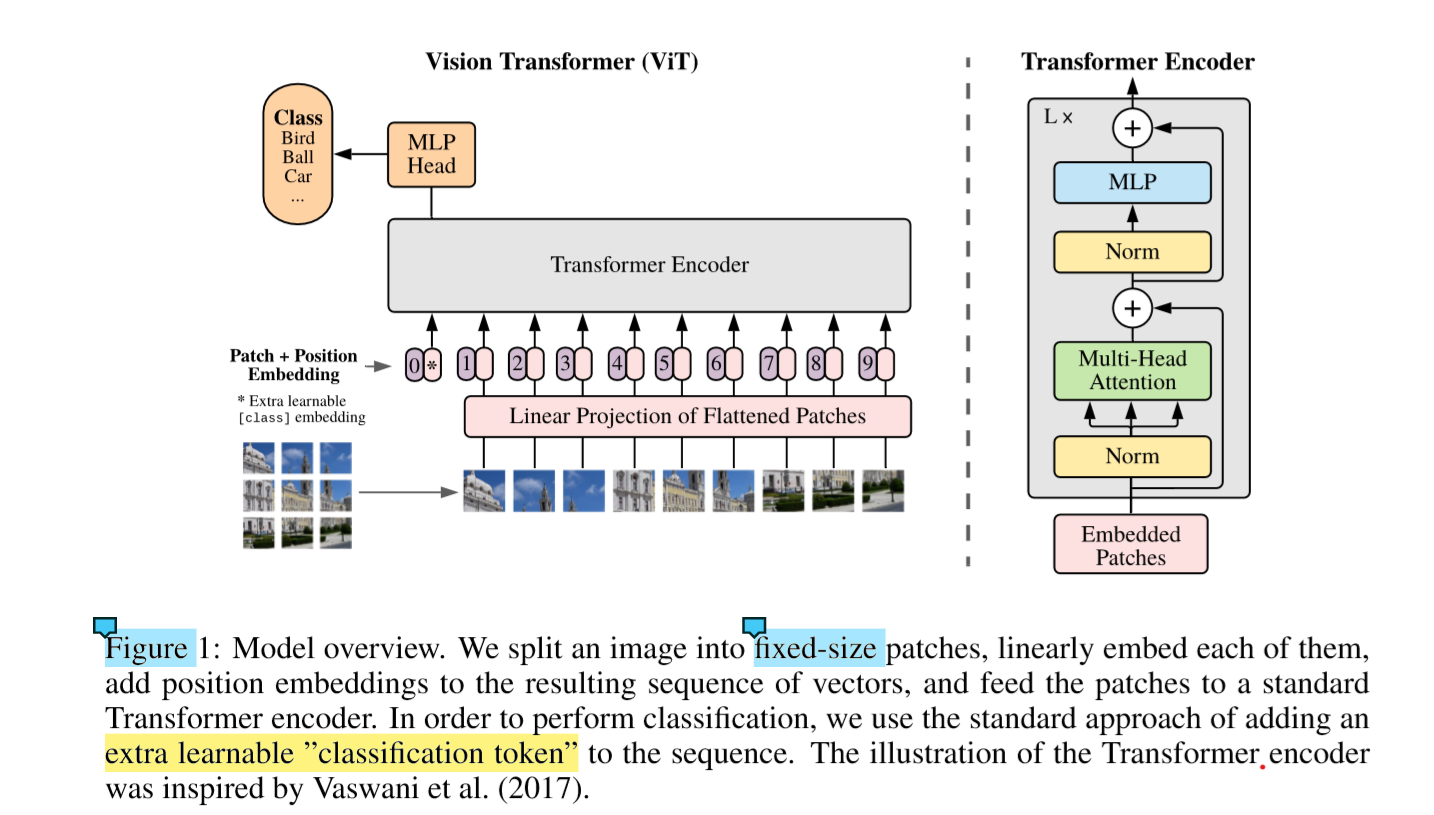
图像transformer遵循为NLP设计的体系结构。
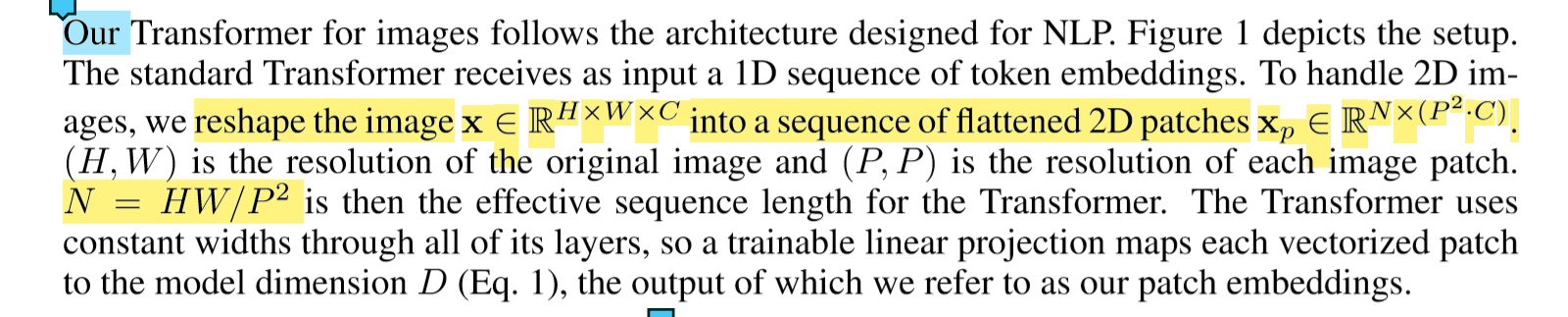
标准的Transformer接收一维token嵌入的序列作为输入。 为了处理2D图像,我们将图像x∈R H×W×C reshape为一系列flatten的2D的patch,xp∈R N×(P2·C)。
(H,W)是原始图像的分辨率,(P,P)是每个图像块的分辨率。 那么N = HW / P2是transformer的有效序列长度。
transformer在所有图层上使用恒定的宽度(d_model),因此可训练的线性投影将每个向量图形块映射到模型尺寸D,我们将其输出称为图像块嵌入(patch embedding)。
总体流程

位置嵌入: 没有使用行和列的位置嵌入(DETR),和token的位置嵌入一样
为什么位置向量是随机生成的,并进行优化的呢? 原transformer是计算得到的???


class embeding: 可学习的标签嵌入
预训练与微调
在实验阶段,在大型数据集上进行预训练,然后在较小的数据集上进行微调,作为tesk。
在微调时,去掉了pre-trained prediction head (Xclass),并将最后的num_classes改为数据集需要的类数目
