前言
本次阅读的论文是《Greedy Layerwise Learning Can Scale to ImageNet》,本周日论文分享组会中汇报
论文
《Greedy Layerwise Learning Can Scale to ImageNet》
ICML 2019
code url (pytorch) :https://github.com/eugenium/layerCNN
两年前的code了 ,最近一次提交也是一年前,更新了readme说明部分。但是为什么在论文中没有说明呢?
看了代码,发现好像没有什么特别之处,就是这样一个逻辑
背景
浅层监督的1隐藏层( 1-hidden layer )神经网络具有许多有利的属性,这些属性使它们比深层次的同类神经网络更易于解释,分析和优化,但缺乏表示能力。
深度神经网络(CNN)并不一定需要共同学习各个CNN层以获得高性能。
问题
同时多层网络较为复杂,尚不清楚各层如何协同工作以实现高精度的预测。
就计算和内存资源而言,端到端的反向传播效率可能较低。
解决
本文主要工作就是使用1隐藏层学习问题来逐层顺序构建深度网络,从而可以从浅层网络继承有利属性。
将上述这种greedy layerwise learning 拓展到了imagenet和CIFAR-10数据集等大型数据集上,应用场景是图像分类任务。
greedy approach 将更少地依赖于获得完整的梯度。不需要存储大多数中间激活,也不需要计算大多数中间梯度。 这样不需要很多的计算资源。本文就是解决将分层训练策略( layer-wise training strategies)应用到大规模数据集的问题
结果
使用一组简单的架构和培训构想,我们发现解决顺序出现的1隐藏层辅助问题会导致CNN超过ImageNet上的AlexNet性能。
背景知识
深层网络的贪婪逐层预训练方法(greedy layer-wise train)
每次只训练网络中的一层,即我们首先训练一个只含一个隐藏层的网络,仅当这层网络训练结束之后才开始训练一个有两个隐藏层的网络,以此类推。
在每一步中,我们把已经训练好的前k-1层固定,然后增加第k层(也就是将我们已经训练好的前k-1的输出作为输入)。每一层的训练可以是有监督的(例如,将每一步的分类误差作为目标函数),但更通常使用无监督方法(例如自动编码器)。
这些各层单独训练所得到的权重被用来初始化最终(或者说全部)的深度网络的权重,然后对整个网络进行“微调”(即把所有层放在一起来优化有标签训练集上的训练误差)。
考虑一个神经网络,如下图所示。它的输入是6维向量,输出是3维向量,代表输入样本属于三个类别的概率。
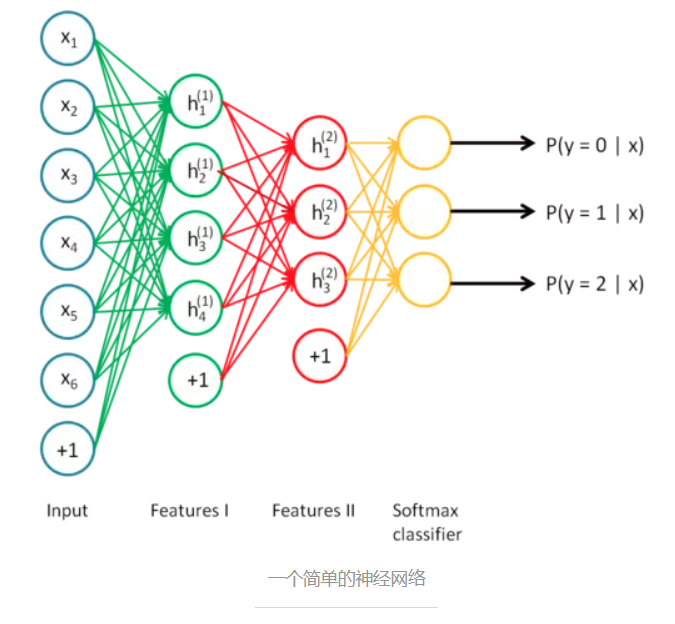
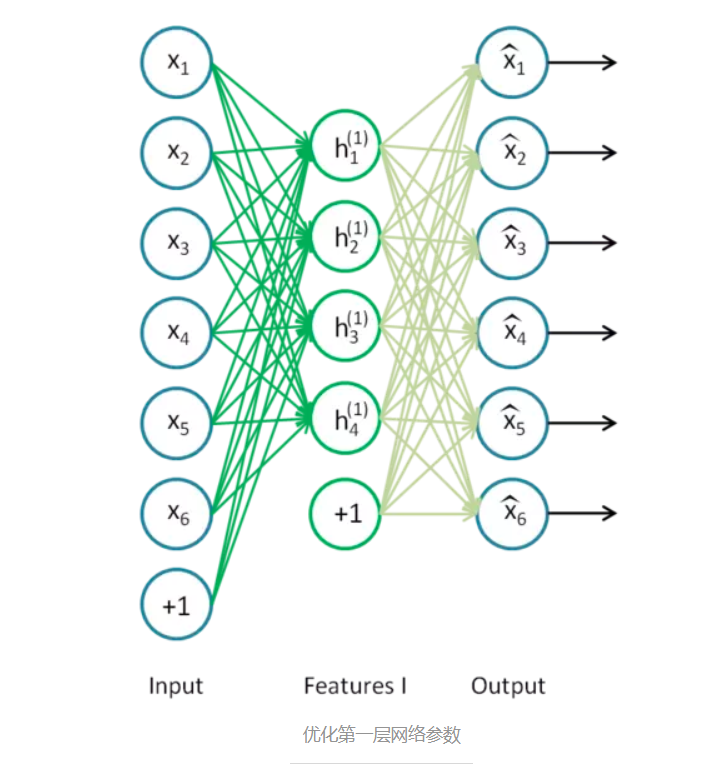
最开始我们通过高斯分布随机初始化网络参数,然后逐层地优化网络参数。首先第一层。如下图,我们只保留输入层Input和第一个隐藏层Features I,其余层去掉。
之后,加入一个输出层,该输出层的输出向量维度和输入层一样,从而构成一个自编码器。我们训练这个自编码器,便可以得到第一层的网络参数,即绿线部分。
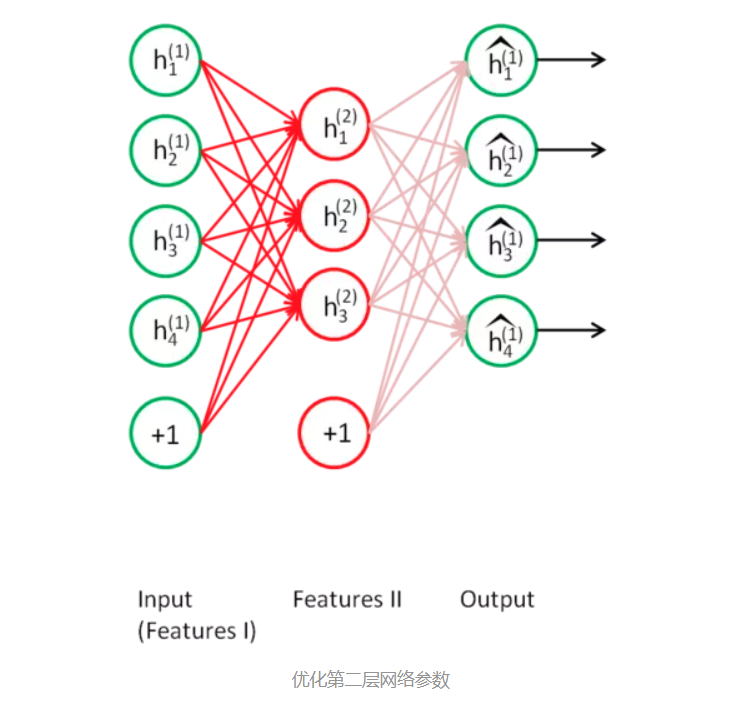
然后是第二层的网络参数。如下图,我们只保留原始神经网络中的第一个隐藏层和第二个隐藏层,其余层去掉。
之后添加一个输出层,其输出向量维度和第一个隐藏层维度一样,从而构成一个自编码器,自编码器的输入是第一个隐藏层。
优化这个自编码器,我们就可以得到第二层网络参数,即红线部分。
优化这两个自编码器的过程就是逐层贪婪预训练。由于每个自编码器都只是优化了一层隐藏层,所以每个隐藏层的参数都只是局部最优的。
优化完这两个自编码器之后,我们把优化后的网络参数作为神经网络的初始值,之后微调(fine tune)整个网络,直到网络收敛。
模型
模型架构
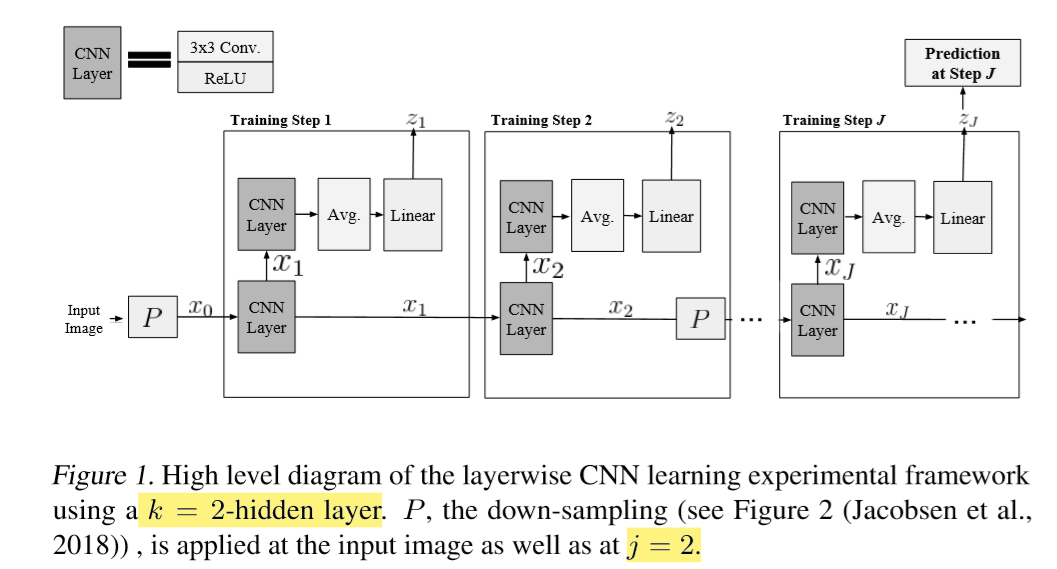

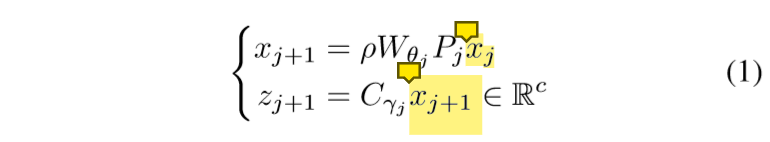
Xj+1 :先对上一次训练的结果进行下采样 ( invertible downsampling 可逆下采样操作),然后进行CNN , 再进行RELU函数
Zj+1 : 对Xj+1 进行辅助分类器操作得到,预测zj计算中间分类输出。

根据1式,xj已经经过了一层卷积,又W是从0开始的,所以下标只有k-2

损失函数
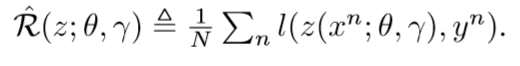
算法流程

