
ICLR 2021 (under review)
code url (official torch) : https://github.com/lucidrains/lambda-networks
code url (unofficial torch):https://github.com/leaderj1001/LambdaNetworks
背景
transformer的注意力机制在建模长依赖关系时有优势,但是同时也存在一定的缺点,就是需要去建立expensive attention maps (Q*K ) , 复杂度是O(n2),而且很消耗内存,这样就限制了transformer来处理更长的序列或者是多维的输入,比如图像。
问题
怎样去解决attention带来的资源的消耗以及无法处理多维度的结构化的上下文信息(图像)
解决
提出了 lambda layer,通过将上下文转化为线性函数(lambda)来捕获关联性,输入不同这些线性函数也是不同的,以此来避免了attention maps,这样可以应用到长序列或者高分辨率的图象上。
由多个lambda layer组成的神经网络叫做Lambda Networks ,并且认为lambda layer可以有效替代attention机制
优点: 计算简单且高效(small memory cost),且在流行数据集上表现不错

lambda layer 的大体介绍

模型
模型架构
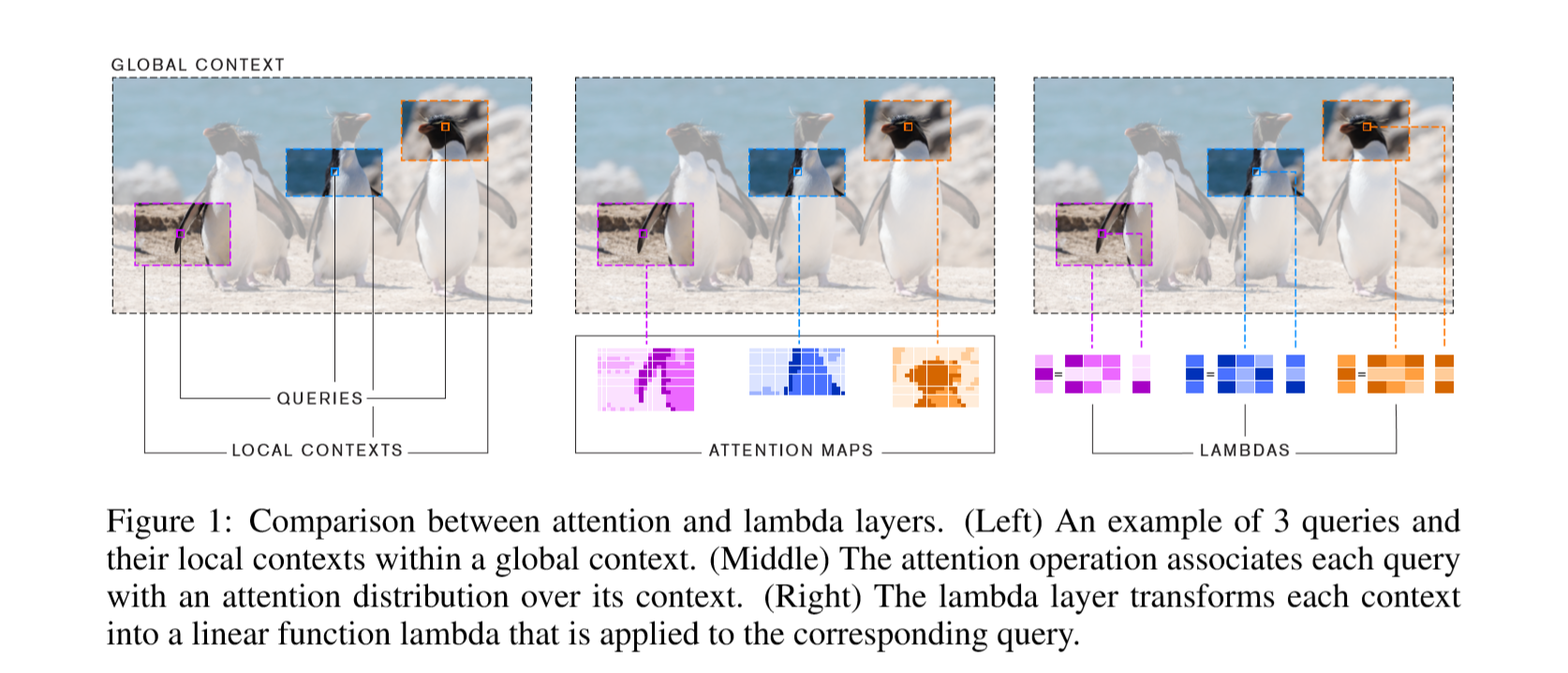
图中每个pixel(query)都可以类比于NLP中的一个token,要attention to local context (pixel 所在的框),如中间图所示,如果是attention机制,那么attent to每一个pixel,就会形成很大的attention map,而这只是一个pixel所形成的attention map ,当框在图像上滑动,计算每一个pixel的时候,内存消耗是巨大的。
图右采取的是 lambda函数的思想,也就是对于每一个pixel(query),都会计算一个线性的lambda函数,同时也是个矩阵,再和query相乘,就得到了此query对应的输出向量y。由于是线性的,所以消耗资源很少,可以处理高分辨率的图像
lambda layer 可以捕获全局的或者局部的关系

lambda network中对于各种参数的定义,基本和transformer一致
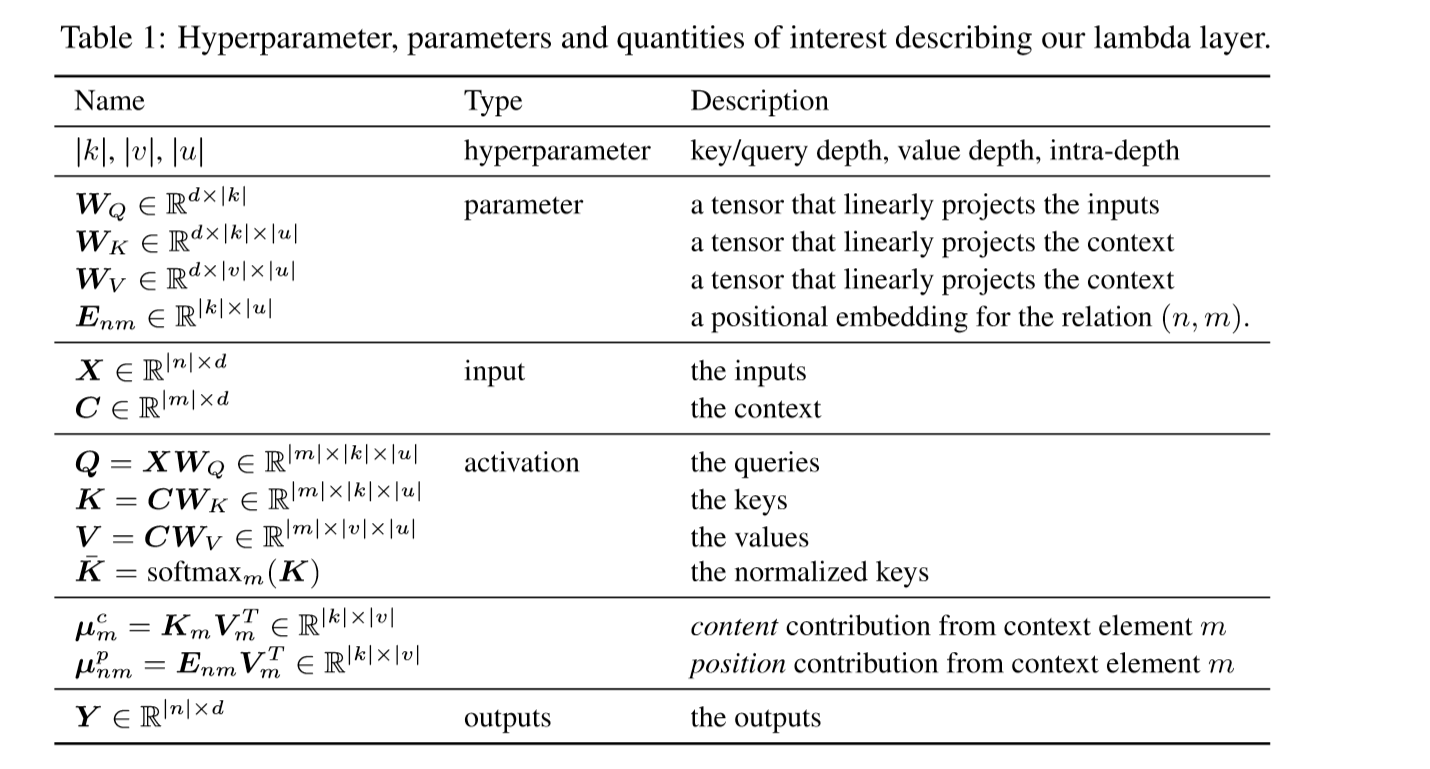
注:
C和X一般是一样的东西
n : local context pixels ( n = 225*225 )

lambda layer 主要数据流向:
input: X,C -> 生成线性函数,应用到对应的query中
output: Y
具体流程如下:
传统的self-attention
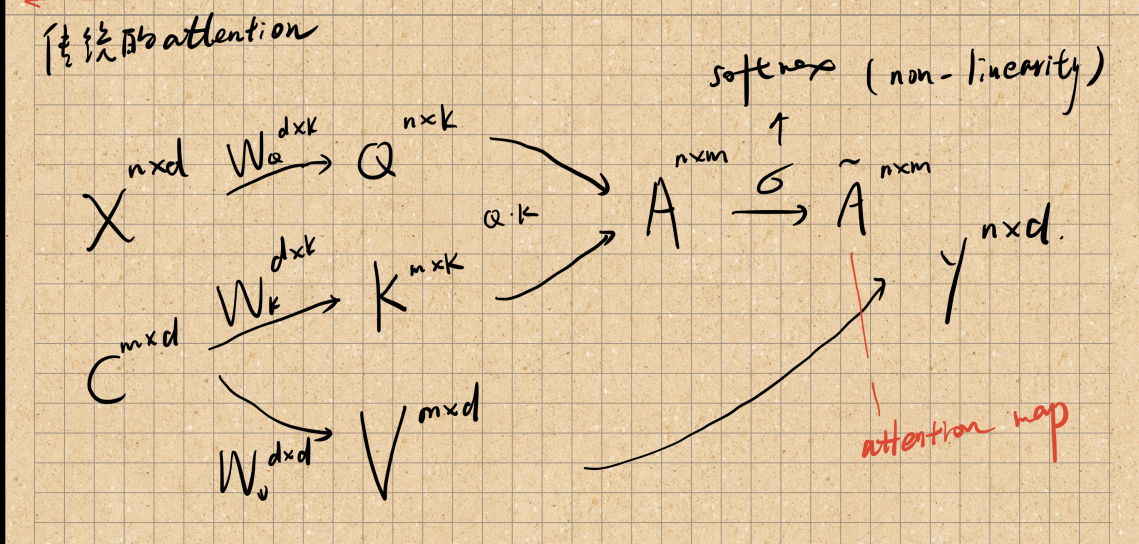
lambda network attention
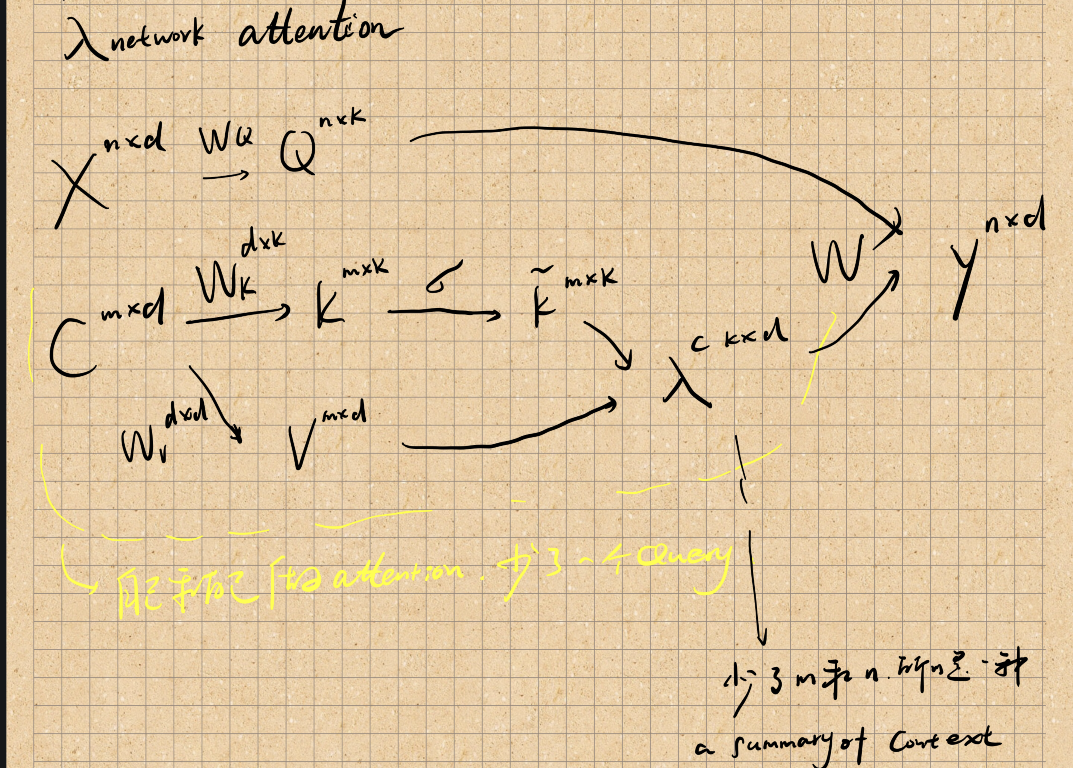
不太懂key和自己做attention有什么意义呢?
lambda layer 中涉及的公式

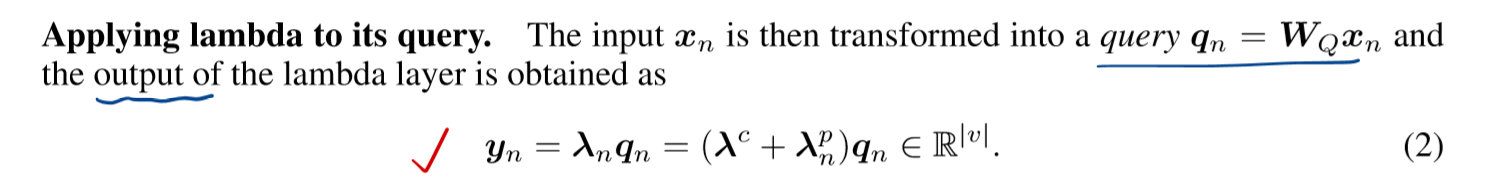
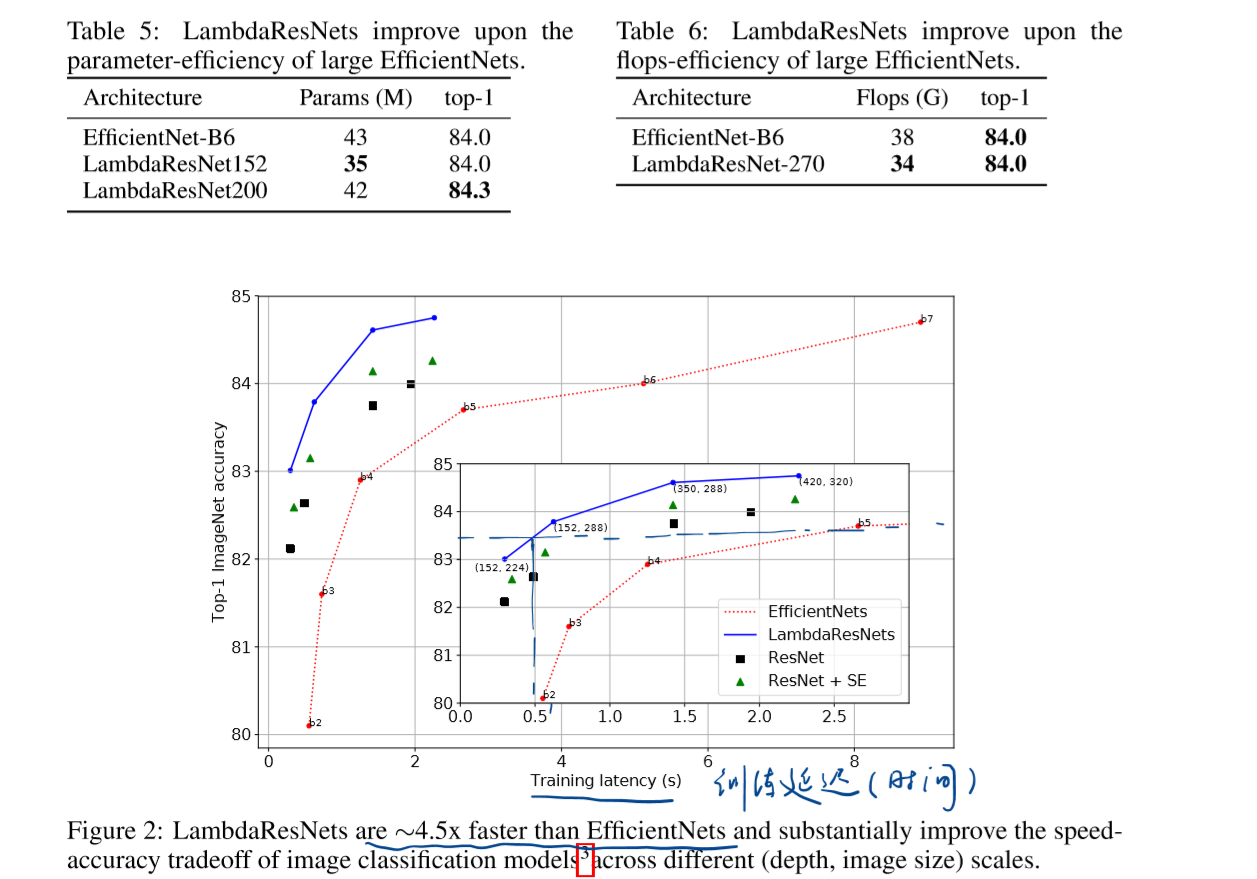
实验
代码
代码实际上实现的很简单,在官方给出的代码中只是写了lambda layer的实现,于是我又在paper with code上了另一个torch实现的模型代码(数据集用的是CIFAR10),实现的是Lambda ResNets。就是在ResNets的框架下,在每一层使用了lambda layer进行计算
代码中应用的einsum函数很简洁方便并且还高效,可以表示点积、外积、转置、矩阵-向量乘法、矩阵-矩阵乘法等一些常见的矩阵运算,推荐!
总结
感觉论文写的很不容易阅读,也算看过不少transformer的论文了,但是没有见过这篇论文这样的拗口的表达方式。明明很简单的概念,按照transformer类似表达就可以了,非要整出来一套奇怪的符号。作者是一个匿名作者,但是我估计可能是别的专业转行过来深度学习的
总体来说,这篇论文的写作和表达方式上对于后来的研究者来说很不友好!不过既然模型效果不错,那么在用attention处理图像问题的时候,可以考虑借鉴本文的思路
